library(tidyverse)
library(geojsonio)
library(SpatialPosition)
library(stargazer)
library(rprojroot)
library(kableExtra)
library(sf)
library(caret)
knitr::opts_chunk$set(include=TRUE, message=FALSE, warning=FALSE)
# This is the project path
path <- find_rstudio_root_file()Spatial interaction modelling
Resources
Some of the materials for this tutorial have been adapted from:
the Origin-destination data with stplanr manual,
the Modelling Population Flows Using Spatial Interaction Models tutorial, and
Current research
As an introduction, see here a recent research project we did, which used a form of spatial interaction modelling to predict interregional trade flow, using web data (Tranos, Carrascal-Incera, and Willis 2022).
Commuting data and networks
This the same data and the same data preparation we did for the network analysis practical. Please follow the below workflow, which you should already be familiar with. Once the data preperation is done, we will model these commuting flows.
For this tutorial we will use travel to work data from the 2011 UK Census. The data is available online, but it requires an academic login. After you log in, download the WU03UK element, save the .csv on your working directory under a /data directory and unzip it. We will use the:
Location of usual residence and place of work by method of travel to work
for
Census Merged local authority districts in England and Wales, Council areas in Scotland, Local government districts in Northern Ireland.
The below code loads the data.
path.data <- paste0(path, "/data/wu03uk_v3/wu03uk_v3.csv")
commuting <- read_csv(path.data)
commuting# A tibble: 110,162 × 14
`Area of usual residence` `Area of workplace` All categories: Method of tra…¹
<chr> <chr> <dbl>
1 95AA 95AA 9465
2 95AA 95BB 107
3 95AA 95CC 42
4 95AA 95DD 1485
5 95AA 95EE 35
6 95AA 95FF 18
7 95AA 95GG 4538
8 95AA 95HH 139
9 95AA 95II 282
10 95AA 95JJ 108
# ℹ 110,152 more rows
# ℹ abbreviated name: ¹`All categories: Method of travel to work`
# ℹ 11 more variables: `Work mainly at or from home` <dbl>,
# `Underground, metro, light rail, tram` <dbl>, Train <dbl>,
# `Bus, minibus or coach` <dbl>, Taxi <dbl>,
# `Motorcycle, scooter or moped` <dbl>, `Driving a car or van` <dbl>,
# `Passenger in a car or van` <dbl>, Bicycle <dbl>, `On foot` <dbl>, …You might have observe some weird codes (OD0000001, OD0000002, OD0000003 and OD0000004). With some simple Google searching we can find the 2011 Census Origin-Destination Data User Guide, which indicates that these codes do not refer to local authorities:
OD0000001 = Mainly work at or from home
OD0000002 = Offshore installation
OD0000003 = No fixed place
OD0000004 = Outside UK
For the sake of simplicity we will remove these non-geographical nodes.
non.la <- c("OD0000001", "OD0000002", "OD0000003", "OD0000004")
commuting <- commuting %>%
filter(!`Area of workplace` %in% non.la)check the %in% operator.
Now let’s do some clean-up of the commuting data frame. Let’s remind ourselves how the data look like
We are keeping the English and Wales local authorities by keeping the observations with a local authority code starting from E (for England) and W (for Wales).
commuting <- commuting %>% filter(startsWith(`Area of usual residence`, "E") |
startsWith(`Area of usual residence`, "W")) %>%
filter(startsWith(`Area of workplace`, "E") |
startsWith(`Area of workplace`, "W")) %>%
glimpse()Rows: 93,034
Columns: 14
$ `Area of usual residence` <chr> "E41000001", "E41000001", "…
$ `Area of workplace` <chr> "E41000001", "E41000002", "…
$ `All categories: Method of travel to work` <dbl> 20777, 1591, 534, 3865, 433…
$ `Work mainly at or from home` <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ `Underground, metro, light rail, tram` <dbl> 6, 1, 0, 1, 0, 0, 0, 0, 0, …
$ Train <dbl> 26, 32, 0, 49, 11, 0, 0, 0,…
$ `Bus, minibus or coach` <dbl> 1922, 140, 21, 167, 7, 0, 0…
$ Taxi <dbl> 527, 11, 4, 20, 1, 0, 0, 0,…
$ `Motorcycle, scooter or moped` <dbl> 107, 6, 6, 23, 4, 0, 0, 0, …
$ `Driving a car or van` <dbl> 11788, 1225, 448, 3144, 360…
$ `Passenger in a car or van` <dbl> 1965, 99, 36, 365, 33, 0, 0…
$ Bicycle <dbl> 593, 13, 1, 29, 2, 0, 0, 0,…
$ `On foot` <dbl> 3789, 60, 16, 60, 15, 0, 0,…
$ `Other method of travel to work` <dbl> 54, 4, 2, 7, 0, 0, 0, 0, 0,…We can also see we many rows we dropped with glimpse().
It is very important to distinguish between intra- and inter-local authority flows. In network analysis terms, these are the values we find on the diagonal of an adjacency matrix and refer to the commuting flows within a specific local authority or between different ones. For this exercise we are dropping the intra-local authority flows. Although not used here, we also create a new object with the intra-local authority flows.
commuting.intra <- commuting %>%
filter(`Area of usual residence` == `Area of workplace`)
commuting <- commuting %>%
filter(`Area of usual residence` != `Area of workplace`) %>%
glimpse()Rows: 92,688
Columns: 14
$ `Area of usual residence` <chr> "E41000001", "E41000001", "…
$ `Area of workplace` <chr> "E41000002", "E41000003", "…
$ `All categories: Method of travel to work` <dbl> 1591, 534, 3865, 433, 5, 2,…
$ `Work mainly at or from home` <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ `Underground, metro, light rail, tram` <dbl> 1, 0, 1, 0, 0, 0, 0, 0, 0, …
$ Train <dbl> 32, 0, 49, 11, 0, 0, 0, 0, …
$ `Bus, minibus or coach` <dbl> 140, 21, 167, 7, 0, 0, 0, 1…
$ Taxi <dbl> 11, 4, 20, 1, 0, 0, 0, 0, 0…
$ `Motorcycle, scooter or moped` <dbl> 6, 6, 23, 4, 0, 0, 0, 0, 0,…
$ `Driving a car or van` <dbl> 1225, 448, 3144, 360, 5, 2,…
$ `Passenger in a car or van` <dbl> 99, 36, 365, 33, 0, 0, 0, 0…
$ Bicycle <dbl> 13, 1, 29, 2, 0, 0, 0, 0, 0…
$ `On foot` <dbl> 60, 16, 60, 15, 0, 0, 0, 0,…
$ `Other method of travel to work` <dbl> 4, 2, 7, 0, 0, 0, 0, 0, 0, …Please note the constant use of glimpse() to keep control of how many observations we have and check if we missed anything.
Also, take a note of the commuting object, which includes multiple types of commuting flows. Therefore, we will build \(3\) different networks:
one for all the commuting flows
one only for train flows
one only for bicycle flows.
commuting.all <- commuting %>%
select(`Area of usual residence`,
`Area of workplace`,
`All categories: Method of travel to work`) %>%
rename(o = `Area of usual residence`, # Area of usual residence is annoyingly
d = `Area of workplace`, # long, so I am renaiming theses columns
weight = `All categories: Method of travel to work`)
# just FYI this is how you could have achieved the same output using base R
# instead of dplyr of the tidyverse ecosystem
# commuting.all <- commuting[,1:3]
# names(commuting.all)[1] <- "o"
# names(commuting.all)[2] <- "d"
# names(commuting.all)[3] <- "weight"
commuting.train <- commuting %>%
select(`Area of usual residence`,
`Area of workplace`,
`All categories: Method of travel to work`,
`Train`) %>%
rename(o = `Area of usual residence`,
d = `Area of workplace`,
weight = `All categories: Method of travel to work`) %>%
# The below code drops all the lines with 0 train flows in order to exclude
# these edges from the network.
filter(Train!=0)
commuting.bicycle <- commuting %>%
select(`Area of usual residence`,
`Area of workplace`,
`All categories: Method of travel to work`,
`Bicycle`) %>%
rename(o = `Area of usual residence`,
d = `Area of workplace`,
weight = `All categories: Method of travel to work`) %>%
# The below code drops all the lines with 0 bicycle flows in order to exclude
# these edges from the network.
filter(Bicycle!=0)Unless you know the local authority codes by hard, it might be useful to also add the corresponding local authority names. These can be easily obtained from the ONS. The below code directly downloads a GeoJSON file with the local authorities in England and Wales. If you don’t know what a GeoJSON file is, have a look here. Boundary data can also be obtained by UK Data Service.
For the time being we are only interested in the local authority names and codes. We will use the spatial object later.
Tip: the below code downloads the GeoJSON file over the web. If you want to run the code multiple times, it might be faster to download the file ones, save it on your hard drive and the point this location to st_read().
la <-st_read("https://services1.arcgis.com/ESMARspQHYMw9BZ9/arcgis/rest/services/CMLAD_Dec_2011_SGCB_GB_2022/FeatureServer/0/query?outFields=*&where=1%3D1&f=geojson")
glimpse(la)
la.names <- as.data.frame(la) %>%
select(cmlad11cd, cmlad11nm) # all we need is the LA names and codesSpatial interaction modelling
Let’s now move to model these flows. If you remember the basic Gravity model is defined as following:
\[T_{ij} = k \displaystyle \frac{V_i^\lambda M_j^\alpha}{D_{ij}^\beta}\]
And if we take the logarithms of both sides of the equation we can transform the Gravity model to something which looks like a linear model:
\[lnT_{ij} = lnk + \lambda lnV_i + \alpha lnM_j - \beta lnD_{ij}\]
The above transformed equation can be estimated as a linear model if we assume that \(y = lnT_{ij}\), \(c = lnk\), \(x_1 = lnV_i\), \(a_1 = \lambda\) etc. Hence, we can use OLS to estimate the following:
\[lnT_{ij} = lnk + \lambda lnV_i + \alpha lnM_j - \beta lnD_{ij} + e_{ij}\]
This is what is known as the log-linear or log-normal transformation.
There are a number of issues with such an approach though. Most importantly, our dependent variable is not continuous, but instead a discrete, positive variable (there are no flows of -324.56 people!). Therefore we need to employ an appropriate estimator and this is what the Poisson regression does. Briefly, if we exponentiate both sides, the above equation can be written as:
\[T_{ij} = e^{lnk + \lambda lnV_i + \alpha lnM_j - \beta lnD_{ij}}\] The above is in the form of the Poisson regression. So, we are interested in modelling not the mean \(T_{ij}\) drawn from a normally distributed \(T\), but, instead, the mean \(T_{ij}\), which is the average of the all the flows (i.e. counts) between any \(i\) and \(j\). For more details about the Poisson regression have a look at Roback and Legler (2021). For this practical we will estimate the commuting flows using both OLS and Poisson regressions.
But before we get into the estimation we need to build a data frame, which includes all the necessary variables. These are the origin-destination flows \(T\) between \(i\) and \(j\), the distance \(dist\) between \(i\) and \(j\) and the characteristics \(V\) and \(M\) of origin \(i\) and destinations \(j\) that we believe push and pull individuals to commute.
# we use the `SpatialPosition` package and the `CreateDistMatrix()` function to
# calculate a distance matrix for all local authorities,
la.d <- CreateDistMatrix(la, la, longlat = T)
# we use as column and row name the local authority codes
rownames(la.d) <- la$cmlad11cd
colnames(la.d) <- la$cmlad11cd
# This is a matrix of the distances between *all* local authorities. We then use
# the function as.data.frame.table() to convert this matrix to a data frame each
# line of which represents an origin-destination pair.
la.d <- as.data.frame.table(la.d, responseName = "value")
glimpse(la.d)Rows: 119,716
Columns: 3
$ Var1 <fct> E41000001, E41000002, E41000003, E41000004, E41000005, E41000006…
$ Var2 <fct> E41000001, E41000001, E41000001, E41000001, E41000001, E41000001…
$ value <dbl> 0.00, 14338.99, 20147.01, 12892.19, 23203.28, 175341.09, 164899.…# Please note that the elements of the diagonal are present in this distance matrix.If you want to check that the distances we are correct, use google maps to calculate the distance between E41000001 (Middlesbrough) and E41000002 (Hartlepool). Remember that the la.d is expressed in meters.
What is missing here? Do you remember the intra-zone commuting flows? E.g. the commuters that live and work in Bristol? We had removed these from the network analysis and visualisation element. Because we don’t have information about the distances of the intra-zone commutes, we will exclude them from this analysis.
la.d <- la.d %>%
filter(Var1 != Var2) %>%
glimpse()Rows: 119,370
Columns: 3
$ Var1 <fct> E41000002, E41000003, E41000004, E41000005, E41000006, E41000007…
$ Var2 <fct> E41000001, E41000001, E41000001, E41000001, E41000001, E41000001…
$ value <dbl> 14338.99, 20147.01, 12892.19, 23203.28, 175341.09, 164899.50, 13…What we want to do is to match the data frame with all the distances with the commuting flows data frame. To do that we will (1) create a new data frame for the origin-destination pair and (2) match the two data frames.
la.d <- la.d %>%
mutate(ij.code = paste(Var1, Var2, sep = "_")) %>%
glimpse()Rows: 119,370
Columns: 4
$ Var1 <fct> E41000002, E41000003, E41000004, E41000005, E41000006, E410000…
$ Var2 <fct> E41000001, E41000001, E41000001, E41000001, E41000001, E410000…
$ value <dbl> 14338.99, 20147.01, 12892.19, 23203.28, 175341.09, 164899.50, …
$ ij.code <chr> "E41000002_E41000001", "E41000003_E41000001", "E41000004_E4100…commuting <- commuting %>%
mutate(ij.code = paste(`Area of usual residence`,
`Area of workplace`,
sep = "_")) %>%
glimpse()Rows: 92,688
Columns: 15
$ `Area of usual residence` <chr> "E41000001", "E41000001", "…
$ `Area of workplace` <chr> "E41000002", "E41000003", "…
$ `All categories: Method of travel to work` <dbl> 1591, 534, 3865, 433, 5, 2,…
$ `Work mainly at or from home` <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ `Underground, metro, light rail, tram` <dbl> 1, 0, 1, 0, 0, 0, 0, 0, 0, …
$ Train <dbl> 32, 0, 49, 11, 0, 0, 0, 0, …
$ `Bus, minibus or coach` <dbl> 140, 21, 167, 7, 0, 0, 0, 1…
$ Taxi <dbl> 11, 4, 20, 1, 0, 0, 0, 0, 0…
$ `Motorcycle, scooter or moped` <dbl> 6, 6, 23, 4, 0, 0, 0, 0, 0,…
$ `Driving a car or van` <dbl> 1225, 448, 3144, 360, 5, 2,…
$ `Passenger in a car or van` <dbl> 99, 36, 365, 33, 0, 0, 0, 0…
$ Bicycle <dbl> 13, 1, 29, 2, 0, 0, 0, 0, 0…
$ `On foot` <dbl> 60, 16, 60, 15, 0, 0, 0, 0,…
$ `Other method of travel to work` <dbl> 4, 2, 7, 0, 0, 0, 0, 0, 0, …
$ ij.code <chr> "E41000001_E41000002", "E41…Before we perform the match, keep a note of how many observations both data frames have in order to check if we loose any observations during the matching. As you can see the commuting data frame has less observations than the la.d one, which includes all the possible origin-destination pairs.
What does it mean? That for some origin-destination pairs there are no commuting flows, which of course makes sense. We need to include these pairs with \(flow = 0\) in our data though because the lack of commuting flows is not missing data!
commuting.si <- full_join(la.d, commuting, by = "ij.code") %>%
glimpse()Rows: 119,370
Columns: 18
$ Var1 <fct> E41000002, E41000003, E4100…
$ Var2 <fct> E41000001, E41000001, E4100…
$ value <dbl> 14338.99, 20147.01, 12892.1…
$ ij.code <chr> "E41000002_E41000001", "E41…
$ `Area of usual residence` <chr> "E41000002", "E41000003", "…
$ `Area of workplace` <chr> "E41000001", "E41000001", "…
$ `All categories: Method of travel to work` <dbl> 990, 558, 2590, 266, 1, 4, …
$ `Work mainly at or from home` <dbl> 0, 0, 0, 0, 0, 0, 0, NA, 0,…
$ `Underground, metro, light rail, tram` <dbl> 0, 1, 0, 0, 0, 0, 0, NA, 0,…
$ Train <dbl> 6, 3, 25, 2, 0, 0, 0, NA, 1…
$ `Bus, minibus or coach` <dbl> 58, 8, 87, 6, 0, 0, 0, NA, …
$ Taxi <dbl> 1, 2, 4, 0, 0, 0, 0, NA, 0,…
$ `Motorcycle, scooter or moped` <dbl> 2, 1, 12, 0, 0, 0, 0, NA, 0…
$ `Driving a car or van` <dbl> 783, 499, 2259, 244, 1, 4, …
$ `Passenger in a car or van` <dbl> 73, 26, 154, 10, 0, 0, 0, N…
$ Bicycle <dbl> 15, 9, 23, 0, 0, 0, 0, NA, …
$ `On foot` <dbl> 52, 8, 24, 4, 0, 0, 0, NA, …
$ `Other method of travel to work` <dbl> 0, 1, 2, 0, 0, 0, 0, NA, 0,…# Some variables are repetitive or need name change
commuting.si <- commuting.si %>%
rename(i = Var1,
j = Var2,
distance = value) %>%
select(-`Area of usual residence`,
-`Area of workplace`) %>%
glimpse()Rows: 119,370
Columns: 16
$ i <fct> E41000002, E41000003, E4100…
$ j <fct> E41000001, E41000001, E4100…
$ distance <dbl> 14338.99, 20147.01, 12892.1…
$ ij.code <chr> "E41000002_E41000001", "E41…
$ `All categories: Method of travel to work` <dbl> 990, 558, 2590, 266, 1, 4, …
$ `Work mainly at or from home` <dbl> 0, 0, 0, 0, 0, 0, 0, NA, 0,…
$ `Underground, metro, light rail, tram` <dbl> 0, 1, 0, 0, 0, 0, 0, NA, 0,…
$ Train <dbl> 6, 3, 25, 2, 0, 0, 0, NA, 1…
$ `Bus, minibus or coach` <dbl> 58, 8, 87, 6, 0, 0, 0, NA, …
$ Taxi <dbl> 1, 2, 4, 0, 0, 0, 0, NA, 0,…
$ `Motorcycle, scooter or moped` <dbl> 2, 1, 12, 0, 0, 0, 0, NA, 0…
$ `Driving a car or van` <dbl> 783, 499, 2259, 244, 1, 4, …
$ `Passenger in a car or van` <dbl> 73, 26, 154, 10, 0, 0, 0, N…
$ Bicycle <dbl> 15, 9, 23, 0, 0, 0, 0, NA, …
$ `On foot` <dbl> 52, 8, 24, 4, 0, 0, 0, NA, …
$ `Other method of travel to work` <dbl> 0, 1, 2, 0, 0, 0, 0, NA, 0,…# Let's see if we have any missing values
sapply(commuting.si, function(x) sum(is.na(x))) i
0
j
0
distance
0
ij.code
0
All categories: Method of travel to work
26682
Work mainly at or from home
26682
Underground, metro, light rail, tram
26682
Train
26682
Bus, minibus or coach
26682
Taxi
26682
Motorcycle, scooter or moped
26682
Driving a car or van
26682
Passenger in a car or van
26682
Bicycle
26682
On foot
26682
Other method of travel to work
26682 There are quite a few. What does it mean? That there are no commuting flows for these origin-destination pairs and,therefore, were excluded from the origin commuting data set we downloaded. So, we are going to replace these \(NAs\) with \(0s\).
commuting.si <- commuting.si %>%
replace(., is.na(.), 0)Now let’s bring data for some \(i\) and \(j\) characteristics that we believe that affect commuting. I have prepared such a small data set from the census, which includes resident population and working populations as push and pull variables. These data have been obtained by nomis.
# To avoid issues with read_csv() reading directly from Dropbox, we use a
# tempfile trick. First, an empty temp file is created with tempfile(). Then, we
# use download.file() to download the Dropbox file to this temp file. Finally,
# we read the temp file using read_csv().
temp <- tempfile(fileext = ".csv")
download.file(
"https://www.dropbox.com/s/0ym88p8quwaiyau/data_workplace.csv?dl=1",
destfile = temp,
mode = "wb"
)
data.workplace <- readr::read_csv(temp)
# Alternatively, you could read directly from Dropbox using read_csv()
#data.workplace <- read_csv("https://www.dropbox.com/s/0ym88p8quwaiyau/data_workplace.csv?dl=1")
# Important Dropbox trick: to use the link that Dropbox provides to share a
# file in an .Rmd replace dl=0 with dl=1 at the end of the link.
temp <- tempfile(fileext = ".csv")
download.file(
"https://www.dropbox.com/s/09d7v5cm6ov3ioz/data_resident.csv?dl=1",
destfile = temp,
mode = "wb"
)
data.resident <- readr::read_csv(temp)
# Alternatively, you could read directly from Dropbox using read_csv()
#data.resident <- read_csv("https://www.dropbox.com/s/09d7v5cm6ov3ioz/data_resident.csv?dl=1")
commuting.si <- commuting.si %>%
left_join(data.resident, by = c('i' = 'Merging.Local.Authority.Code')) %>%
left_join(data.workplace, by = c('j' = 'Merging.Local.Authority.Code')) Question are there any redundant columns? Can you remove them?
Before we start modelling these flows, let’s plot our variables.
ggplot(commuting.si, aes(x=distance,
y=`All categories: Method of travel to work`)) +
geom_point() +
geom_smooth(method=lm)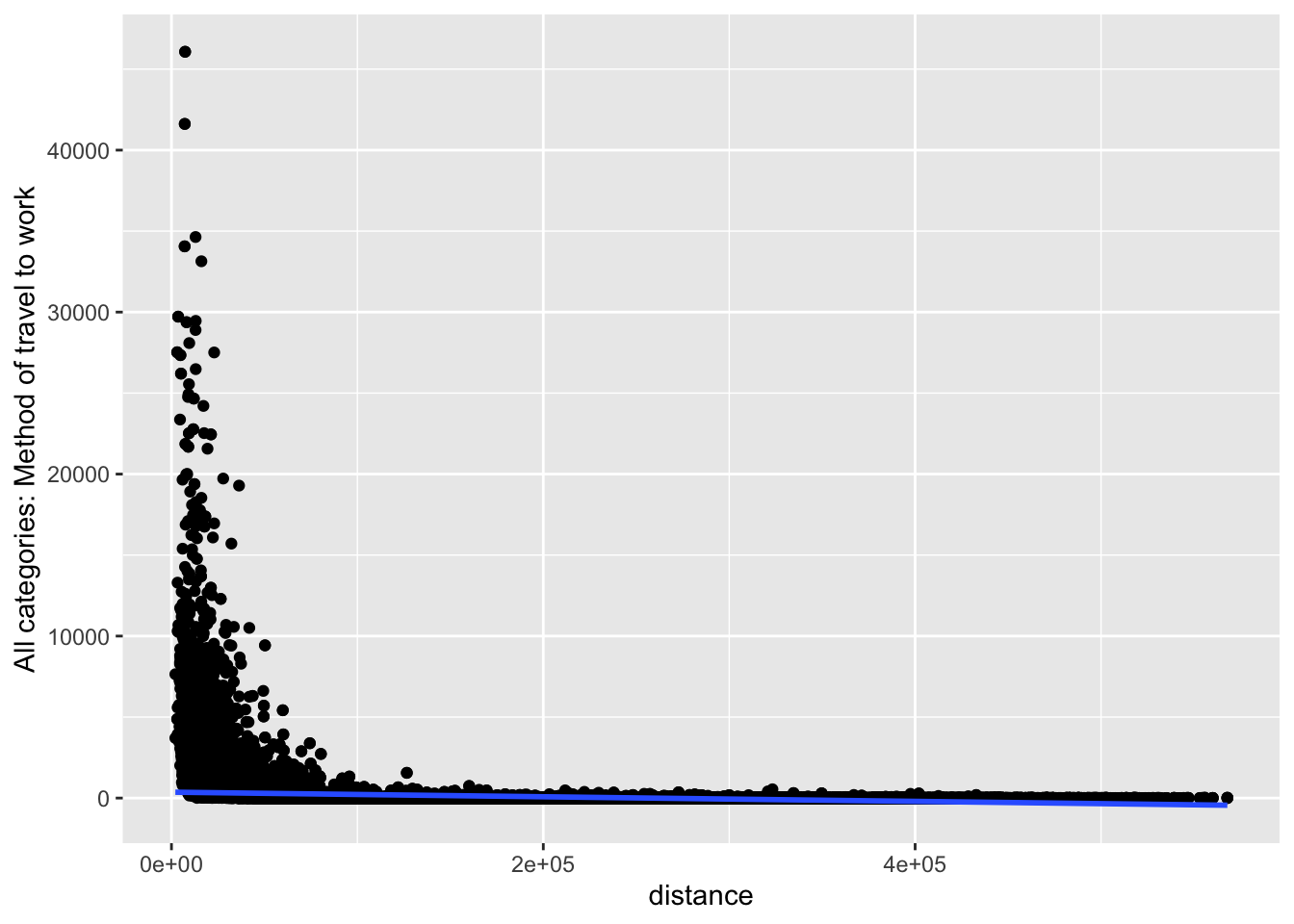
ggplot(commuting.si, aes(x=resident,
y=`All categories: Method of travel to work`)) +
geom_point() +
geom_smooth(method=lm)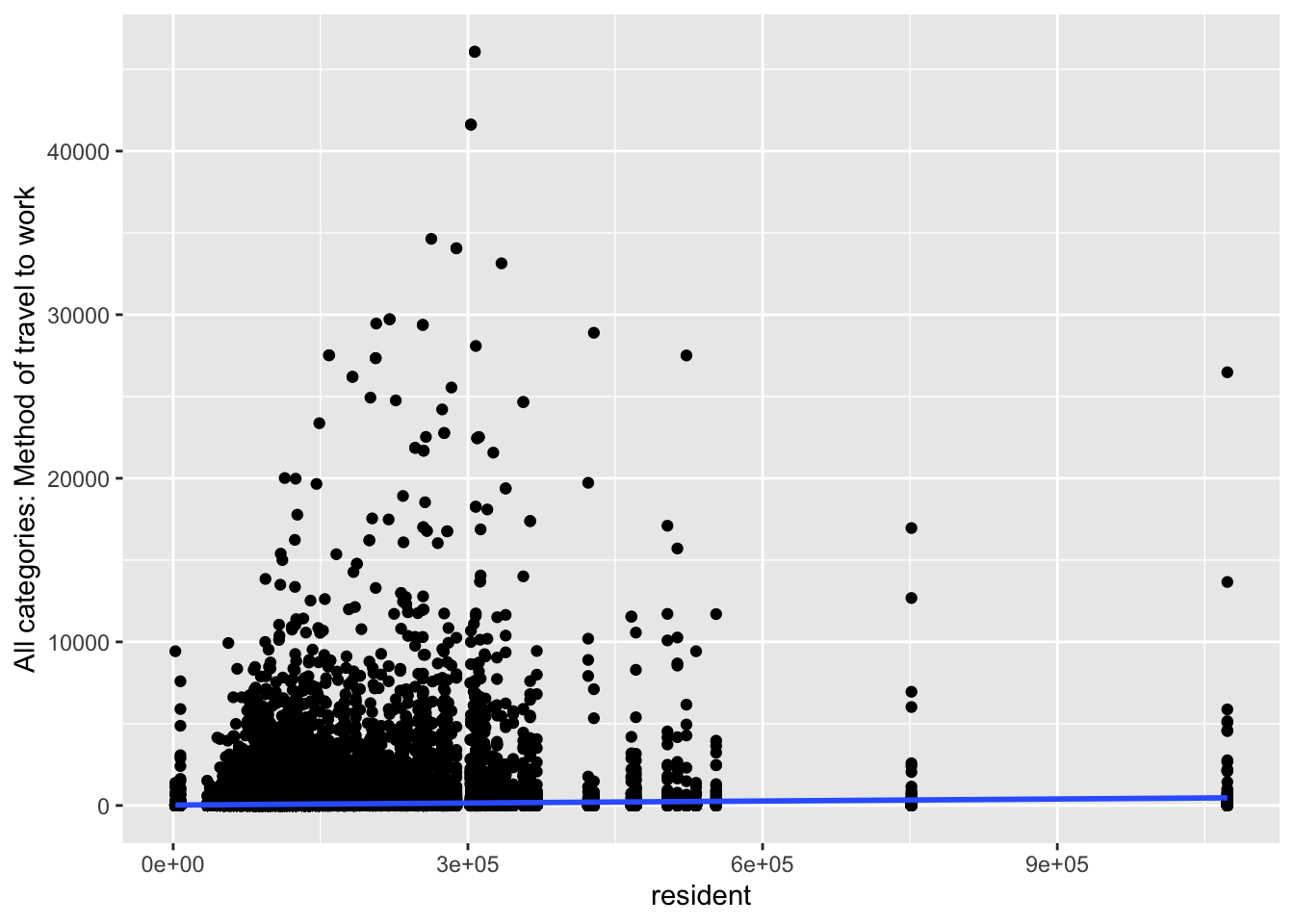
ggplot(commuting.si, aes(x=workplace,
y=`All categories: Method of travel to work`)) +
geom_point() +
geom_smooth(method=lm)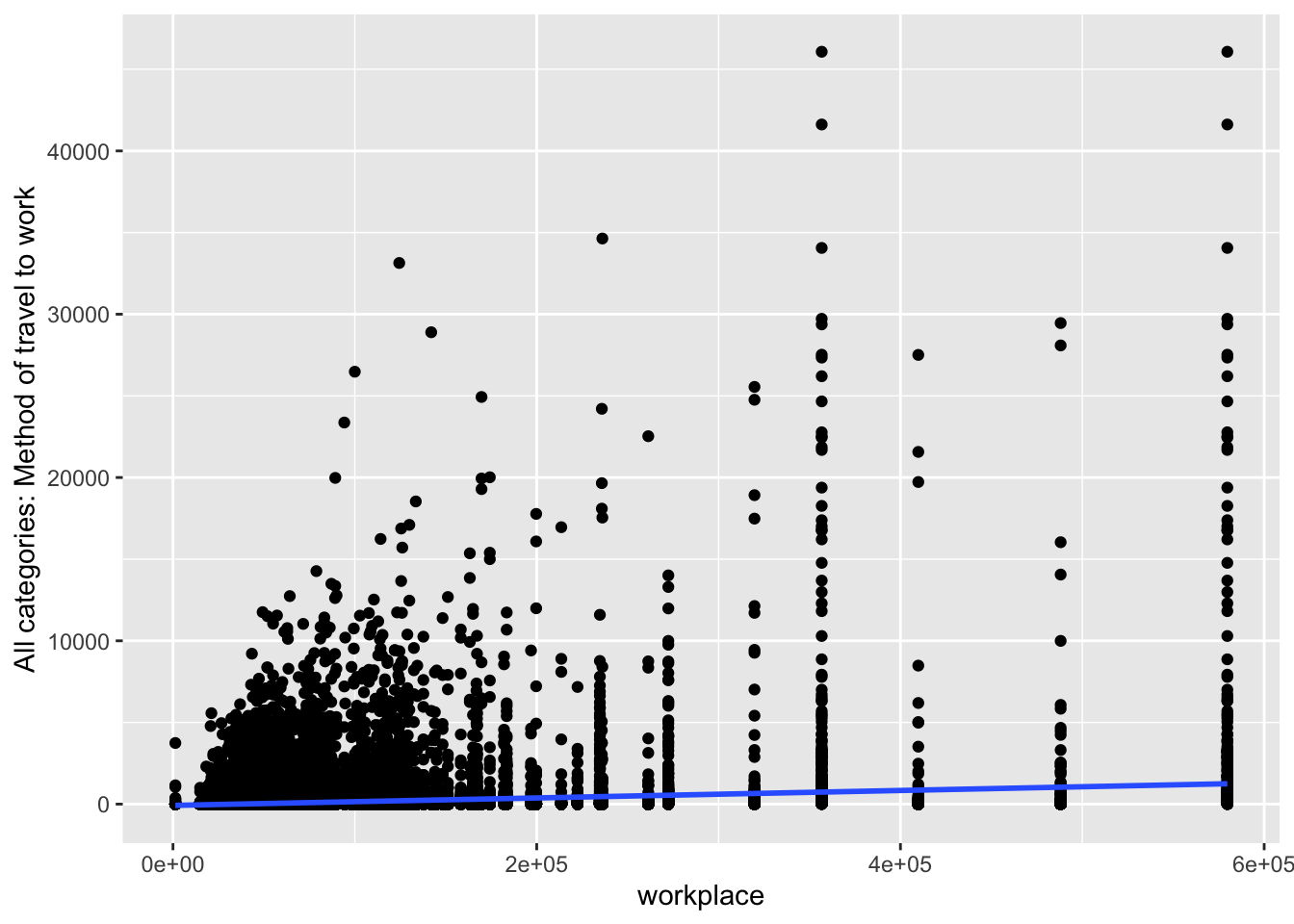
Question What do you take from these graphs?
Let’s try now to model these flows. We will start with a simple OLS to estimate the above specifications. Please pay attention to the small trick we did. Because there are non-materialised origin-destination pairs (i.e. with 0 flows), we added a small value (\(0.5\)) in the dependent variable. Otherwise we will receive an error as the logarithm of \(0\) is not defined.
ols.model <- lm(log(`All categories: Method of travel to work`+.5) ~
log(distance) + log(resident) + log(workplace),
data = commuting.si)
# To see the model output you can use the summary() function.
summary(ols.model)
Call:
lm(formula = log(`All categories: Method of travel to work` +
0.5) ~ log(distance) + log(resident) + log(workplace), data = commuting.si)
Residuals:
Min 1Q Median 3Q Max
-4.2614 -0.7144 -0.0429 0.6430 8.6140
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.967357 0.106119 75.08 <2e-16 ***
log(distance) -1.839401 0.004610 -399.01 <2e-16 ***
log(resident) 0.514034 0.005402 95.16 <2e-16 ***
log(workplace) 0.852322 0.005185 164.37 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.104 on 115932 degrees of freedom
(4816 observations deleted due to missingness)
Multiple R-squared: 0.6444, Adjusted R-squared: 0.6444
F-statistic: 7.002e+04 on 3 and 115932 DF, p-value: < 2.2e-16So, the OLS regression estimated the four parameters:
- \(lnk = 7.968\)
- \(\beta = -1.840\)
- \(\lambda = 0.514\)
- \(\alpha = -0.852\)
Let’s estimate now our model using a Poisson regression. Given that we don’t take the logarithm of the dependent variable, there is no need to add \(0.5\).
glm.model <- glm((`All categories: Method of travel to work`)~
log(distance) + log(resident) + log(workplace),
family = poisson(link = "log"), data = commuting.si)
summary(glm.model)
Call:
glm(formula = (`All categories: Method of travel to work`) ~
log(distance) + log(resident) + log(workplace), family = poisson(link = "log"),
data = commuting.si)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 11.6641641 0.0091381 1276 <2e-16 ***
log(distance) -1.8164748 0.0002803 -6480 <2e-16 ***
log(resident) 0.3179209 0.0005444 584 <2e-16 ***
log(workplace) 0.8191649 0.0004200 1951 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 71855219 on 115935 degrees of freedom
Residual deviance: 14104694 on 115932 degrees of freedom
(4816 observations deleted due to missingness)
AIC: 14447299
Number of Fisher Scoring iterations: 6The following parameter1 have been estimated
- \(lnk = 11.664\)
- \(\beta = -1.816\)
- \(\lambda = 0.318\)
- \(\alpha = 0.820\)
As you can see the differences are rather small.
The stargazer package I use below creates elegant regression tables. Replace type = "html" with type = "text" to have be able to read the results using the .Rmd document. the “html” option is useful for when knitting the script to an .html document.
stargazer(ols.model, glm.model, type = "html")| Dependent variable: | ||
log(All categories: Method of travel to work + 0.5)
|
(All categories: Method of travel to work)
|
|
| OLS | Poisson | |
| (1) | (2) | |
| log(distance) | -1.839*** | -1.816*** |
| (0.005) | (0.0003) | |
| log(resident) | 0.514*** | 0.318*** |
| (0.005) | (0.001) | |
| log(workplace) | 0.852*** | 0.819*** |
| (0.005) | (0.0004) | |
| Constant | 7.967*** | 11.664*** |
| (0.106) | (0.009) | |
| Observations | 115,936 | 115,936 |
| R2 | 0.644 | |
| Adjusted R2 | 0.644 | |
| Log Likelihood | -7,223,645.000 | |
| Akaike Inf. Crit. | 14,447,299.000 | |
| Residual Std. Error | 1.104 (df = 115932) | |
| F Statistic | 70,016.600*** (df = 3; 115932) | |
| Note: | p<0.1; p<0.05; p<0.01 | |
Question Can you interpret the regression results?
This is not a Machine Learning introduction…
… but maybe a sneak preview of the philosophy behind modern data science approaches to answer computational problems. We are using the caret package to:
split our data into test and training
train a
lm()and aglm()model using the training data setuse the estimated models to make out-of-sample predictions using the test data set
plot the results and the relevant metrics and choose the best model.
This is obviously an oversimplification, but it provides a good preview of machine learning frameworks.
It is worth browsing the caret package.
The below will take a few minutes!
commuting.si <- commuting.si %>%
drop_na()
set.seed(3456)
trainIndex <- createDataPartition(commuting.si$`All categories: Method of travel to work`, p = .8,
list = FALSE,
times = 1)
dim(trainIndex)[1] 92751 1
dim(commuting.si)[1] 115936 22
commuting.si.train <- commuting.si[ trainIndex,]
commuting.si.test <- commuting.si[-trainIndex,]
model.lm <- train(`All categories: Method of travel to work` ~
distance + resident + workplace,
data = commuting.si,
method = "lm")
predictions.lm <- predict(model.lm, commuting.si.test)
lm.metrics <- postResample(pred = predictions.lm, obs = commuting.si.test$`All categories: Method of travel to work`)
model.glm <- train(`All categories: Method of travel to work` ~
distance + resident + workplace,
data = commuting.si,
method = "glmnet",
family = "poisson",
na.action = na.omit)
predictions.glm <- predict(model.glm, commuting.si.test)
glm.metrics <- postResample(pred = predictions.glm, obs = commuting.si.test$`All categories: Method of travel to work`)
bind_rows(lm.metrics, glm.metrics) %>%
mutate(Model = c("lm", "glm")) %>%
select(Model, Rsquared, RMSE, MAE) %>%
kable(digits = 3)| Model | Rsquared | RMSE | MAE |
|---|---|---|---|
| lm | 0.067 | 824.067 | 214.033 |
| glm | 0.422 | 687.811 | 112.527 |
Question Which model would you choose?
predict.lm.plot <- bind_cols(commuting.si.test$`All categories: Method of travel to work`, predictions.lm) %>%
rename(y = '...1',
y_hat = '...2') %>%
ggplot(aes(x=y, y=y_hat)) + geom_point() + ggtitle("lm") +
theme(plot.title = element_text(hjust = 0.5))
predict.glm.plot <- bind_cols(commuting.si.test$`All categories: Method of travel to work`, predictions.glm) %>%
rename(y = '...1',
y_hat = '...2') %>%
ggplot(aes(x=y, y=y_hat)) + geom_point() + ggtitle("glm") +
theme(plot.title = element_text(hjust = 0.5))
library(patchwork)
predict.lm.plot + predict.glm.plot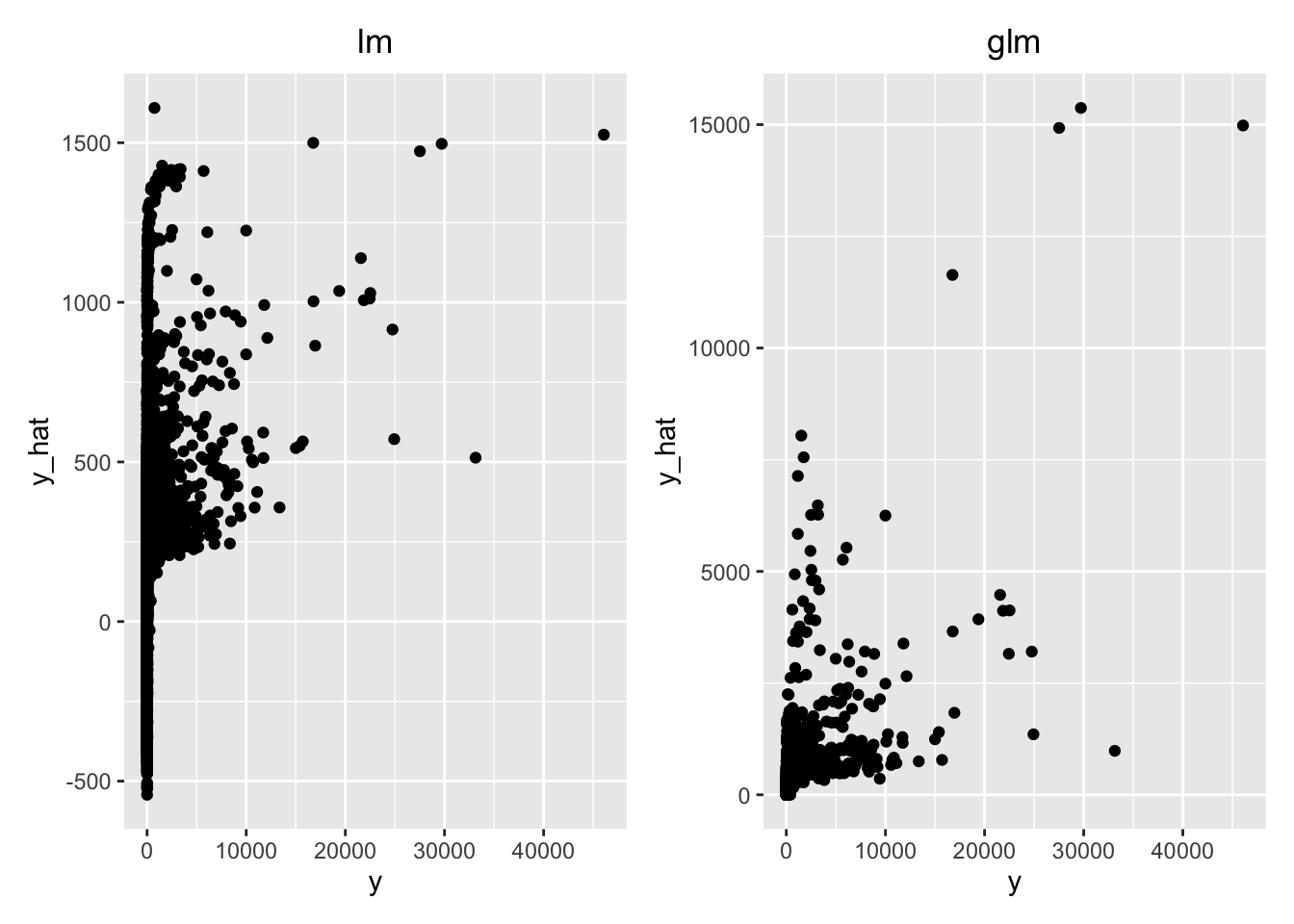
References
Lovelace, Robin, Jakub Nowosad, and Jannes Muenchow. 2019. Geocomputation with r. Chapman; Hall/CRC.
Oshan, Taylor M. 2021. “The Spatial Structure Debate in Spatial Interaction Modeling: 50 Years On.” Progress in Human Geography 45 (5): 925–50.
Roback, Paul, and Julie Legler. 2021. Beyond Multiple Linear Regression: Applied Generalized Linear Models and Multilevel Models in r. Chapman; Hall/CRC.
Tranos, Emmanouil, André Carrascal-Incera, and George Willis. 2022. “Using the Web to Predict Regional Trade Flows: Data Extraction, Modeling, and Validation.” Annals of the American Association of Geographers, 1–23.