[1] 0.655[1] 0.25Production, i.e. firms
Consumption, i.e. product variety
Labour pool, i.e. skills in labour market
In general is a good thing for:
urban economies
productivity
urban and industrial agglomeration
Within-sector or Marshall–Arrow–Romer (MAR) spillovers
Between-sector or Jacobs spillovers
Large empirical literature trying to identify the optimal ratio, e.g. Saviotti and Frenken (2008) and Caragliu, Dominicis, and Groot (2016)
MAR externalities (or spillovers): good for productivity and short-term growth
Jacobean externalities: good for innovation and long-term growth
Using more clear economics terminology (Fujita et al. 1989):
Diverse cities (heterogeneous agglomerations) enjoy economies of scope
Homogeneous agglomeration enjoy increasing returns from economies of scale
Ambiguous concepts
Variety, diversity, difference: a relative concept of agglomeration and the clustering of activities
Not only higher ‘abundance’, ‘difference’ or ‘number’, but also the degrees of ‘richness’, ‘concentration’ or ‘evenness’ (Yuo and Tseng 2021)
Different ways to measure (Bettencourt 2021)
… aka variety
\(D = \sum_{i}^n p_{i}^0\)
\(p_i\) is the proportion of data points in the \(i\)th category
\(n\) is the number of total categories
A count of different species / categories / …
Interpretation:
Plurality
Availability of options
\(H = -\sum_{i}^n p_{i} \ln{p_{i}}\)
\(n\) is the number of total categories
\(p_i\) is the proportion of data points in the \(i\)th category
Probably the most common diversity index.
Interpretation:
If one category dominates ➔ less surprise ➔ low entropy
No category dominates ➔ more surprise ➔ high entropy
\(HHI = \sum_{i}^{n}(p_{i}^2)\)
\(p_i\) is the proportion of data points in the \(i\)th category
Concentration of the market.
Interpretation:
\(1/n \leq HHI \leq 1\)
Two scenarios:
Caution: alternative specification
\(HHI = 1- \sum_{i}^{n}(p_{i}^2)\)
Relatedness spans the continuum between MAR and Jacobs (Hidalgo 2021)
Related activities are neither exactly the same nor completely different (Frenken, Van Oort, and Verburg 2007; Boschma et al. 2012)
Why? Because:
identical activities compete for customers and resources,
no learning between very dissimilar economic activities
Large scale fine-grained data on economic activities
Learn about abstract factors of production and the way they combine into outputs
Dimensionality reduction techniques to data on the geography of activities, e.g. employment by industry or patents by technology
Machine learning and network techniques to predict and explain the economic trajectories of countries, cities and regions
For a review, check Hidalgo (2021) and Balland et al. (2022).
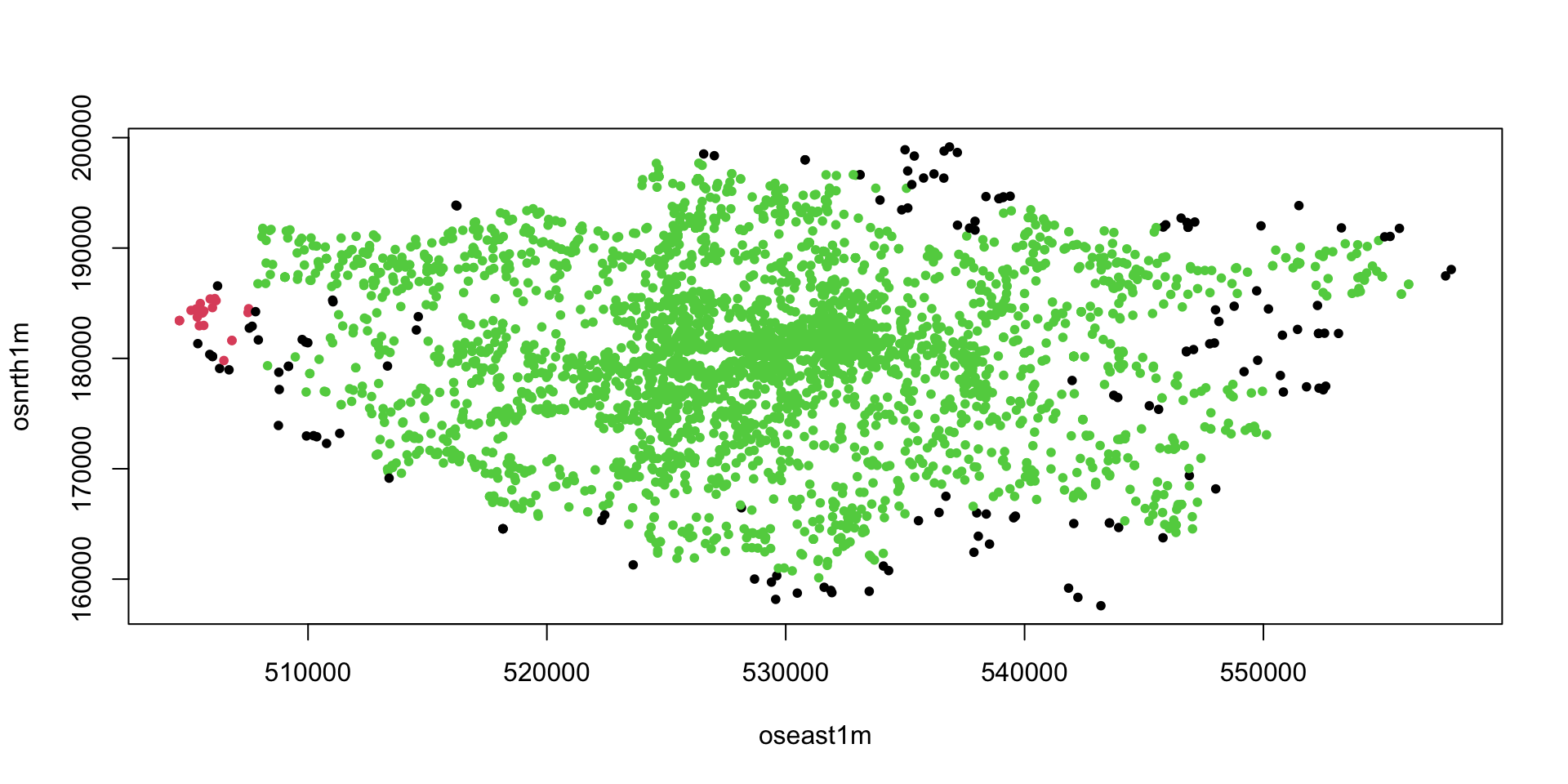
Source: Companies House
Go to data.london.gov.uk
Download and and save locally the Businesses-in-London.csv
Make sure you know the file location!
We will use the REAT and entropy packages. Check what these packages do here and here.
Install them if needed with install.packages("packagename")
library(tidyverse) # for data wrangling
library(rprojroot) # for relative paths
library(REAT) # for diversity measures
library(entropy) # for entropy
library(cluster) # for cluster analysis
library(factoextra) # help functions for clustering
library(kableExtra) # for nice html tables
library(dbscan) # for HDBSCAL
library(sf) # for mapping
# This is the project path
path <- find_rstudio_root_file()
path.data <- paste0(path, "/data/businesses-in-london.csv")
london.firms <- read_csv(path.data)
london.firms.sum <- london.firms %>%
filter(SICCode.SicText_1!="None Supplied") %>% # dropping NAs in essence
group_by(oslaua, SICCode.SicText_1) %>% # grouping by Local Authority and SIC code
summarise(n = n()) %>% # summarise: n is the number of firms per Local Authority and SIC code
mutate(total = sum(n), # total equal all firms
freq = n / total) %>% # just a frequency
group_by(oslaua) %>% # grouping again only by Local Authority
summarise(richness = n_distinct(SICCode.SicText_1), # the number of distinct SIC per Local Authority
entropy = entropy(freq, method = "ML"), # entropy for each Local Authority, we did the first group_by() and mutate() to be able to calculate freq so we can calculate entropy
herf = herf(n)) %>% # HHI for each local authority
arrange(-herf) # sort based on HHI (descending)
london.firms.sum %>% kbl() %>%
kable_styling(full_width = F, font_size = 12) %>% # A nice(r) table
scroll_box(width = "1200px", height = "300px")| oslaua | richness | entropy | herf |
|---|---|---|---|
| E09000013 | 602 | 4.637865 | 0.0301165 |
| E09000001 | 744 | 4.520774 | 0.0288396 |
| E09000033 | 827 | 4.607933 | 0.0258339 |
| E09000003 | 723 | 4.671225 | 0.0233361 |
| E09000008 | 678 | 4.786546 | 0.0221182 |
| E09000027 | 558 | 4.712318 | 0.0220274 |
| E09000015 | 633 | 4.730619 | 0.0205194 |
| E09000010 | 667 | 4.790814 | 0.0204714 |
| E09000007 | 827 | 4.829186 | 0.0204085 |
| E09000020 | 577 | 4.774282 | 0.0196181 |
| E09000030 | 690 | 4.802693 | 0.0193494 |
| E09000025 | 623 | 4.816502 | 0.0188794 |
| E09000032 | 571 | 4.831936 | 0.0184425 |
| E09000026 | 630 | 4.806874 | 0.0180738 |
| E09000012 | 729 | 4.915068 | 0.0178886 |
| E09000014 | 595 | 4.830779 | 0.0178559 |
| E09000019 | 803 | 4.904964 | 0.0178424 |
| E09000006 | 599 | 4.833756 | 0.0177523 |
| E09000021 | 529 | 4.856868 | 0.0176720 |
| E09000004 | 569 | 4.849445 | 0.0176348 |
| E09000024 | 582 | 4.860828 | 0.0168338 |
| E09000018 | 603 | 4.906424 | 0.0163947 |
| E09000029 | 543 | 4.879529 | 0.0162662 |
| E09000022 | 594 | 4.925276 | 0.0157286 |
| E09000017 | 640 | 4.960676 | 0.0153900 |
| E09000005 | 644 | 4.958913 | 0.0146799 |
| E09000016 | 564 | 4.936603 | 0.0145663 |
| E09000028 | 681 | 4.996227 | 0.0145643 |
| E09000002 | 543 | 4.916217 | 0.0143203 |
| E09000009 | 645 | 4.992793 | 0.0142574 |
| E09000031 | 587 | 4.977460 | 0.0136438 |
| E09000011 | 565 | 4.995980 | 0.0136430 |
| E09000023 | 540 | 5.008342 | 0.0130329 |
Tip
You don’t know what local authorities these codes refer to. You should download the codes and names and join them with your data from here.
Tip
Discuss what we can learn from this exercise.
Can you think of a way to understand how different these indices are among London’s Local Authorities?
path.shape <- paste0(path, "/data/Local_Authority_Districts_(May_2021)_UK_BFE.geojson")
london <- st_read(path.shape, quiet = T) %>%
dplyr::filter(LAD21CD %in% (london.firms$oslaua)) # Pay attention on the %in% operator. It means 'within'.
london <- merge(london, london.firms.sum, by.x = "LAD21CD", by.y = "oslaua" )
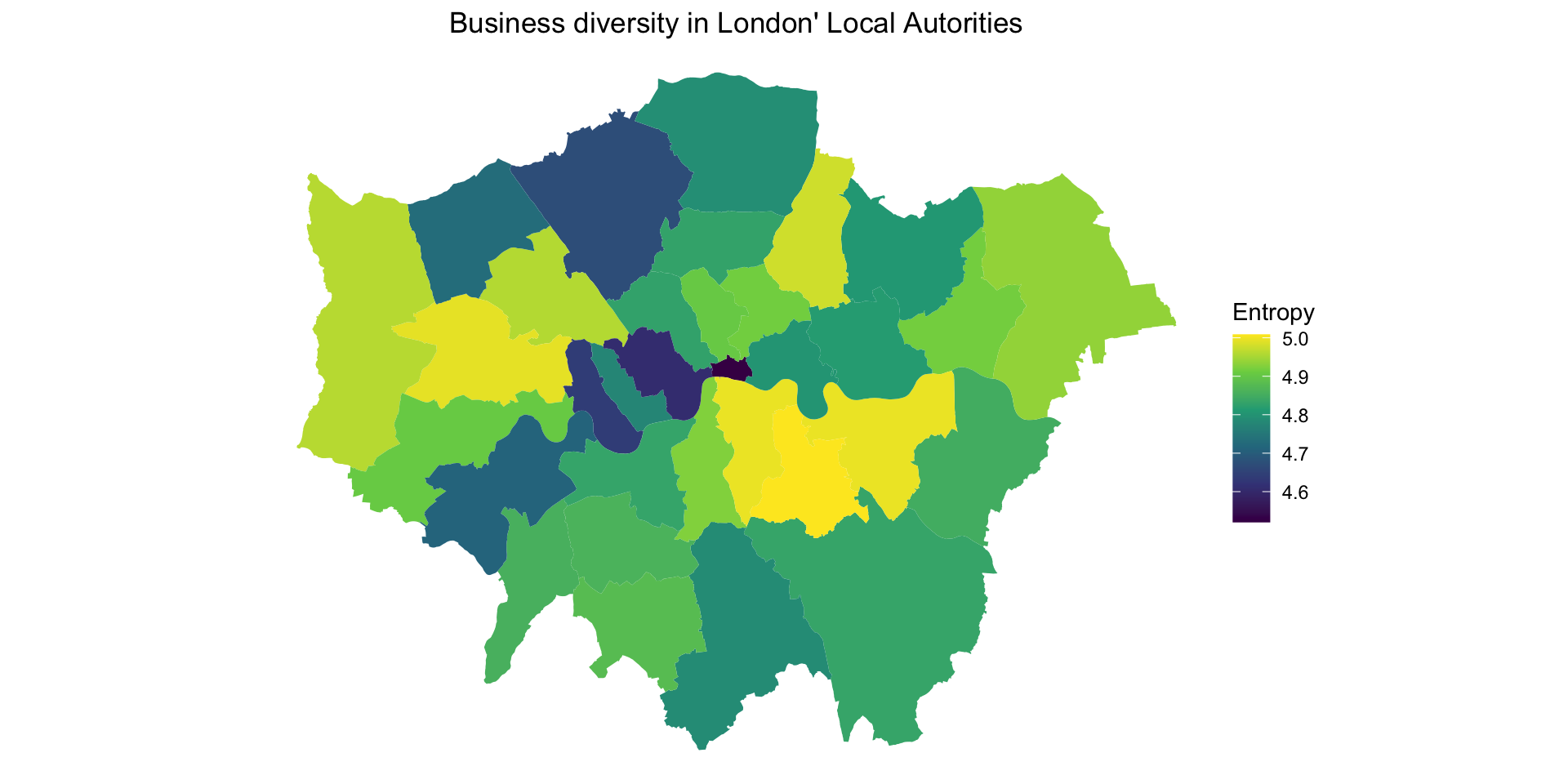
ggplot() +
geom_sf(data = london, aes(fill = entropy), color = NA) +
labs(
title = "Business diversity in London' Local Autorities",
fill = "Entropy") +
scale_fill_viridis_c() +
theme_void() +
theme(plot.title = element_text(hjust = 0.5)) # centres the titleReducing the dimensions of the observation space
Classification of observations into (exclusive) groups
Distance or (dis)similarity between each pair of observations to create a distance or dissimilarity or matrix
Observations within the same group are as similar as possible
Plenty of other resources online and in textbooks
Source: medium.com
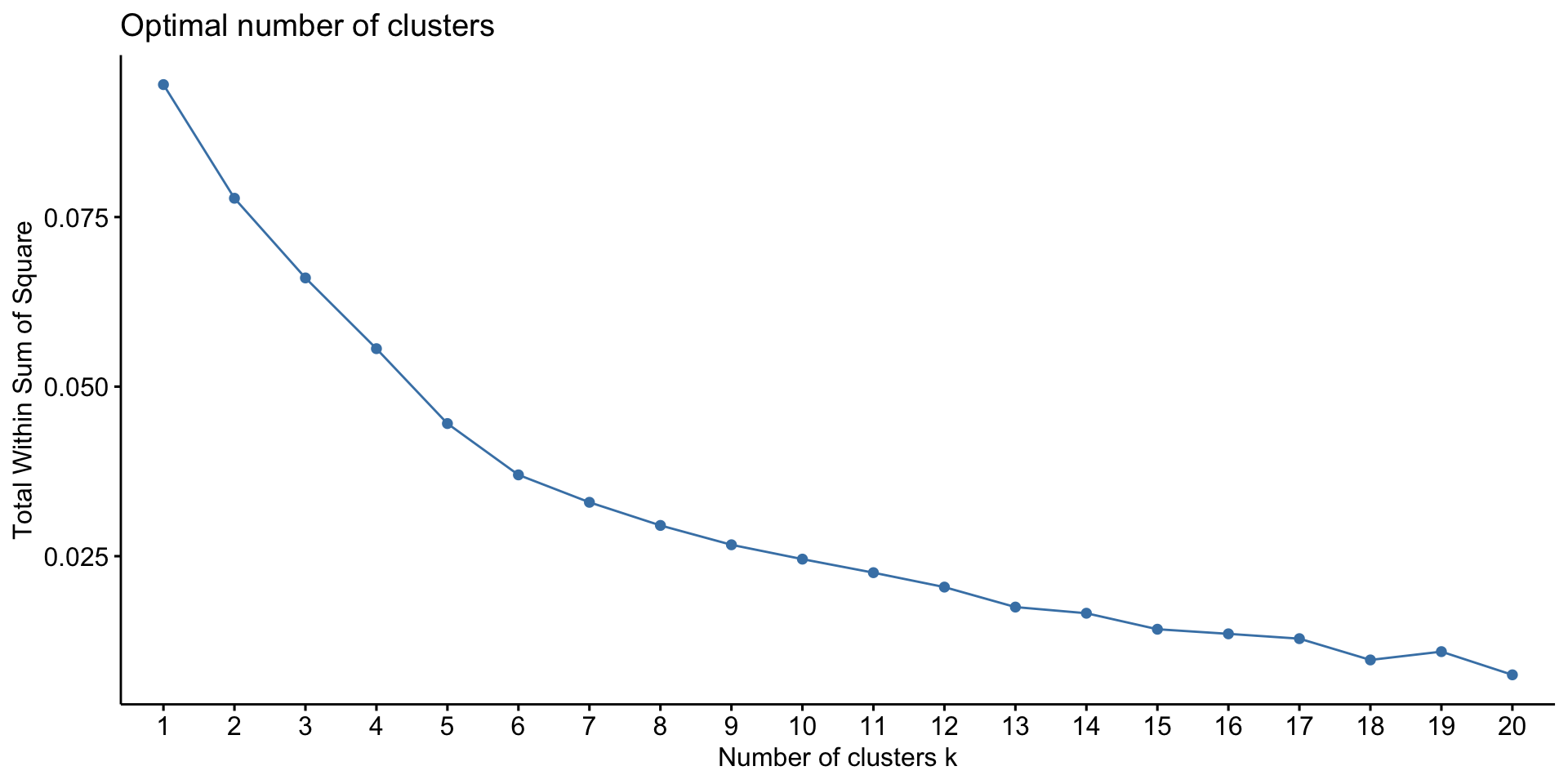
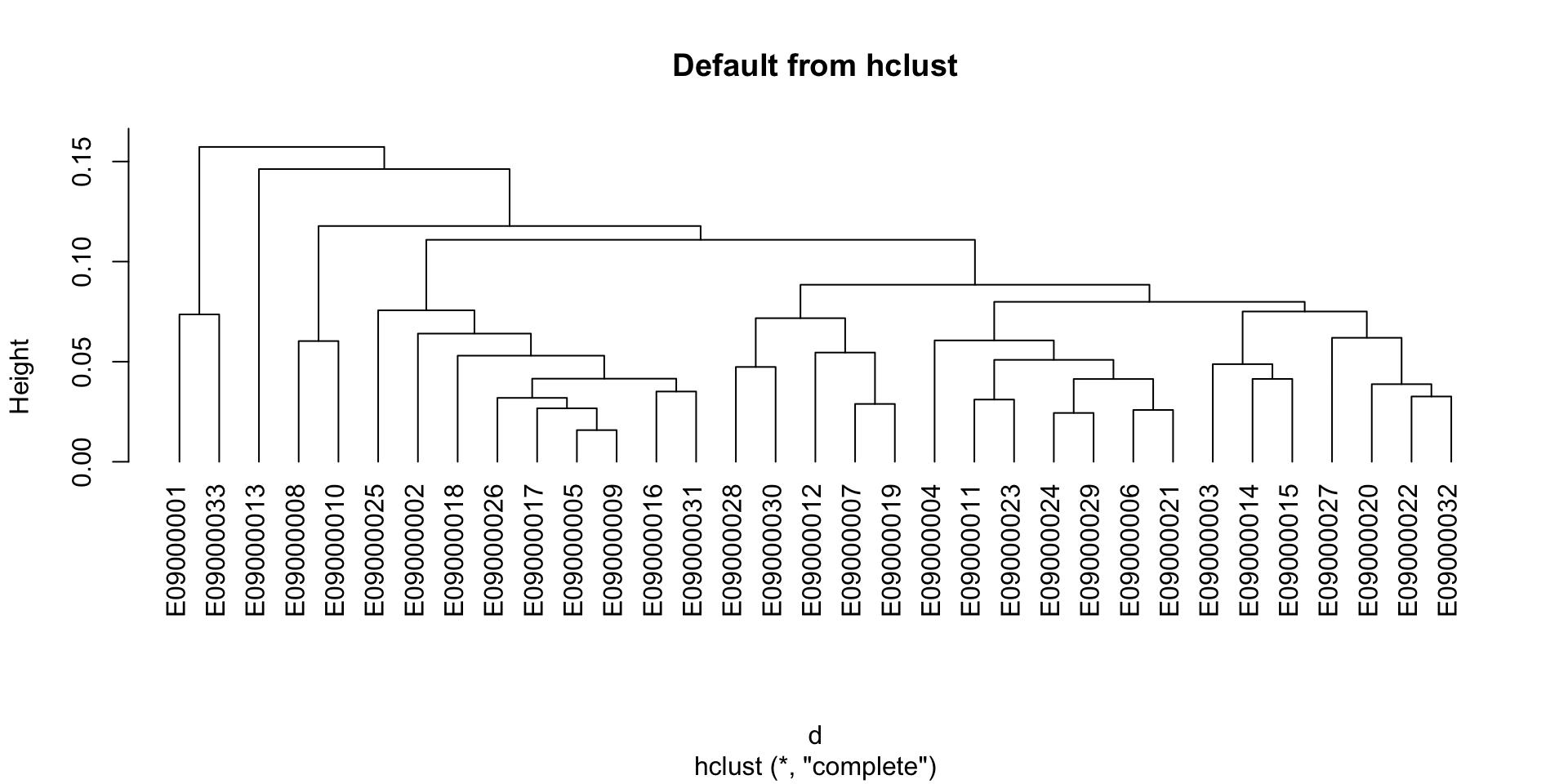
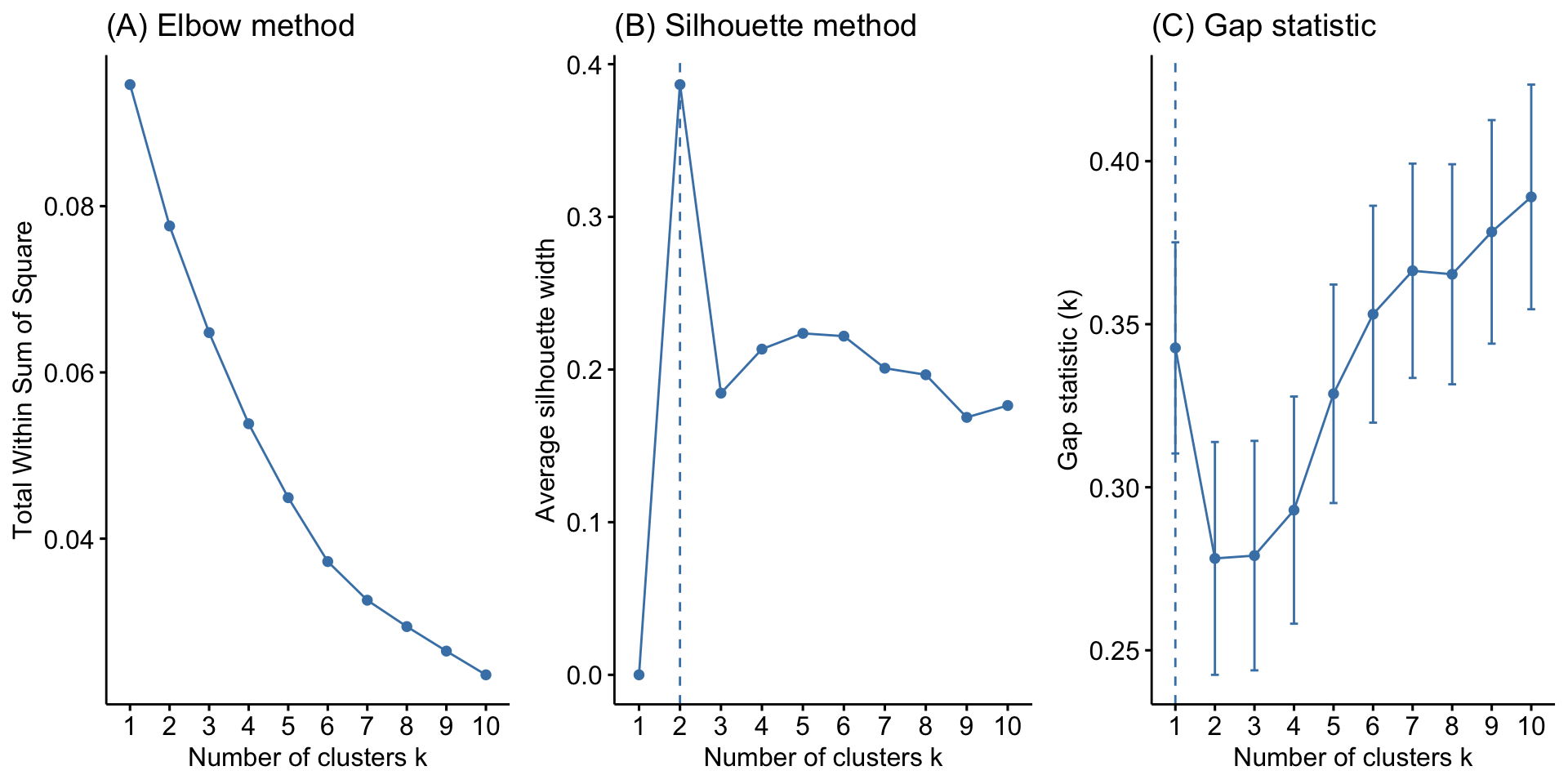
k-means
Hierarchical clustering
k is the number of clusters and is pre-defined
The algorithm selects k random observations (starting centres)
The remaining observations are assigned to the nearest centre
Recalculates the new centres
Re-check cluster assignment
Iterative process to minimise within-cluster variation until convergence
\(SS_{within} = \sum_{k=1}^k W(C_{k}) = \sum_{k=1}^k \sum_{x_i\in C_K}(x_i-\mu_k)^2\)
First, create an appropriate data frame:
la.sic <- london.firms %>%
filter(SICCode.SicText_1!="None Supplied") %>% # Drop firms which haven't declared SIC code
group_by(oslaua, SICCode.SicText_1) %>% # Group by Local Authorities and SIC code
summarise(n = n()) %>% # Summarise; n = number of observations
mutate(total = sum(n), # New column: total number of observations
freq = n / total) %>% # New column: frequency
arrange(oslaua,-n) %>% # Just arrange by Local Authority and descenting order of n
select(-n, -total) %>% # Drop n and total, we don't need them any more.
pivot_wider(names_from = SICCode.SicText_1, values_from = freq) %>% # Data transformation: from long to wide. Have a look: https://tidyr.tidyverse.org/reference/pivot_wider.html
replace(is.na(.), 0) # Replace any missing values with 0 as missing value represent SIC codes with 0 frequency
la.sic %>%
select(1:20) %>% # Select the first 20 columns as there 1037 in total
kbl() %>%
kable_styling(full_width = F, font_size = 11) %>% # Nice(r) table
scroll_box(width = "1200px", height = "800px")| oslaua | 82990 - Other business support service activities n.e.c. | 64209 - Activities of other holding companies n.e.c. | 70229 - Management consultancy activities other than financial management | 64999 - Financial intermediation not elsewhere classified | 99999 - Dormant Company | 74990 - Non-trading company | 70100 - Activities of head offices | 68209 - Other letting and operating of own or leased real estate | 62020 - Information technology consultancy activities | 68100 - Buying and selling of own real estate | 65120 - Non-life insurance | 96090 - Other service activities n.e.c. | 41100 - Development of building projects | 62012 - Business and domestic software development | 62090 - Other information technology service activities | 35110 - Production of electricity | 64205 - Activities of financial services holding companies | 74909 - Other professional, scientific and technical activities n.e.c. | 65110 - Life insurance |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E09000001 | 0.1108145 | 0.0606884 | 0.0401823 | 0.0379038 | 0.0363252 | 0.0361787 | 0.0271462 | 0.0261046 | 0.0247376 | 0.0239889 | 0.0239238 | 0.0232403 | 0.0208642 | 0.0198714 | 0.0193018 | 0.0183579 | 0.0161282 | 0.0155586 | 0.0117829 |
| E09000002 | 0.0270344 | 0.0027363 | 0.0241340 | 0.0024626 | 0.0061840 | 0.0026816 | 0.0013681 | 0.0173480 | 0.0254474 | 0.0313030 | 0.0001095 | 0.0348602 | 0.0163629 | 0.0068954 | 0.0107262 | 0.0000547 | 0.0004378 | 0.0078258 | 0.0000547 |
| E09000003 | 0.0600694 | 0.0131911 | 0.0403222 | 0.0081328 | 0.0314536 | 0.0152407 | 0.0037313 | 0.0658109 | 0.0258041 | 0.0686751 | 0.0003942 | 0.0442374 | 0.0313223 | 0.0093678 | 0.0109181 | 0.0010511 | 0.0012876 | 0.0106816 | 0.0003022 |
| E09000004 | 0.0714510 | 0.0073915 | 0.0429860 | 0.0039316 | 0.0150975 | 0.0074963 | 0.0025163 | 0.0291466 | 0.0347033 | 0.0404173 | 0.0004718 | 0.0300377 | 0.0214406 | 0.0071818 | 0.0114280 | 0.0004194 | 0.0004194 | 0.0112183 | 0.0001573 |
| E09000005 | 0.0357725 | 0.0060626 | 0.0302829 | 0.0057610 | 0.0234964 | 0.0061229 | 0.0027749 | 0.0451228 | 0.0273572 | 0.0451529 | 0.0002111 | 0.0339326 | 0.0193039 | 0.0080533 | 0.0110394 | 0.0003318 | 0.0006937 | 0.0120951 | 0.0000603 |
| E09000006 | 0.0475336 | 0.0079285 | 0.0482441 | 0.0065073 | 0.0258798 | 0.0078537 | 0.0035529 | 0.0407644 | 0.0376977 | 0.0391937 | 0.0012716 | 0.0269270 | 0.0253562 | 0.0119675 | 0.0129773 | 0.0002618 | 0.0007854 | 0.0157448 | 0.0001870 |
| E09000007 | 0.0541925 | 0.0147704 | 0.0451042 | 0.0091985 | 0.0176188 | 0.0095582 | 0.0063354 | 0.0248425 | 0.0352450 | 0.0353404 | 0.0002790 | 0.0431734 | 0.0260612 | 0.0269274 | 0.0163561 | 0.0019454 | 0.0036706 | 0.0121643 | 0.0001688 |
| E09000008 | 0.0358566 | 0.0042869 | 0.0328511 | 0.0057082 | 0.0886745 | 0.0097621 | 0.0027492 | 0.0308940 | 0.0316861 | 0.0352275 | 0.0002563 | 0.0260246 | 0.0205261 | 0.0105543 | 0.0156800 | 0.0003728 | 0.0027026 | 0.0091098 | 0.0002097 |
| E09000009 | 0.0325698 | 0.0062051 | 0.0333419 | 0.0044036 | 0.0177290 | 0.0084928 | 0.0036602 | 0.0394327 | 0.0277087 | 0.0445226 | 0.0002002 | 0.0352864 | 0.0220468 | 0.0095222 | 0.0106374 | 0.0002860 | 0.0011152 | 0.0100369 | 0.0000858 |
| E09000010 | 0.0361647 | 0.0106993 | 0.0303793 | 0.0056159 | 0.0855462 | 0.0089807 | 0.0024207 | 0.0462347 | 0.0218102 | 0.0379076 | 0.0004115 | 0.0357532 | 0.0213987 | 0.0127811 | 0.0115466 | 0.0002421 | 0.0017913 | 0.0091501 | 0.0002421 |
| E09000011 | 0.0352018 | 0.0036909 | 0.0420300 | 0.0038754 | 0.0134717 | 0.0044752 | 0.0021223 | 0.0251903 | 0.0373702 | 0.0333564 | 0.0003691 | 0.0352480 | 0.0183622 | 0.0120877 | 0.0130104 | 0.0004614 | 0.0014302 | 0.0120415 | 0.0000923 |
| E09000012 | 0.0512285 | 0.0097657 | 0.0496767 | 0.0063622 | 0.0329695 | 0.0031242 | 0.0022862 | 0.0412559 | 0.0384524 | 0.0476801 | 0.0002897 | 0.0205038 | 0.0148865 | 0.0235245 | 0.0167486 | 0.0015621 | 0.0025449 | 0.0118450 | 0.0000621 |
| E09000013 | 0.0423722 | 0.0123893 | 0.0448190 | 0.0076899 | 0.0190306 | 0.0101755 | 0.0087774 | 0.1304179 | 0.0213220 | 0.0310704 | 0.0001554 | 0.0332453 | 0.0167780 | 0.0116126 | 0.0129719 | 0.0013982 | 0.0015147 | 0.0148361 | 0.0000388 |
| E09000014 | 0.0339895 | 0.0056534 | 0.0407460 | 0.0045848 | 0.0256127 | 0.0055500 | 0.0031370 | 0.0527423 | 0.0272674 | 0.0578096 | 0.0001379 | 0.0438829 | 0.0167879 | 0.0113758 | 0.0085491 | 0.0003792 | 0.0009307 | 0.0091696 | 0.0000345 |
| E09000015 | 0.0486010 | 0.0124162 | 0.0466257 | 0.0083570 | 0.0189498 | 0.0074019 | 0.0031692 | 0.0576744 | 0.0423495 | 0.0634049 | 0.0002605 | 0.0342313 | 0.0266123 | 0.0127418 | 0.0140876 | 0.0002171 | 0.0012373 | 0.0184940 | 0.0001954 |
| E09000016 | 0.0449873 | 0.0058253 | 0.0335324 | 0.0070981 | 0.0186019 | 0.0052379 | 0.0017623 | 0.0327981 | 0.0270217 | 0.0414137 | 0.0008811 | 0.0315743 | 0.0251126 | 0.0092520 | 0.0097415 | 0.0000979 | 0.0009301 | 0.0105248 | 0.0000979 |
| E09000017 | 0.0340671 | 0.0094125 | 0.0317595 | 0.0047062 | 0.0160012 | 0.0068316 | 0.0052528 | 0.0389252 | 0.0357674 | 0.0526188 | 0.0003036 | 0.0352513 | 0.0235616 | 0.0123273 | 0.0135722 | 0.0002429 | 0.0015181 | 0.0123577 | 0.0002429 |
| E09000018 | 0.0348997 | 0.0088552 | 0.0347881 | 0.0054322 | 0.0130223 | 0.0102690 | 0.0069576 | 0.0298396 | 0.0549540 | 0.0416341 | 0.0002232 | 0.0361275 | 0.0193474 | 0.0161848 | 0.0141385 | 0.0004093 | 0.0013766 | 0.0104178 | 0.0001488 |
| E09000019 | 0.0509646 | 0.0133515 | 0.0490896 | 0.0090981 | 0.0198825 | 0.0094630 | 0.0062919 | 0.0248783 | 0.0370846 | 0.0317616 | 0.0005537 | 0.0470006 | 0.0223615 | 0.0277725 | 0.0190771 | 0.0017617 | 0.0040646 | 0.0131753 | 0.0002139 |
| E09000020 | 0.0499206 | 0.0187149 | 0.0547281 | 0.0133494 | 0.0227926 | 0.0141649 | 0.0104735 | 0.0411641 | 0.0188866 | 0.0365712 | 0.0002575 | 0.0403056 | 0.0202601 | 0.0148517 | 0.0121475 | 0.0031335 | 0.0041207 | 0.0146371 | 0.0000000 |
| E09000021 | 0.0478516 | 0.0081613 | 0.0512695 | 0.0039063 | 0.0151367 | 0.0095564 | 0.0043248 | 0.0353655 | 0.0399693 | 0.0358538 | 0.0006975 | 0.0272740 | 0.0177176 | 0.0142997 | 0.0145787 | 0.0002790 | 0.0014648 | 0.0150670 | 0.0002790 |
| E09000022 | 0.0335485 | 0.0086577 | 0.0420129 | 0.0044448 | 0.0180111 | 0.0090055 | 0.0052951 | 0.0372976 | 0.0252773 | 0.0306497 | 0.0001546 | 0.0331620 | 0.0143006 | 0.0117497 | 0.0112472 | 0.0028215 | 0.0009276 | 0.0134890 | 0.0000773 |
| E09000023 | 0.0320543 | 0.0035557 | 0.0378921 | 0.0041925 | 0.0113570 | 0.0044579 | 0.0016982 | 0.0268535 | 0.0312583 | 0.0294008 | 0.0000531 | 0.0311522 | 0.0145412 | 0.0110917 | 0.0118877 | 0.0001061 | 0.0013268 | 0.0110917 | 0.0000531 |
| E09000024 | 0.0354735 | 0.0083443 | 0.0490793 | 0.0051381 | 0.0251973 | 0.0069878 | 0.0037817 | 0.0349803 | 0.0517511 | 0.0415571 | 0.0005344 | 0.0318563 | 0.0206347 | 0.0218267 | 0.0152088 | 0.0011098 | 0.0009865 | 0.0107284 | 0.0001644 |
| E09000025 | 0.0443489 | 0.0029330 | 0.0243489 | 0.0040202 | 0.0653097 | 0.0060430 | 0.0018710 | 0.0201770 | 0.0310999 | 0.0305689 | 0.0001517 | 0.0287737 | 0.0136030 | 0.0141087 | 0.0113780 | 0.0001264 | 0.0010619 | 0.0068015 | 0.0001517 |
| E09000026 | 0.0483713 | 0.0060341 | 0.0313726 | 0.0041454 | 0.0177836 | 0.0118475 | 0.0019133 | 0.0443240 | 0.0351011 | 0.0608320 | 0.0003434 | 0.0384615 | 0.0226403 | 0.0095418 | 0.0106211 | 0.0001962 | 0.0008830 | 0.0094192 | 0.0001472 |
| E09000027 | 0.0492061 | 0.0080081 | 0.0828589 | 0.0082396 | 0.0301810 | 0.0121742 | 0.0049067 | 0.0392075 | 0.0431422 | 0.0453641 | 0.0007406 | 0.0244410 | 0.0208767 | 0.0152294 | 0.0154145 | 0.0006018 | 0.0010647 | 0.0200435 | 0.0002314 |
| E09000028 | 0.0530189 | 0.0184414 | 0.0437391 | 0.0094275 | 0.0362030 | 0.0226084 | 0.0137424 | 0.0285782 | 0.0310016 | 0.0226084 | 0.0004433 | 0.0282235 | 0.0125307 | 0.0165204 | 0.0143630 | 0.0043148 | 0.0039306 | 0.0142152 | 0.0001773 |
| E09000029 | 0.0425879 | 0.0045226 | 0.0459799 | 0.0059673 | 0.0157663 | 0.0069724 | 0.0035176 | 0.0339824 | 0.0466080 | 0.0415829 | 0.0005025 | 0.0298995 | 0.0246859 | 0.0138191 | 0.0140704 | 0.0002513 | 0.0020101 | 0.0120603 | 0.0000628 |
| E09000030 | 0.0652078 | 0.0159285 | 0.0484445 | 0.0199271 | 0.0342956 | 0.0172467 | 0.0089199 | 0.0253977 | 0.0509271 | 0.0293084 | 0.0007250 | 0.0367343 | 0.0160603 | 0.0187187 | 0.0393927 | 0.0019554 | 0.0097109 | 0.0105457 | 0.0001977 |
| E09000031 | 0.0310170 | 0.0067606 | 0.0308121 | 0.0036876 | 0.0120052 | 0.0036057 | 0.0014750 | 0.0304024 | 0.0251168 | 0.0375727 | 0.0002049 | 0.0402360 | 0.0259772 | 0.0095059 | 0.0092190 | 0.0006556 | 0.0009424 | 0.0093420 | 0.0000410 |
| E09000032 | 0.0381731 | 0.0072472 | 0.0655832 | 0.0074624 | 0.0180461 | 0.0091845 | 0.0041976 | 0.0402540 | 0.0311771 | 0.0355900 | 0.0003946 | 0.0311771 | 0.0202346 | 0.0123417 | 0.0119470 | 0.0008969 | 0.0018297 | 0.0158935 | 0.0000359 |
| E09000033 | 0.0871492 | 0.0369990 | 0.0475242 | 0.0180250 | 0.0727706 | 0.0228702 | 0.0137720 | 0.0385974 | 0.0192951 | 0.0375056 | 0.0004424 | 0.0307623 | 0.0292781 | 0.0150850 | 0.0143358 | 0.0047239 | 0.0074997 | 0.0153490 | 0.0001570 |
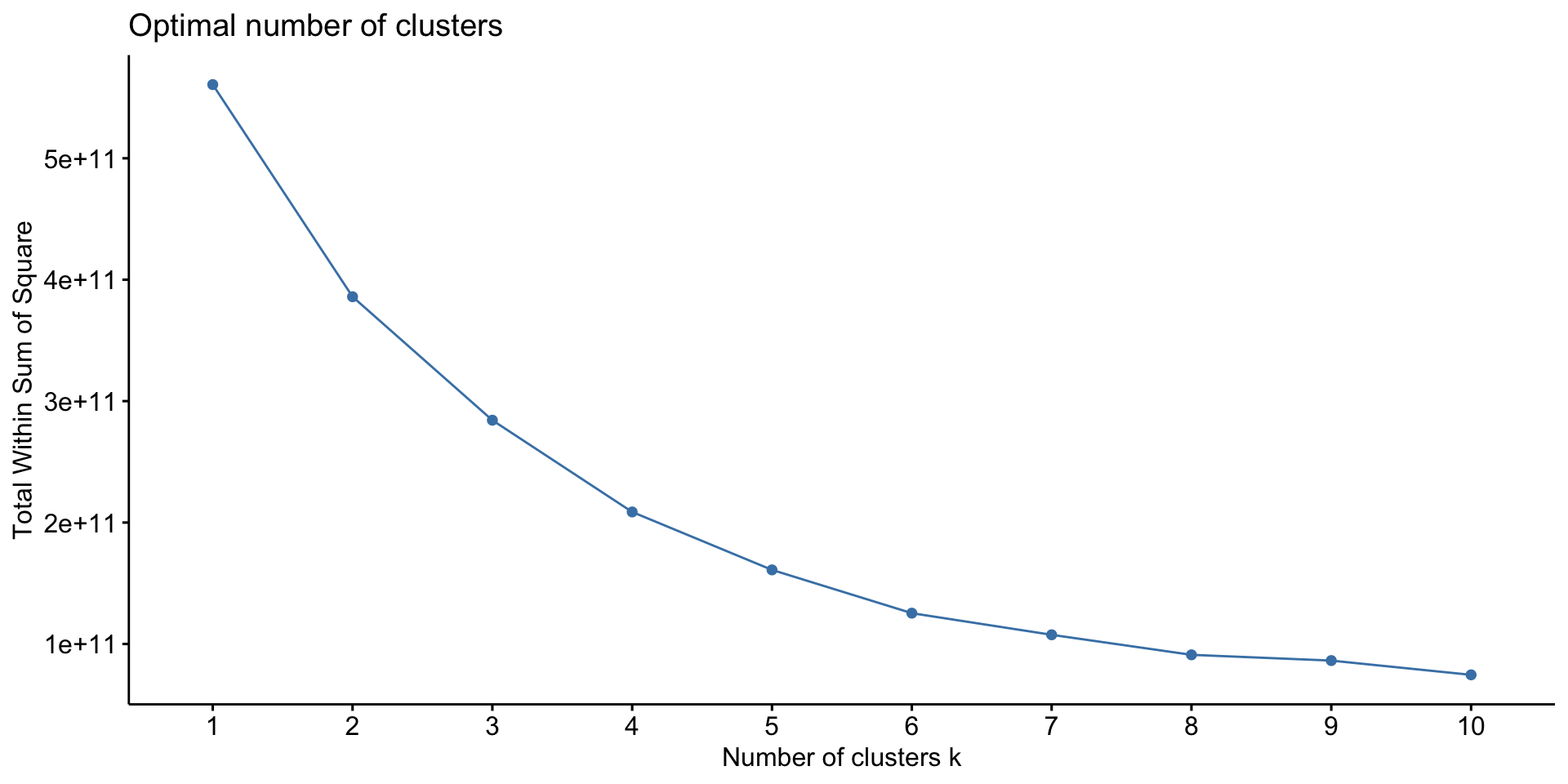
kclust is the object with the output of the \(k=10\) k-means function. After looking at its structure with str(kclust), there are two useful thing to do:
List of 9
$ cluster : int [1:33] 10 3 6 9 3 1 5 8 3 8 ...
$ centers : num [1:10, 1:1036] 0.0444 0.0443 0.0361 0.0591 0.0521 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:10] "1" "2" "3" "4" ...
.. ..$ : chr [1:1036] "82990 - Other business support service activities n.e.c." "64209 - Activities of other holding companies n.e.c." "70229 - Management consultancy activities other than financial management" "64999 - Financial intermediation not elsewhere classified" ...
$ totss : num 0.0945
$ withinss : num [1:10] 0.0042 0 0.00609 0.00112 0.0019 ...
$ tot.withinss: num 0.0235
$ betweenss : num 0.071
$ size : int [1:10] 6 1 8 2 3 3 1 2 5 2
$ iter : int 3
$ ifault : int 0
- attr(*, "class")= chr "kmeans"First, the list cluster contains the \(k = 10\) cluster solution. This is an array with a length of 33. The first entry is the cluster membership for the first LA, the second entry for the second LA etc.
Secondly, the list centers contains the centres of the new clusters. In other words, the average frequency of each SIC code (i.e. sector) for the 10 new clusters. centers is a \(10*1036\) table, with 1036 being the number of SIC codes. We can use these centres to create labels (aka pen portraits) for each cluster. These are, in essence, brief descriptions of the clusters.
kclust$centers %>% as.tibble() %>% # convert to tibble
mutate(cluster = (1:10)) %>% # create a Cluster ID column ...
relocate(cluster) %>% # ... and bring it in the first position
kbl() %>% # Create a nice(r) table
kable_styling(full_width = F, font_size = 11) %>%
scroll_box(width = "1200px", height = "800px")| cluster | 82990 - Other business support service activities n.e.c. | 64209 - Activities of other holding companies n.e.c. | 70229 - Management consultancy activities other than financial management | 64999 - Financial intermediation not elsewhere classified | 99999 - Dormant Company | 74990 - Non-trading company | 70100 - Activities of head offices | 68209 - Other letting and operating of own or leased real estate | 62020 - Information technology consultancy activities | 68100 - Buying and selling of own real estate | 65120 - Non-life insurance | 96090 - Other service activities n.e.c. | 41100 - Development of building projects | 62012 - Business and domestic software development | 62090 - Other information technology service activities | 35110 - Production of electricity | 64205 - Activities of financial services holding companies | 74909 - Other professional, scientific and technical activities n.e.c. | 65110 - Life insurance | 47910 - Retail sale via mail order houses or via Internet | 68320 - Management of real estate on a fee or contract basis | 78109 - Other activities of employment placement agencies | 66300 - Fund management activities | 66220 - Activities of insurance agents and brokers | 98000 - Residents property management | 63990 - Other information service activities n.e.c. | 59111 - Motion picture production activities | 46190 - Agents involved in the sale of a variety of goods | 66190 - Activities auxiliary to financial intermediation n.e.c. | 73110 - Advertising agencies | 86900 - Other human health activities | 69102 - Solicitors | 70221 - Financial management | 66290 - Other activities auxiliary to insurance and pension funding | 85590 - Other education n.e.c. | 56101 - Licensed restaurants | 90030 - Artistic creation | 46900 - Non-specialised wholesale trade | 58290 - Other software publishing | 69201 - Accounting and auditing activities | 64301 - Activities of investment trusts | 55100 - Hotels and similar accommodation | 61900 - Other telecommunications activities | 70210 - Public relations and communications activities | 78200 - Temporary employment agency activities | 59200 - Sound recording and music publishing activities | 93199 - Other sports activities | 64303 - Activities of venture and development capital companies | 43999 - Other specialised construction activities n.e.c. | 63110 - Data processing, hosting and related activities | 74100 - specialised design activities | 69109 - Activities of patent and copyright agents; other legal activities n.e.c. | 47710 - Retail sale of clothing in specialised stores | 63120 - Web portals | 94990 - Activities of other membership organizations n.e.c. | 85600 - Educational support services | 47990 - Other retail sale not in stores, stalls or markets | 59113 - Television programme production activities | 68310 - Real estate agencies | 58190 - Other publishing activities | 79110 - Travel agency activities | 41201 - Construction of commercial buildings | 71111 - Architectural activities | 64991 - Security dealing on own account | 82110 - Combined office administrative service activities | 06100 - Extraction of crude petroleum | 72110 - Research and experimental development on biotechnology | 66120 - Security and commodity contracts dealing activities | 90010 - Performing arts | 64922 - Activities of mortgage finance companies | 86220 - Specialists medical practice activities | 78300 - Human resources provision and management of human resources functions | 72190 - Other research and experimental development on natural sciences and engineering | 41202 - Construction of domestic buildings | 64304 - Activities of open-ended investment companies | 58110 - Book publishing | 62011 - Ready-made interactive leisure and entertainment software development | 90020 - Support activities to performing arts | 71122 - Engineering related scientific and technical consulting activities | 56302 - Public houses and bars | 59112 - Video production activities | 71129 - Other engineering activities | 88990 - Other social work activities without accommodation n.e.c. | 64306 - Activities of real estate investment trusts | 94120 - Activities of professional membership organizations | 96020 - Hairdressing and other beauty treatment | 50200 - Sea and coastal freight water transport | 46180 - Agents specialized in the sale of other particular products | 47190 - Other retail sale in non-specialised stores | 56290 - Other food services | 64202 - Activities of production holding companies | 32990 - Other manufacturing n.e.c. | 64191 - Banks | 73120 - Media representation services | 93290 - Other amusement and recreation activities n.e.c. | 52290 - Other transportation support activities | 66110 - Administration of financial markets | 09100 - Support activities for petroleum and natural gas extraction | 68201 - Renting and operating of Housing Association real estate | 64910 - Financial leasing | 86101 - Hospital activities | 46420 - Wholesale of clothing and footwear | 56103 - Take-away food shops and mobile food stands | 7499 - Non-trading company | 94110 - Activities of business and employers membership organizations | 43210 - Electrical installation | 43390 - Other building completion and finishing | 56102 - Unlicensed restaurants and cafes | 65300 - Pension funding | 58142 - Publishing of consumer and business journals and periodicals | 69101 - Barristers at law | 46342 - Wholesale of wine, beer, spirits and other alcoholic beverages | 55900 - Other accommodation | 64929 - Other credit granting n.e.c. | 49410 - Freight transport by road | 87100 - Residential nursing care facilities | 74901 - Environmental consulting activities | 61200 - Wireless telecommunications activities | 7487 - Other business activities | 08990 - Other mining and quarrying n.e.c. | 73200 - Market research and public opinion polling | 46510 - Wholesale of computers, computer peripheral equipment and software | 69203 - Tax consultancy | 61100 - Wired telecommunications activities | 14190 - Manufacture of other wearing apparel and accessories n.e.c. | 43290 - Other construction installation | 18129 - Printing n.e.c. | 71121 - Engineering design activities for industrial process and production | 46450 - Wholesale of perfume and cosmetics | 86210 - General medical practice activities | 46160 - Agents involved in the sale of textiles, clothing, fur, footwear and leather goods | 46460 - Wholesale of pharmaceutical goods | 47750 - Retail sale of cosmetic and toilet articles in specialised stores | 80100 - Private security activities | 92000 - Gambling and betting activities | 64921 - Credit granting by non-deposit taking finance houses and other specialist consumer credit grantors | 77351 - Renting and leasing of air passenger transport equipment | 81100 - Combined facilities support activities | 79120 - Tour operator activities | 93130 - Fitness facilities | 42990 - Construction of other civil engineering projects n.e.c. | 47789 - Other retail sale of new goods in specialised stores (not commercial art galleries and opticians) | 56210 - Event catering activities | 65202 - Non-life reinsurance | 69202 - Bookkeeping activities | 07290 - Mining of other non-ferrous metal ores | 45200 - Maintenance and repair of motor vehicles | 77400 - Leasing of intellectual property and similar products, except copyright works | 85520 - Cultural education | 35210 - Manufacture of gas | 59120 - Motion picture, video and television programme post-production activities | 79909 - Other reservation service activities n.e.c. | 46520 - Wholesale of electronic and telecommunications equipment and parts | 43220 - Plumbing, heat and air-conditioning installation | 66210 - Risk and damage evaluation | 87300 - Residential care activities for the elderly and disabled | 45112 - Sale of used cars and light motor vehicles | 47770 - Retail sale of watches and jewellery in specialised stores | 47781 - Retail sale in commercial art galleries | 71200 - Technical testing and analysis | 35140 - Trade of electricity | 60200 - Television programming and broadcasting activities | 85320 - Technical and vocational secondary education | 86230 - Dental practice activities | 46499 - Wholesale of household goods (other than musical instruments) n.e.c. | 55209 - Other holiday and other collective accommodation | 90040 - Operation of arts facilities | 32500 - Manufacture of medical and dental instruments and supplies | 45310 - Wholesale trade of motor vehicle parts and accessories | 46170 - Agents involved in the sale of food, beverages and tobacco | 46320 - Wholesale of meat and meat products | 58210 - Publishing of computer games | 64203 - Activities of construction holding companies | 85310 - General secondary education | 46370 - Wholesale of coffee, tea, cocoa and spices | 46760 - Wholesale of other intermediate products | 47599 - Retail of furniture, lighting, and similar (not musical instruments or scores) in specialised store | 81210 - General cleaning of buildings | 94910 - Activities of religious organizations | 46690 - Wholesale of other machinery and equipment | 62030 - Computer facilities management activities | 10890 - Manufacture of other food products n.e.c. | 35130 - Distribution of electricity | 64204 - Activities of distribution holding companies | 7415 - Holding Companies including Head Offices | 93110 - Operation of sports facilities | 46140 - Agents involved in the sale of machinery, industrial equipment, ships and aircraft | 46150 - Agents involved in the sale of furniture, household goods, hardware and ironmongery | 47290 - Other retail sale of food in specialised stores | 74902 - Quantity surveying activities | 77390 - Renting and leasing of other machinery, equipment and tangible goods n.e.c. | 85200 - Primary education | 4521 - Gen construction & civil engineer | 46410 - Wholesale of textiles | 46480 - Wholesale of watches and jewellery | 46719 - Wholesale of other fuels and related products | 47640 - Retail sale of sports goods, fishing gear, camping goods, boats and bicycles | 99000 - Activities of extraterritorial organizations and bodies | 45111 - Sale of new cars and light motor vehicles | 82302 - Activities of conference organisers | 87900 - Other residential care activities n.e.c. | 46720 - Wholesale of metals and metal ores | 52230 - Service activities incidental to air transportation | 59131 - Motion picture distribution activities | 42220 - Construction of utility projects for electricity and telecommunications | 46390 - Non-specialised wholesale of food, beverages and tobacco | 77110 - Renting and leasing of cars and light motor vehicles | 09900 - Support activities for other mining and quarrying | 72200 - Research and experimental development on social sciences and humanities | 93120 - Activities of sport clubs | 21100 - Manufacture of basic pharmaceutical products | 21200 - Manufacture of pharmaceutical preparations | 46120 - Agents involved in the sale of fuels, ores, metals and industrial chemicals | 47110 - Retail sale in non-specialised stores with food, beverages or tobacco predominating | 52219 - Other service activities incidental to land transportation, n.e.c. | 61300 - Satellite telecommunications activities | 71112 - Urban planning and landscape architectural activities | 74300 - Translation and interpretation activities | 26110 - Manufacture of electronic components | 7414 - Business & management consultancy | 96040 - Physical well-being activities | 01110 - Growing of cereals (except rice), leguminous crops and oil seeds | 49420 - Removal services | 82301 - Activities of exhibition and fair organisers | 85510 - Sports and recreation education | 01500 - Mixed farming | 51102 - Non-scheduled passenger air transport | 52103 - Operation of warehousing and storage facilities for land transport activities | 52220 - Service activities incidental to water transportation | 58130 - Publishing of newspapers | 64201 - Activities of agricultural holding companies | 20590 - Manufacture of other chemical products n.e.c. | 25990 - Manufacture of other fabricated metal products n.e.c. | 26511 - Manufacture of electronic measuring, testing etc. equipment, not for industrial process control | 39000 - Remediation activities and other waste management services | 46310 - Wholesale of fruit and vegetables | 46380 - Wholesale of other food, including fish, crustaceans and molluscs | 47721 - Retail sale of footwear in specialised stores | 47749 - Retail sale of medical and orthopaedic goods in specialised stores (not incl. hearing aids) n.e.c. | 80200 - Security systems service activities | 80300 - Investigation activities | 26200 - Manufacture of computers and peripheral equipment | 28990 - Manufacture of other special-purpose machinery n.e.c. | 43330 - Floor and wall covering | 22290 - Manufacture of other plastic products | 25110 - Manufacture of metal structures and parts of structures | 33200 - Installation of industrial machinery and equipment | 46470 - Wholesale of furniture, carpets and lighting equipment | 47791 - Retail sale of antiques including antique books in stores | 49320 - Taxi operation | 7011 - Development & sell real estate | 85421 - First-degree level higher education | 31090 - Manufacture of other furniture | 32120 - Manufacture of jewellery and related articles | 46750 - Wholesale of chemical products | 49100 - Passenger rail transport, interurban | 11010 - Distilling, rectifying and blending of spirits | 26400 - Manufacture of consumer electronics | 27400 - Manufacture of electric lighting equipment | 35120 - Transmission of electricity | 38320 - Recovery of sorted materials | 56301 - Licensed clubs | 74202 - Other specialist photography | 81300 - Landscape service activities | 85100 - Pre-primary education | 10710 - Manufacture of bread; manufacture of fresh pastry goods and cakes | 11050 - Manufacture of beer | 38110 - Collection of non-hazardous waste | 50100 - Sea and coastal passenger water transport | 81222 - Specialised cleaning services | 14132 - Manufacture of other women's outerwear | 36000 - Water collection, treatment and supply | 46439 - Wholesale of radio, television goods & electrical household appliances (other than records, tapes, CD's & video tapes and the equipment used for playing them) | 46711 - Wholesale of petroleum and petroleum products | 47410 - Retail sale of computers, peripheral units and software in specialised stores | 81299 - Other cleaning services | 96010 - Washing and (dry-)cleaning of textile and fur products | 10390 - Other processing and preserving of fruit and vegetables | 27900 - Manufacture of other electrical equipment | 31010 - Manufacture of office and shop furniture | 42110 - Construction of roads and motorways | 45320 - Retail trade of motor vehicle parts and accessories | 47540 - Retail sale of electrical household appliances in specialised stores | 59132 - Video distribution activities | 64302 - Activities of unit trusts | 82200 - Activities of call centres | 01430 - Raising of horses and other equines | 20420 - Manufacture of perfumes and toilet preparations | 33190 - Repair of other equipment | 47250 - Retail sale of beverages in specialised stores | 49390 - Other passenger land transport | 51101 - Scheduled passenger air transport | 58141 - Publishing of learned journals | 59133 - Television programme distribution activities | 74201 - Portrait photographic activities | 82190 - Photocopying, document preparation and other specialised office support activities | 84110 - General public administration activities | 96030 - Funeral and related activities | 27120 - Manufacture of electricity distribution and control apparatus | 43910 - Roofing activities | 47240 - Retail sale of bread, cakes, flour confectionery and sugar confectionery in specialised stores | 47610 - Retail sale of books in specialised stores | 53202 - Unlicensed carrier | 60100 - Radio broadcasting | 74209 - Photographic activities not elsewhere classified | 77320 - Renting and leasing of construction and civil engineering machinery and equipment | 77330 - Renting and leasing of office machinery and equipment (including computers) | 78101 - Motion picture, television and other theatrical casting activities | 87200 - Residential care activities for learning difficulties, mental health and substance abuse | 02100 - Silviculture and other forestry activities | 06200 - Extraction of natural gas | 11070 - Manufacture of soft drinks; production of mineral waters and other bottled waters | 13990 - Manufacture of other textiles n.e.c. | 15120 - Manufacture of luggage, handbags and the like, saddlery and harness | 16230 - Manufacture of other builders' carpentry and joinery | 18130 - Pre-press and pre-media services | 29100 - Manufacture of motor vehicles | 30300 - Manufacture of air and spacecraft and related machinery | 38210 - Treatment and disposal of non-hazardous waste | 43320 - Joinery installation | 46110 - Agents selling agricultural raw materials, livestock, textile raw materials and semi-finished goods | 46130 - Agents involved in the sale of timber and building materials | 46341 - Wholesale of fruit and vegetable juices, mineral water and soft drinks | 46730 - Wholesale of wood, construction materials and sanitary equipment | 47650 - Retail sale of games and toys in specialised stores | 47820 - Retail sale via stalls and markets of textiles, clothing and footwear | 47890 - Retail sale via stalls and markets of other goods | 75000 - Veterinary activities | 85422 - Post-graduate level higher education | 88100 - Social work activities without accommodation for the elderly and disabled | 14131 - Manufacture of other men's outerwear | 20130 - Manufacture of other inorganic basic chemicals | 32409 - Manufacture of other games and toys, n.e.c. | 33140 - Repair of electrical equipment | 43341 - Painting | 45190 - Sale of other motor vehicles | 46220 - Wholesale of flowers and plants | 47510 - Retail sale of textiles in specialised stores | 47730 - Dispensing chemist in specialised stores | 47782 - Retail sale by opticians | 47799 - Retail sale of other second-hand goods in stores (not incl. antiques) | 55201 - Holiday centres and villages | 65201 - Life reinsurance | 84120 - Regulation of health care, education, cultural and other social services, not incl. social security | 84230 - Justice and judicial activities | 9305 - Other service activities n.e.c. | 97000 - Activities of households as employers of domestic personnel | 03110 - Marine fishing | 10832 - Production of coffee and coffee substitutes | 17120 - Manufacture of paper and paperboard | 20140 - Manufacture of other organic basic chemicals | 20411 - Manufacture of soap and detergents | 24410 - Precious metals production | 28290 - Manufacture of other general-purpose machinery n.e.c. | 32300 - Manufacture of sports goods | 35230 - Trade of gas through mains | 43342 - Glazing | 47429 - Retail sale of telecommunications equipment other than mobile telephones | 47722 - Retail sale of leather goods in specialised stores | 47760 - Retail sale of flowers, plants, seeds, fertilizers, pet animals and pet food in specialised stores | 49200 - Freight rail transport | 63910 - News agency activities | 64110 - Central banking | 6523 - Other financial intermediation | 86102 - Medical nursing home activities | 18203 - Reproduction of computer media | 19201 - Mineral oil refining | 29310 - Manufacture of electrical and electronic equipment for motor vehicles and their engines | 43120 - Site preparation | 43310 - Plastering | 46330 - Wholesale of dairy products, eggs and edible oils and fats | 46740 - Wholesale of hardware, plumbing and heating equipment and supplies | 47430 - Retail sale of audio and video equipment in specialised stores | 51210 - Freight air transport | 53201 - Licensed carriers | 55300 - Recreational vehicle parks, trailer parks and camping grounds | 77342 - Renting and leasing of freight water transport equipment | 82911 - Activities of collection agencies | 82920 - Packaging activities | 91030 - Operation of historical sites and buildings and similar visitor attractions | 01610 - Support activities for crop production | 02400 - Support services to forestry | 10821 - Manufacture of cocoa and chocolate confectionery | 10831 - Tea processing | 10840 - Manufacture of condiments and seasonings | 14120 - Manufacture of workwear | 15200 - Manufacture of footwear | 17230 - Manufacture of paper stationery | 18201 - Reproduction of sound recording | 20301 - Manufacture of paints, varnishes and similar coatings, mastics and sealants | 24450 - Other non-ferrous metal production | 25620 - Machining | 26120 - Manufacture of loaded electronic boards | 26512 - Manufacture of electronic industrial process control equipment | 28131 - Manufacture of pumps | 46210 - Wholesale of grain, unmanufactured tobacco, seeds and animal feeds | 46660 - Wholesale of other office machinery and equipment | 46770 - Wholesale of waste and scrap | 47620 - Retail sale of newspapers and stationery in specialised stores | 47630 - Retail sale of music and video recordings in specialised stores | 77341 - Renting and leasing of passenger water transport equipment | 84130 - Regulation of and contribution to more efficient operation of businesses | 84240 - Public order and safety activities | 84250 - Fire service activities | 85410 - Post-secondary non-tertiary education | 91012 - Archives activities | 95110 - Repair of computers and peripheral equipment | 08910 - Mining of chemical and fertilizer minerals | 10850 - Manufacture of prepared meals and dishes | 13100 - Preparation and spinning of textile fibres | 27110 - Manufacture of electric motors, generators and transformers | 27320 - Manufacture of other electronic and electric wires and cables | 42120 - Construction of railways and underground railways | 4525 - Other special trades construction | 46360 - Wholesale of sugar and chocolate and sugar confectionery | 46610 - Wholesale of agricultural machinery, equipment and supplies | 47220 - Retail sale of meat and meat products in specialised stores | 49319 - Other urban, suburban or metropolitan passenger land transport (not underground, metro or similar) | 64305 - Activities of property unit trusts | 6512 - Other monetary intermediation | 79901 - Activities of tourist guides | 84220 - Defence activities | 93191 - Activities of racehorse owners | 01130 - Growing of vegetables and melons, roots and tubers | 05102 - Open cast coal working | 10410 - Manufacture of oils and fats | 13300 - Finishing of textiles | 13921 - Manufacture of soft furnishings | 17290 - Manufacture of other articles of paper and paperboard n.e.c. | 20150 - Manufacture of fertilizers and nitrogen compounds | 22220 - Manufacture of plastic packing goods | 23190 - Manufacture and processing of other glass, including technical glassware | 23700 - Cutting, shaping and finishing of stone | 24100 - Manufacture of basic iron and steel and of ferro-alloys | 25610 - Treatment and coating of metals | 30110 - Building of ships and floating structures | 30120 - Building of pleasure and sporting boats | 33120 - Repair of machinery | 33150 - Repair and maintenance of ships and boats | 35220 - Distribution of gaseous fuels through mains | 3614 - Manufacture of other furniture | 43991 - Scaffold erection | 46431 - Wholesale of audio tapes, records, CDs and video tapes and the equipment on which these are played | 46650 - Wholesale of office furniture | 47210 - Retail sale of fruit and vegetables in specialised stores | 47530 - Retail sale of carpets, rugs, wall and floor coverings in specialised stores | 52101 - Operation of warehousing and storage facilities for water transport activities | 58120 - Publishing of directories and mailing lists | 74203 - Film processing | 88910 - Child day-care activities | 91020 - Museums activities | 91040 - Botanical and zoological gardens and nature reserves activities | 95210 - Repair of consumer electronics | 01280 - Growing of spices, aromatic, drug and pharmaceutical crops | 01300 - Plant propagation | 01410 - Raising of dairy cattle | 01629 - Support activities for animal production (other than farm animal boarding and care) n.e.c. | 01630 - Post-harvest crop activities | 01700 - Hunting, trapping and related service activities | 05101 - Deep coal mines | 07100 - Mining of iron ores | 07210 - Mining of uranium and thorium ores | 10612 - Manufacture of breakfast cereals and cereals-based food | 10860 - Manufacture of homogenized food preparations and dietetic food | 13950 - Manufacture of non-wovens and articles made from non-wovens, except apparel | 13960 - Manufacture of other technical and industrial textiles | 14142 - Manufacture of women's underwear | 18202 - Reproduction of video recording | 20200 - Manufacture of pesticides and other agrochemical products | 22110 - Manufacture of rubber tyres and tubes; retreading and rebuilding of rubber tyres | 2213 - Publish journals & periodicals | 23610 - Manufacture of concrete products for construction purposes | 26301 - Manufacture of telegraph and telephone apparatus and equipment | 26309 - Manufacture of communication equipment other than telegraph, and telephone apparatus and equipment | 27310 - Manufacture of fibre optic cables | 28110 - Manufacture of engines and turbines, except aircraft, vehicle and cycle engines | 28140 - Manufacture of taps and valves | 28150 - Manufacture of bearings, gears, gearing and driving elements | 28220 - Manufacture of lifting and handling equipment | 2852 - General mechanical engineering | 2875 - Manufacture other fabricated metal products | 29320 - Manufacture of other parts and accessories for motor vehicles | 30200 - Manufacture of railway locomotives and rolling stock | 30920 - Manufacture of bicycles and invalid carriages | 31020 - Manufacture of kitchen furniture | 33130 - Repair of electronic and optical equipment | 33160 - Repair and maintenance of aircraft and spacecraft | 33170 - Repair and maintenance of other transport equipment n.e.c. | 38220 - Treatment and disposal of hazardous waste | 46350 - Wholesale of tobacco products | 46620 - Wholesale of machine tools | 46630 - Wholesale of mining, construction and civil engineering machinery | 47421 - Retail sale of mobile telephones | 47591 - Retail sale of musical instruments and scores | 5190 - Other wholesale | 52243 - Cargo handling for land transport activities | 6024 - Freight transport by road | 64992 - Factoring | 68202 - Letting and operating of conference and exhibition centres | 7220 - Software consultancy and supply | 77291 - Renting and leasing of media entertainment equipment | 98200 - Undifferentiated service-producing activities of private households for own use | 9999 - Dormant company | 01250 - Growing of other tree and bush fruits and nuts | 01420 - Raising of other cattle and buffaloes | 01621 - Farm animal boarding and care | 10200 - Processing and preserving of fish, crustaceans and molluscs | 10730 - Manufacture of macaroni, noodles, couscous and similar farinaceous products | 11020 - Manufacture of wine from grape | 11040 - Manufacture of other non-distilled fermented beverages | 12000 - Manufacture of tobacco products | 13923 - manufacture of household textiles | 16210 - Manufacture of veneer sheets and wood-based panels | 17220 - Manufacture of household and sanitary goods and of toilet requisites | 19209 - Other treatment of petroleum products (excluding petrochemicals manufacture) | 20110 - Manufacture of industrial gases | 20412 - Manufacture of cleaning and polishing preparations | 22190 - Manufacture of other rubber products | 2222 - Printing not elsewhere classified | 23410 - Manufacture of ceramic household and ornamental articles | 25720 - Manufacture of locks and hinges | 25730 - Manufacture of tools | 25930 - Manufacture of wire products, chain and springs | 26520 - Manufacture of watches and clocks | 26701 - Manufacture of optical precision instruments | 26702 - Manufacture of photographic and cinematographic equipment | 28490 - Manufacture of other machine tools | 28940 - Manufacture of machinery for textile, apparel and leather production | 29201 - Manufacture of bodies (coachwork) for motor vehicles (except caravans) | 3162 - Manufacture other electrical equipment | 32130 - Manufacture of imitation jewellery and related articles | 33110 - Repair of fabricated metal products | 35300 - Steam and air conditioning supply | 3663 - Other manufacturing | 42130 - Construction of bridges and tunnels | 4534 - Other building installation | 45400 - Sale, maintenance and repair of motorcycles and related parts and accessories | 5010 - Sale of motor vehicles | 50300 - Inland passenger water transport | 5142 - Wholesale of clothing and footwear | 52102 - Operation of warehousing and storage facilities for air transport activities | 52241 - Cargo handling for water transport activities | 55202 - Youth hostels | 6330 - Travel agencies etc; tourist | 6420 - Telecommunications | 6603 - Non-life insurance/reinsurance | 7012 - Buying & sell own real estate | 7020 - Letting of own property | 7411 - Legal activities | 7440 - Advertising | 7450 - Labour recruitment | 77210 - Renting and leasing of recreational and sports goods | 81229 - Other building and industrial cleaning activities | 85530 - Driving school activities | 91011 - Library activities | 93210 - Activities of amusement parks and theme parks | 94200 - Activities of trade unions | 94920 - Activities of political organizations | 95220 - Repair of household appliances and home and garden equipment | 95250 - Repair of watches, clocks and jewellery | 01210 - Growing of grapes | 01290 - Growing of other perennial crops | 01490 - Raising of other animals | 03120 - Freshwater fishing | 10512 - Butter and cheese production | 10519 - Manufacture of other milk products | 10910 - Manufacture of prepared feeds for farm animals | 10920 - Manufacture of prepared pet foods | 13200 - Weaving of textiles | 14110 - Manufacture of leather clothes | 1589 - Manufacture of other food products | 18110 - Printing of newspapers | 18121 - Manufacture of printed labels | 20160 - Manufacture of plastics in primary forms | 20170 - Manufacture of synthetic rubber in primary forms | 2051 - Manufacture of other products of wood | 2121 - Manufacture of cartons, boxes & cases of corrugated paper & paperboard | 23510 - Manufacture of cement | 24200 - Manufacture of tubes, pipes, hollow profiles and related fittings, of steel | 24420 - Aluminium production | 2452 - Manufacture perfumes & toilet preparations | 2466 - Manufacture of other chemical products | 25120 - Manufacture of doors and windows of metal | 25940 - Manufacture of fasteners and screw machine products | 2625 - Manufacture of other ceramic products | 26600 - Manufacture of irradiation, electromedical and electrotherapeutic equipment | 27200 - Manufacture of batteries and accumulators | 27510 - Manufacture of electric domestic appliances | 28120 - Manufacture of fluid power equipment | 28930 - Manufacture of machinery for food, beverage and tobacco processing | 2954 - Manufacture for textile, apparel & leather | 30400 - Manufacture of military fighting vehicles | 30990 - Manufacture of other transport equipment n.e.c. | 42910 - Construction of water projects | 43110 - Demolition | 46230 - Wholesale of live animals | 46640 - Wholesale of machinery for the textile industry and of sewing and knitting machines | 47260 - Retail sale of tobacco products in specialised stores | 47300 - Retail sale of automotive fuel in specialised stores | 47520 - Retail sale of hardware, paints and glass in specialised stores | 49311 - Urban and suburban passenger railway transportation by underground, metro and similar systems | 49500 - Transport via pipeline | 5147 - Wholesale of other household goods | 5244 - Retail furniture household etc | 53100 - Postal activities under universal service obligation | 5510 - Hotels & motels with or without restaurant | 5530 - Restaurants | 6711 - Administration of financial markets | 7031 - Real estate agencies | 7412 - Accounting, auditing; tax consult | 77120 - Renting and leasing of trucks and other heavy vehicles | 77299 - Renting and leasing of other personal and household goods | 81291 - Disinfecting and exterminating services | 9220 - Radio and television activities | 9234 - Other entertainment activities | 9261 - Operate sports arenas & stadiums | 9271 - Gambling and betting activities | 95230 - Repair of footwear and leather goods | 95240 - Repair of furniture and home furnishings | 98100 - Undifferentiated goods-producing activities of private households for own use | 01240 - Growing of pome fruits and stone fruits | 01270 - Growing of beverage crops | 0141 - Agricultural service activities | 01440 - Raising of camels and camelids | 03210 - Marine aquaculture | 03220 - Freshwater aquaculture | 08110 - Quarrying of ornamental and building stone, limestone, gypsum, chalk and slate | 08920 - Extraction of peat | 10110 - Processing and preserving of meat | 10511 - Liquid milk and cream production | 10520 - Manufacture of ice cream | 10620 - Manufacture of starches and starch products | 10720 - Manufacture of rusks and biscuits; manufacture of preserved pastry goods and cakes | 10810 - Manufacture of sugar | 10822 - Manufacture of sugar confectionery | 11030 - Manufacture of cider and other fruit wines | 13910 - Manufacture of knitted and crocheted fabrics | 13931 - Manufacture of woven or tufted carpets and rugs | 13940 - Manufacture of cordage, rope, twine and netting | 15110 - Tanning and dressing of leather; dressing and dyeing of fur | 1533 - Process etc. fruit, vegetables | 1581 - Manufacture of bread, fresh pastry & cakes | 1596 - Manufacture of beer | 16100 - Sawmilling and planing of wood | 16240 - Manufacture of wooden containers | 16290 - Manufacture of other products of wood; manufacture of articles of cork, straw and plaiting materials | 17110 - Manufacture of pulp | 17211 - Manufacture of corrugated paper and paperboard, sacks and bags | 17240 - Manufacture of wallpaper | 1725 - Other textile weaving | 1730 - Finishing of textiles | 1752 - Manufacture cordage, rope, twine & netting | 18140 - Binding and related services | 1822 - Manufacture of other outerwear | 1824 - Manufacture other wearing apparel etc. | 2010 - Sawmill, plane, impregnation wood | 2030 - Manufacture builders' carpentry & joinery | 20302 - Manufacture of printing ink | 20510 - Manufacture of explosives | 20530 - Manufacture of essential oils | 2123 - Manufacture of paper stationery | 2125 - Manufacture of paper & paperboard goods | 2215 - Other publishing | 22210 - Manufacture of plastic plates, sheets, tubes and profiles | 22230 - Manufacture of builders ware of plastic | 23120 - Shaping and processing of flat glass | 23140 - Manufacture of glass fibres | 23200 - Manufacture of refractory products | 23310 - Manufacture of ceramic tiles and flags | 23630 - Manufacture of ready-mixed concrete | 23990 - Manufacture of other non-metallic mineral products n.e.c. | 24330 - Cold forming or folding | 24440 - Copper production | 2451 - Manufacture soap & detergents, polishes etc. | 24510 - Casting of iron | 25210 - Manufacture of central heating radiators and boilers | 25910 - Manufacture of steel drums and similar containers | 2611 - Manufacture of flat glass | 26513 - Manufacture of non-electronic measuring, testing etc. equipment, not for industrial process control | 2742 - Aluminium production | 28250 - Manufacture of non-domestic cooling and ventilation equipment | 28301 - Manufacture of agricultural tractors | 28302 - Manufacture of agricultural and forestry machinery other than tractors | 28960 - Manufacture of plastics and rubber machinery | 2924 - Manufacture of other general machinery | 2952 - Manufacture machines for mining, quarry etc. | 2971 - Manufacture of electric domestic appliances | 30910 - Manufacture of motorcycles | 32200 - Manufacture of musical instruments | 32401 - Manufacture of professional and arcade games and toys | 3310 - Manufacture medical, orthopaedic etc. equipment | 3350 - Manufacture of watches and clocks | 3420 - Manufacture motor vehicle bodies etc. | 3511 - Building and repairing of ships | 3612 - Manufacture other office & shop furniture | 38120 - Collection of hazardous waste | 43130 - Test drilling and boring | 4511 - Demolition buildings; earth moving | 4522 - Erection of roof covering & frames | 4531 - Installation electrical wiring etc. | 4532 - Insulation work activities | 4533 - Plumbing | 4543 - Floor and wall covering | 4550 - Rent construction equipment with operator | 46240 - Wholesale of hides, skins and leather | 46440 - Wholesale of china and glassware and cleaning materials | 46491 - Wholesale of musical instruments | 47230 - Retail sale of fish, crustaceans and molluscs in specialised stores | 5050 - Retail sale of automotive fuel | 5115 - Agents in household goods, etc. | 51220 - Space transport | 5134 - Wholesale of alcohol and other drinks | 5141 - Wholesale of textiles | 5143 - Wholesale electric household goods | 5154 - Wholesale hardware, plumbing etc. | 5170 - Other wholesale | 5212 - Other retail non-specialised stores | 52212 - Operation of rail passenger facilities at railway stations | 52213 - Operation of bus and coach passenger facilities at bus and coach stations | 5224 - Retail bread, cakes, confectionery | 52242 - Cargo handling for air transport activities | 5250 - Retail other secondhand goods | 59140 - Motion picture projection activities | 6010 - Transport via railways | 6312 - Storage & warehousing | 6323 - Other supporting air transport | 6340 - Other transport agencies | 6521 - Financial leasing | 6601 - Life insurance/reinsurance | 6712 - Security broking & fund management | 7032 - Manage real estate, fee or contract | 7134 - Rent other machinery & equip | 7222 - Other software consultancy and supply | 7260 - Other computer related activities | 7413 - Market research, opinion polling | 7484 - Other business activities | 8021 - General secondary education | 8042 - Adult and other education | 81221 - Window cleaning services | 82912 - Activities of credit bureaus | 9112 - Professional organisations | 9251 - Library and archives activities | 95120 - Repair of communication equipment | 95290 - Repair of personal and household goods n.e.c. | 47810 - Retail sale via stalls and markets of food, beverages and tobacco products | 17219 - Manufacture of other paper and paperboard containers | 23320 - Manufacture of bricks, tiles and construction products, in baked clay | 10130 - Production of meat and poultry meat products | 31030 - Manufacture of mattresses | 37000 - Sewerage | 38310 - Dismantling of wrecks | 01160 - Growing of fibre crops | 01450 - Raising of sheep and goats | 01470 - Raising of poultry | 02300 - Gathering of wild growing non-wood products | 10320 - Manufacture of fruit and vegetable juice | 1740 - Manufacture made-up textiles, not apparel | 2320 - Manufacture of refined petroleum products | 23620 - Manufacture of plaster products for construction purposes | 23690 - Manufacture of other articles of concrete, plaster and cement | 24520 - Casting of steel | 26514 - Manufacture of non-electronic industrial process control equipment | 27520 - Manufacture of non-electric domestic appliances | 28240 - Manufacture of power-driven hand tools | 3210 - Manufacture of electronic components | 42210 - Construction of utility projects for fluids | 4544 - Painting and glazing | 50400 - Inland freight water transport | 5144 - Wholesale of china, wallpaper etc. | 5152 - Wholesale of metals and metal ores | 64192 - Building societies | 7460 - Investigation & security | 84210 - Foreign affairs | 9211 - Motion picture and video production | 4545 - Other building completion | 5540 - Bars | 01190 - Growing of other non-perennial crops | 02200 - Logging | 8531 - Social work with accommodation | 08930 - Extraction of salt | 14390 - Manufacture of other knitted and crocheted apparel | 16220 - Manufacture of assembled parquet floors | 1823 - Manufacture of underwear | 23440 - Manufacture of other technical ceramic products | 28922 - Manufacture of earthmoving equipment | 32910 - Manufacture of brooms and brushes | 5131 - Wholesale of fruit and vegetables | 7420 - Architectural, technical consult | 77310 - Renting and leasing of agricultural machinery and equipment | 81223 - Furnace and chimney cleaning services | 8514 - Other human health activities | 9231 - Artistic & literary creation etc | 01120 - Growing of rice | 01460 - Raising of swine/pigs | 08120 - Operation of gravel and sand pits; mining of clays and kaolin | 10120 - Processing and preserving of poultry meat | 10611 - Grain milling | 11060 - Manufacture of malt | 13922 - manufacture of canvas goods, sacks, etc. | 13939 - Manufacture of other carpets and rugs | 14141 - Manufacture of men's underwear | 14200 - Manufacture of articles of fur | 1920 - Manufacture of luggage & the like, saddlery | 20120 - Manufacture of dyes and pigments | 2225 - Ancillary printing operations | 23110 - Manufacture of flat glass | 23490 - Manufacture of other ceramic products n.e.c. | 2415 - Manufacture fertilizers, nitrogen compounds | 2430 - Manufacture of paints, print ink & mastics etc. | 24430 - Lead, zinc and tin production | 24530 - Casting of light metals | 25290 - Manufacture of other tanks, reservoirs and containers of metal | 25300 - Manufacture of steam generators, except central heating hot water boilers | 25400 - Manufacture of weapons and ammunition | 25710 - Manufacture of cutlery | 25920 - Manufacture of light metal packaging | 26800 - Manufacture of magnetic and optical media | 2710 - Manufacture of basic iron & steel & of Ferro-alloys | 28410 - Manufacture of metal forming machinery | 29202 - Manufacture of trailers and semi-trailers | 2922 - Manufacture of lift & handling equipment | 3110 - Manufacture electric motors, generators etc. | 32110 - Striking of coins | 3622 - Manufacture of jewellery & related | 4523 - Construction roads, airfields etc. | 4542 - Joinery installation | 5114 - Agents in industrial equipment, etc. | 5145 - Wholesale of perfume and cosmetics | 5226 - Retail sale of tobacco products | 5227 - Other retail food etc. specialised | 5242 - Retail sale of clothing | 5245 - Retail electric h'hold, etc. goods | 7140 - Rent personal & household goods | 7210 - Hardware consultancy | 7221 - Software publishing | 7470 - Other cleaning activities | 7482 - Packaging activities | 8041 - Driving school activities | 84300 - Compulsory social security activities | 8512 - Medical practice activities | 8513 - Dental practice activities | 9500 - Private households with employees | 9800 - Residents property management | 5248 - Other retail specialist stores | 6022 - Taxi operation | 2212 - Publishing of newspapers | 25500 - Forging, pressing, stamping and roll-forming of metal; powder metallurgy | 27330 - Manufacture of wiring devices | 47741 - Retail sale of hearing aids | 5185 - Wholesale of other office machinery & equipment | 23430 - Manufacture of ceramic insulators and insulating fittings | 28923 - Manufacture of equipment for concrete crushing and screening and roadworks | 5231 - Dispensing chemists | 5247 - Retail books, newspapers etc. | 20520 - Manufacture of glues | 2112 - Manufacture of paper & paperboard | 2211 - Publishing of books | 24540 - Casting of other non-ferrous metals | 5020 - Maintenance & repair of motors | 5132 - Wholesale of meat and meat products | 5211 - Retail in non-specialised stores holding an alcohol licence, with food, beverages or tobacco predominating, not elsewhere classified | 5241 - Retail sale of textiles | 5552 - Catering | 77220 - Renting of video tapes and disks | 01220 - Growing of tropical and subtropical fruits | 10420 - Manufacture of margarine and similar edible fats | 2811 - Manufacture metal structures & parts | 28210 - Manufacture of ovens, furnaces and furnace burners | 28910 - Manufacture of machinery for metallurgy | 28921 - Manufacture of machinery for mining | 7110 - Renting of automobiles | 9272 - Other recreational activities nec | 5263 - Other non-store retail sale | 5186 - Wholesale of other electronic parts & equipment | 5184 - Wholesale of computers, computer peripheral equipment & software | 01640 - Seed processing for propagation | 1598 - Produce mineral water, soft drinks | 5261 - Retail sale via mail order houses | 9301 - Wash & dry clean textile & fur | 01230 - Growing of citrus fruits | 01260 - Growing of oleaginous fruits | 0130 - Crops combined with animals, mixed farms | 1010 - Mining & agglomeration of hard coal | 14310 - Manufacture of knitted and crocheted hosiery | 1717 - Preparation & spin of other textiles | 20600 - Manufacture of man-made fibres | 23520 - Manufacture of lime and plaster | 23910 - Production of abrasive products | 2513 - Manufacture of other rubber products | 2522 - Manufacture of plastic pack goods | 2524 - Manufacture of other plastic products | 2621 - Manufacture of ceramic household etc. goods | 2743 - Lead, zinc and tin production | 28132 - Manufacture of compressors | 28230 - Manufacture of office machinery and equipment (except computers and peripheral equipment) | 28950 - Manufacture of machinery for paper and paperboard production | 29203 - Manufacture of caravans | 2940 - Manufacture of machine tools | 2943 - Manufacture of other machine tools not elsewhere classified | 3630 - Manufacture of musical instruments | 4010 - Production | 4013 - Distribution & trade in electricity | 5111 - Agents agricultural & textile raw materials | 5116 - Agents in textiles, footwear etc. | 5118 - Agents in particular products | 5119 - Agents in sale of variety of goods | 5139 - Non-specialised wholesale food, etc. | 5153 - Wholesale wood, construction etc. | 5221 - Retail of fruit and vegetables | 52211 - Operation of rail freight terminals | 6120 - Inland water transport | 6210 - Scheduled air transport | 6322 - Other supporting water transport | 6511 - Central banking | 7230 - Data processing | 7240 - Data base activities | 7250 - Maintenance office & computing mach | 7430 - Technical testing and analysis | 7481 - Portrait photographic activities, other specialist photography, film processing | 8030 - Higher education | 9213 - Motion picture projection | 9262 - Other sporting activities | 9304 - Physical well-being activities | 23420 - Manufacture of ceramic sanitary fixtures | 0111 - Grow cereals & other crops | 05200 - Mining of lignite | 19100 - Manufacture of coke oven products | 23130 - Manufacture of hollow glass | 5113 - Agents in building materials | 5157 - Wholesale of waste and scrap | 9302 - Hairdressing & other beauty treatment | 10310 - Processing and preserving of potatoes | 1552 - Manufacture of ice cream | 3002 - Manufacture computers & process equipment | 6321 - Other supporting land transport | 6412 - Courier other than national post | 01150 - Growing of tobacco | 2923 - Manufacture non-domestic ventilation | 3140 - Manufacture of accumulators, batteries etc. | 3611 - Manufacture of chairs and seats | 4541 - Plastering | 5521 - Youth hostels and mountain refuges | 7122 - Rent water transport equipment | 7132 - Rent civil engineering machinery | 8022 - Technical & vocational secondary | 7133 - Rent office machinery inc computers | 01140 - Growing of sugar cane | 2956 - Manufacture other special purpose machine | 6023 - Other passenger land transport | 8532 - Social work without accommodation | 9003 - Sanitation remediation and similar activities | 1571 - Manufacture of prepared farm animal feeds | 5117 - Agents in food, drink & tobacco | 5156 - Wholesale other intermediate goods | 77352 - Renting and leasing of freight air transport equipment | 9600 - Undifferentiated goods producing activities of private households for own use | 24460 - Processing of nuclear fuel | 2862 - Manufacture of tools | 3520 - Manufacture of railway locomotives & stock | 5136 - Wholesale sugar, chocolate etc. | 5232 - Retail medical & orthopaedic goods | 3230 - Manufacture TV & radio, sound or video etc. | 5511 - Hotels & motels | 2874 - Manufacture fasteners, screw, chains etc. | 2416 - Manufacture of plastics in primary forms | 3410 - Manufacture of motor vehicles | 4012 - Transmission of electricity | 5225 - Retail alcoholic & other beverages | 5030 - Sale of motor vehicle parts etc. | 2851 - Treatment and coat metals | 5243 - Retail of footwear & leather goods | 1513 - Production meat & poultry products | 1583 - Manufacture of sugar | 1723 - Worsted-type weaving | 1910 - Tanning and dressing of leather | 2812 - Manufacture builders' carpentry of metal | 2912 - Manufacture of pumps & compressors | 3130 - Manufacture of insulated wire & cable | 4030 - Steam and hot water supply | 5138 - Wholesale other food inc fish, etc. | 5164 - Wholesale office machinery & equip | 5274 - Repair not elsewhere classified | 6311 - Cargo handling | 6411 - National post activities | 6522 - Other credit granting | 6713 - Auxiliary financial intermed | 8010 - Primary education | 2214 - Publishing of sound recordings | 9131 - Religious organisations | 0501 - Fishing | 23640 - Manufacture of mortars | 3320 - Manufacture instruments for measuring etc. | 5233 - Retail cosmetic & toilet articles | 7524 - Public security, law & order | 24310 - Cold drawing of bars | 5222 - Retail of meat and meat products | 5272 - Repair electrical household goods | 4020 - Mfr of gas; mains distribution | 3430 - Manufacture motor vehicle & engine parts | 2661 - Manufacture concrete goods for construction | 3710 - Recycling of metal waste and scrap | 3720 - Recycling non-metal waste & scrap | 6021 - Other scheduled passenger land transport | 6110 - Sea and coastal water transport | 7310 - R & d on nat sciences & engineering | 2223 - Bookbinding and finishing | 1110 - Extraction petroleum & natural gas | 2441 - Manufacture of basic pharmaceutical prods | 2681 - Production of abrasive products | 2821 - Manufacture tanks, etc. & metal containers | 3541 - Manufacture of motorcycles | 5135 - Wholesale of tobacco products | 5223 - Retail of fish, crustaceans etc. | 6720 - Auxiliary insurance & pension fund | 2413 - Manufacture other inorganic basic chemicals | 5146 - Wholesale of pharmaceutical goods | 0150 - Hunting and game rearing inc. services | 1320 - Mining non-ferrous metal ores | 1711 - Prepare & spin cotton-type fibres | 1713 - Prepare & spin worsted-type fibres | 1721 - Cotton-type weaving | 1751 - Manufacture of carpets and rugs | 2231 - Reproduction of sound recording | 23650 - Manufacture of fibre cement | 24340 - Cold drawing of wire | 2612 - Shaping & process of flat glass | 2733 - Cold forming or folding | 2873 - Manufacture of wire products | 3340 - Manufacture optical, photographic etc. equipment | 3640 - Manufacture of sports goods | 5112 - Agents in sale of fuels, ores, etc. | 6220 - Non-scheduled air transport | 7514 - Support services for government | 9002 - Collection and treatment of other waste | 9232 - Operation of arts facilities | 9303 - Funeral and related activities |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0443722 | 0.0097863 | 0.0574494 | 0.0073183 | 0.0216746 | 0.0103232 | 0.0054584 | 0.0390089 | 0.0326917 | 0.0372037 | 0.0005861 | 0.0305478 | 0.0197910 | 0.0134066 | 0.0130520 | 0.0013324 | 0.0016988 | 0.0158125 | 0.0001351 | 0.0214913 | 0.0152577 | 0.0054988 | 0.0020802 | 0.0010891 | 0.0534424 | 0.0052481 | 0.0072667 | 0.0033851 | 0.0016607 | 0.0074795 | 0.0144086 | 0.0023014 | 0.0055453 | 0.0006010 | 0.0073059 | 0.0114544 | 0.0078625 | 0.0054338 | 0.0019474 | 0.0106371 | 0.0006441 | 0.0034759 | 0.0016007 | 0.0050159 | 0.0022593 | 0.0053491 | 0.0042252 | 0.0011014 | 0.0066632 | 0.0015031 | 0.0101615 | 0.0017521 | 0.0060795 | 0.0021362 | 0.0020100 | 0.0044427 | 0.0063705 | 0.0046089 | 0.0071010 | 0.0039620 | 0.0028672 | 0.0056847 | 0.0054098 | 0.0009793 | 0.0023394 | 0.0006030 | 0.0007413 | 0.0005650 | 0.0046063 | 0.0005725 | 0.0040762 | 0.0022307 | 0.0011112 | 0.0114027 | 0.0012233 | 0.0028112 | 0.0017178 | 0.0028388 | 0.0029805 | 0.0027540 | 0.0052001 | 0.0033724 | 0.0035700 | 0.0004427 | 0.0006215 | 0.0110343 | 0.0004681 | 0.0018080 | 0.0054562 | 0.0052647 | 0.0002169 | 0.0021163 | 0.0004821 | 0.0025622 | 0.0028563 | 0.0017324 | 0.0004681 | 0.0005711 | 0.0010865 | 0.0003508 | 0.0026728 | 0.0029159 | 0.0083750 | 0.0001204 | 0.0006246 | 0.0060175 | 0.0068224 | 0.0067671 | 0.0001222 | 0.0011776 | 0.0001424 | 0.0018763 | 0.0030783 | 0.0004743 | 0.0034463 | 0.0006214 | 0.0011364 | 0.0005448 | 0.0003228 | 0.0001818 | 0.0014087 | 0.0008479 | 0.0007885 | 0.0005330 | 0.0017084 | 0.0035351 | 0.0011852 | 0.0011405 | 0.0013008 | 0.0036147 | 0.0024408 | 0.0006911 | 0.0017047 | 0.0020840 | 0.0002387 | 0.0002936 | 0.0000811 | 0.0015473 | 0.0014952 | 0.0024811 | 0.0018187 | 0.0018583 | 0.0040041 | 0.0000826 | 0.0028681 | 0.0001710 | 0.0030919 | 0.0003478 | 0.0017176 | 0.0000330 | 0.0017293 | 0.0010085 | 0.0008388 | 0.0056851 | 0.0002184 | 0.0009550 | 0.0031281 | 0.0013428 | 0.0009331 | 0.0006250 | 0.0003946 | 0.0010440 | 0.0005467 | 0.0027699 | 0.0008558 | 0.0007762 | 0.0008669 | 0.0004781 | 0.0004768 | 0.0007738 | 0.0002621 | 0.0006927 | 0.0003691 | 0.0007598 | 0.0007076 | 0.0003952 | 0.0015840 | 0.0035093 | 0.0011292 | 0.0003750 | 0.0006525 | 0.0013632 | 0.0000969 | 0.0001449 | 0.0000252 | 0.0009778 | 0.0004986 | 0.0008305 | 0.0016078 | 0.0012329 | 0.0006276 | 0.0014155 | 0.0001172 | 0.0007960 | 0.0005951 | 0.0000897 | 0.0012611 | 0.0004238 | 0.0005971 | 0.0006801 | 0.0007860 | 0.0002026 | 0.0001817 | 0.0002268 | 0.0004312 | 0.0007008 | 0.0008519 | 0.0002872 | 0.0005903 | 0.0015346 | 0.0001989 | 0.0000917 | 0.0004093 | 0.0042810 | 0.0003156 | 0.0000965 | 0.0006439 | 0.0007304 | 0.0001548 | 0.0000868 | 0.0023011 | 0.0000898 | 0.0012118 | 0.0008826 | 0.0017625 | 0.0003159 | 0.0004121 | 0.0006007 | 0.0000894 | 0.0003589 | 0.0000723 | 0.0000828 | 0.0003935 | 0.0001113 | 0.0003327 | 0.0010517 | 0.0004277 | 0.0003759 | 0.0004244 | 0.0008991 | 0.0002428 | 0.0002386 | 0.0002308 | 0.0012837 | 0.0002481 | 0.0001905 | 0.0002956 | 0.0004241 | 0.0006629 | 0.0024697 | 0.0001101 | 0.0002930 | 0.0008715 | 0.0009621 | 0.0001775 | 0.0001153 | 0.0004476 | 0.0003237 | 0.0002447 | 0.0000957 | 0.0001138 | 0.0003080 | 0.0011828 | 0.0024482 | 0.0021366 | 0.0011098 | 0.0003716 | 0.0011738 | 0.0001266 | 0.0010265 | 0.0005303 | 0.0002896 | 0.0002271 | 0.0000970 | 0.0005710 | 0.0017696 | 0.0015260 | 0.0001840 | 0.0001985 | 0.0001582 | 0.0004312 | 0.0005538 | 0.0003480 | 0.0002361 | 0.0000645 | 0.0001519 | 0.0001593 | 0.0003384 | 0.0006289 | 0.0007480 | 0.0012501 | 0.0001786 | 0.0001581 | 0.0001516 | 0.0006859 | 0.0002329 | 0.0003169 | 0.0002364 | 0.0000489 | 0.0012391 | 0.0009053 | 0.0004662 | 0.0007071 | 0.0004762 | 0.0012744 | 0.0002134 | 0.0000583 | 0.0003183 | 0.0007912 | 0.0001619 | 0.0001496 | 0.0002922 | 0.0002709 | 0.0002289 | 0.0007202 | 0.0003953 | 0.0001971 | 0.0000983 | 0.0002036 | 0.0013678 | 0.0002688 | 0.0002593 | 0.0004579 | 0.0003506 | 0.0004657 | 0.0007297 | 0.0006460 | 0.0006493 | 0.0002349 | 0.0009013 | 0.0005505 | 0.0000531 | 0.0003457 | 0.0005848 | 0.0020241 | 0.0004067 | 0.0002369 | 0.0006371 | 0.0007094 | 0.0002938 | 0.0004349 | 0.0000343 | 1.43e-05 | 0.0006749 | 0.0000722 | 0.0000531 | 0.0003302 | 3.28e-05 | 0.0002638 | 3.79e-05 | 0.0000627 | 0.0001665 | 0.0000748 | 0.0000681 | 0.0003170 | 0.0000571 | 0.0006355 | 0.0002251 | 0.0001450 | 0.0011443 | 0.0000989 | 0.0002083 | 0.0000449 | 0.0000187 | 0.0007744 | 0.0001092 | 3.23e-05 | 0.0000820 | 0.0003288 | 0.0007512 | 0.0002117 | 0.0002120 | 0.0002325 | 0.0003364 | 0.0006441 | 0.0001432 | 0.0000072 | 0.0001036 | 0.0003297 | 0.0000811 | 0.0000856 | 0.0001361 | 0.0001812 | 0.0000791 | 0.0001809 | 0.0000503 | 0.0001196 | 0.0001780 | 0.0003438 | 0.0000523 | 7.70e-06 | 0.0001307 | 7.70e-06 | 0.0000372 | 0.0000179 | 0.0001897 | 0.0000752 | 0.0001072 | 0.0002899 | 0.0002606 | 0.0000445 | 0.0000467 | 0.0000882 | 0.0001162 | 0.0002330 | 0.0001044 | 0.0003892 | 0.0000351 | 0.0001697 | 2.03e-05 | 0.0000800 | 3.56e-05 | 0.0007126 | 4.04e-05 | 0.0002300 | 0.0000734 | 0.0005197 | 0.0002574 | 0.0001340 | 1.49e-05 | 0.0004352 | 0.0000299 | 3.20e-05 | 0.0001323 | 1.16e-05 | 0.0000422 | 0.0002046 | 0.0003215 | 0.0000466 | 0.0000179 | 0.0000382 | 4.41e-05 | 0.0001366 | 0.0000425 | 8.39e-05 | 0.0000775 | 6.52e-05 | 0.0001580 | 0.0002227 | 3.90e-05 | 0.00e+00 | 0.0007569 | 0.0001253 | 0.0000633 | 0.0004241 | 0.0004669 | 0.0000695 | 0.0001131 | 0.0002028 | 0.0013172 | 0.0002710 | 0.0000275 | 0.0001547 | 0.0000317 | 0.0000836 | 0.00e+00 | 0.0000908 | 3.18e-05 | 3.31e-05 | 1.54e-05 | 2.52e-05 | 7.20e-06 | 0.0001283 | 0.0000955 | 1.22e-05 | 1.94e-05 | 0.0001148 | 0.0000778 | 4.20e-05 | 0.0000179 | 2.19e-05 | 0.0000934 | 4.30e-05 | 0.0001242 | 6.20e-06 | 1.36e-05 | 0.00e+00 | 1.39e-05 | 0.0000449 | 7.70e-06 | 1.16e-05 | 0.0001010 | 1.93e-05 | 0.0000975 | 0.0002512 | 0.0000859 | 0.0001499 | 0.0004714 | 3.61e-05 | 0.0000196 | 0.0000615 | 5.80e-05 | 0.0005948 | 0.0001501 | 1.20e-05 | 0.0001622 | 2.01e-05 | 0.0000545 | 0.0001176 | 7.12e-05 | 0.0003137 | 0.0002754 | 0.0000191 | 6.51e-05 | 1.94e-05 | 4.60e-05 | 0.0000565 | 6.00e-06 | 5.67e-05 | 0.0000258 | 0.0000848 | 0.0002081 | 2.14e-05 | 0.0001200 | 1.37e-05 | 2.15e-05 | 5.58e-05 | 0.0000246 | 0.00e+00 | 0.0001328 | 0.0000313 | 0.0000484 | 1.27e-05 | 0.0000593 | 2.53e-05 | 2.04e-05 | 2.08e-05 | 6.00e-06 | 0.0000537 | 0.00e+00 | 0.0000332 | 0.0000062 | 0.0000784 | 6.20e-06 | 9.17e-05 | 3.33e-05 | 0.0002855 | 1.91e-05 | 0.0001389 | 0.00e+00 | 0.0000116 | 0.0001003 | 0.0000780 | 2.79e-05 | 0.0000137 | 0.0000000 | 2.79e-05 | 3.27e-05 | 6.20e-06 | 1.25e-05 | 6.20e-06 | 0.0001737 | 0.0003305 | 0.0004025 | 0.0001039 | 0.0000499 | 0.0000555 | 0.0001492 | 0.0001802 | 0.0000968 | 1.97e-05 | 1.96e-05 | 0.0001387 | 3.33e-05 | 1.37e-05 | 2.56e-05 | 6.00e-06 | 0.0000795 | 0.0000662 | 0.0000880 | 0.00e+00 | 0.0000360 | 0.0000622 | 0.0000060 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000339 | 1.89e-05 | 0.00e+00 | 0.00e+00 | 0.0001133 | 7.70e-06 | 0.00e+00 | 3.36e-05 | 6.11e-05 | 0.0000136 | 0.00e+00 | 2.97e-05 | 0.00e+00 | 0.00e+00 | 0.0000752 | 0.0001381 | 0.0003215 | 0.00e+00 | 2.58e-05 | 0.0002323 | 0.0001943 | 0.0003866 | 0.0000199 | 7.70e-06 | 6.00e-06 | 1.25e-05 | 0.0001593 | 2.08e-05 | 4.49e-05 | 0.00e+00 | 1.20e-05 | 0.0000064 | 0.0000423 | 0.0000914 | 0.0001280 | 7.70e-06 | 6.00e-06 | 1.79e-05 | 7.70e-06 | 0.0001010 | 0.0001856 | 0.0002509 | 0.00e+00 | 0.0000136 | 0.00e+00 | 6.40e-06 | 4.64e-05 | 1.88e-05 | 2.68e-05 | 0.0e+00 | 0.0000318 | 1.84e-05 | 0.0001850 | 0.00e+00 | 0.0001332 | 0.00e+00 | 4.59e-05 | 2.46e-05 | 0.0000584 | 2.07e-05 | 0.00e+00 | 3.66e-05 | 7.20e-06 | 6.20e-06 | 0.0e+00 | 1.29e-05 | 2.38e-05 | 0.0001710 | 6.40e-06 | 0.0000072 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 3.86e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 6.00e-06 | 0.0e+00 | 0.0001188 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 6.20e-06 | 3.12e-05 | 1.76e-05 | 7.70e-06 | 0.00e+00 | 1.16e-05 | 0.00e+00 | 0.0000540 | 6.2e-06 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 2.70e-05 | 0.00e+00 | 0.0e+00 | 1.42e-05 | 0.0e+00 | 4.52e-05 | 0.00e+00 | 1.29e-05 | 6.20e-06 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 1.94e-05 | 0.0000512 | 0.0000480 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001084 | 9.84e-05 | 6.40e-06 | 0.00e+00 | 4.92e-05 | 0.00e+00 | 2.02e-05 | 0.0e+00 | 0.00e+00 | 0.0000533 | 0.0000811 | 6.40e-06 | 0.0001578 | 0.00e+00 | 0.0e+00 | 4.92e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 1.88e-05 | 0.0000619 | 0.0000504 | 0.0e+00 | 0.0001299 | 0.00e+00 | 0.0000790 | 0.00e+00 | 6.20e-06 | 0.0e+00 | 7.70e-06 | 0.00e+00 | 1.54e-05 | 0.00e+00 | 1.16e-05 | 1.16e-05 | 1.27e-05 | 1.84e-05 | 0.0e+00 | 7.70e-06 | 0.00e+00 | 0.00e+00 | 0.0003972 | 1.36e-05 | 0.0e+00 | 0.0e+00 | 0.0001171 | 0.0001215 | 0.0004113 | 0.0000568 | 0.0000198 | 0.0000543 | 1.36e-05 | 0.0000940 | 6.00e-06 | 2.78e-05 | 7.70e-06 | 1.25e-05 | 1.36e-05 | 0.0002708 | 0.0e+00 | 0.0e+00 | 0.0000503 | 3.18e-05 | 1.16e-05 | 0.00e+00 | 7.20e-06 | 0.00e+00 | 0.0e+00 | 7.60e-05 | 3.33e-05 | 1.39e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 5.81e-05 | 0.00e+00 | 0.00e+00 | 6.20e-06 | 5.78e-05 | 3.26e-05 | 0.00e+00 | 7.20e-06 | 4.58e-05 | 1.49e-05 | 0.00e+00 | 6.40e-06 | 7.20e-06 | 6.20e-06 | 0.0e+00 | 2.86e-05 | 7.70e-06 | 1.79e-05 | 0.00e+00 | 7.20e-06 | 1.79e-05 | 0.00e+00 | 1.24e-05 | 2.63e-05 | 6.20e-06 | 0.00e+00 | 0.0000739 | 3.67e-05 | 3.32e-05 | 1.36e-05 | 0.0e+00 | 2.26e-05 | 0.00e+00 | 2.06e-05 | 1.27e-05 | 0.00e+00 | 0.0e+00 | 6.20e-06 | 1.87e-05 | 7.20e-06 | 7.70e-06 | 1.42e-05 | 1.87e-05 | 0.00e+00 | 0.00e+00 | 1.29e-05 | 6.20e-06 | 1.94e-05 | 0.00e+00 | 0.00e+00 | 3.87e-05 | 0.0e+00 | 0.00e+00 | 1.87e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 1.16e-05 | 0.0e+00 | 6.20e-06 | 7.70e-06 | 1.16e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 1.27e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 6.00e-06 | 0.00e+00 | 4.53e-05 | 0.00e+00 | 6.00e-06 | 0.00e+00 | 1.16e-05 | 6.40e-06 | 0.00e+00 | 0.00e+00 | 6.00e-06 | 1.76e-05 | 0.00e+00 | 0.00e+00 | 6.40e-06 | 0.0e+00 | 6.40e-06 | 0.00e+00 | 6.20e-06 | 6.20e-06 | 6.20e-06 | 2.38e-05 | 1.39e-05 | 1.22e-05 | 6.2e-06 | 1.27e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.81e-05 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.54e-05 | 0.0e+00 | 0.0e+00 | 2.40e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 7.20e-06 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 1.37e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 7.7e-06 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 6.40e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 6.00e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 6.00e-06 | 0.00e+00 | 0.0e+00 | 6.40e-06 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 6.00e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 6.0e-06 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 1.16e-05 | 0.0e+00 | 0.00e+00 | 7.7e-06 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 7.2e-06 | 7.2e-06 | 1.16e-05 | 6.40e-06 | 6.4e-06 | 6.4e-06 | 6.4e-06 | 0.00e+00 | 7.70e-06 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 6.0e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 2 | 0.0443489 | 0.0029330 | 0.0243489 | 0.0040202 | 0.0653097 | 0.0060430 | 0.0018710 | 0.0201770 | 0.0310999 | 0.0305689 | 0.0001517 | 0.0287737 | 0.0136030 | 0.0141087 | 0.0113780 | 0.0001264 | 0.0010619 | 0.0068015 | 0.0001517 | 0.0585082 | 0.0067509 | 0.0050316 | 0.0011378 | 0.0005563 | 0.0057901 | 0.0035145 | 0.0023515 | 0.0041719 | 0.0006321 | 0.0078382 | 0.0115297 | 0.0023767 | 0.0019469 | 0.0000759 | 0.0089254 | 0.0066498 | 0.0035904 | 0.0089001 | 0.0024020 | 0.0073325 | 0.0006574 | 0.0015424 | 0.0021745 | 0.0018205 | 0.0039697 | 0.0036157 | 0.0015676 | 0.0002781 | 0.0158534 | 0.0020986 | 0.0056890 | 0.0016182 | 0.0089507 | 0.0028066 | 0.0015676 | 0.0083944 | 0.0327686 | 0.0009355 | 0.0072566 | 0.0021745 | 0.0032870 | 0.0229836 | 0.0019216 | 0.0008091 | 0.0016688 | 0.0001264 | 0.0004804 | 0.0003287 | 0.0022756 | 0.0003287 | 0.0014918 | 0.0017446 | 0.0005057 | 0.0197472 | 0.0006827 | 0.0015929 | 0.0020228 | 0.0016435 | 0.0017446 | 0.0010619 | 0.0043489 | 0.0019216 | 0.0040708 | 0.0004804 | 0.0004046 | 0.0183312 | 0.0003540 | 0.0011125 | 0.0098357 | 0.0065740 | 0.0000759 | 0.0016688 | 0.0003287 | 0.0011631 | 0.0013906 | 0.0032364 | 0.0005815 | 0.0002276 | 0.0011125 | 0.0000759 | 0.0036157 | 0.0066751 | 0.0122630 | 0.0000253 | 0.0003793 | 0.0056384 | 0.0109482 | 0.0099368 | 0.0000506 | 0.0002276 | 0.0003540 | 0.0008850 | 0.0023767 | 0.0001264 | 0.0116308 | 0.0008344 | 0.0005310 | 0.0003793 | 0.0000759 | 0.0001517 | 0.0005563 | 0.0015424 | 0.0006321 | 0.0006068 | 0.0016435 | 0.0058660 | 0.0010619 | 0.0005815 | 0.0023262 | 0.0019469 | 0.0033375 | 0.0004804 | 0.0026549 | 0.0071555 | 0.0000506 | 0.0000253 | 0.0000000 | 0.0010367 | 0.0004551 | 0.0011378 | 0.0020480 | 0.0012895 | 0.0059418 | 0.0000253 | 0.0039191 | 0.0000506 | 0.0036915 | 0.0000759 | 0.0018963 | 0.0000000 | 0.0009608 | 0.0007080 | 0.0016688 | 0.0052592 | 0.0000506 | 0.0010619 | 0.0051833 | 0.0015424 | 0.0001770 | 0.0002781 | 0.0006827 | 0.0004804 | 0.0013654 | 0.0013906 | 0.0014412 | 0.0006321 | 0.0003793 | 0.0005563 | 0.0010872 | 0.0009861 | 0.0006321 | 0.0007585 | 0.0002781 | 0.0005563 | 0.0007080 | 0.0006827 | 0.0013401 | 0.0054109 | 0.0020228 | 0.0004551 | 0.0009355 | 0.0010619 | 0.0001264 | 0.0001264 | 0.0000000 | 0.0004804 | 0.0002781 | 0.0007080 | 0.0018458 | 0.0004551 | 0.0003287 | 0.0010367 | 0.0000759 | 0.0011884 | 0.0008597 | 0.0000000 | 0.0012137 | 0.0001770 | 0.0006321 | 0.0003793 | 0.0013906 | 0.0002528 | 0.0002528 | 0.0002276 | 0.0005057 | 0.0015171 | 0.0023515 | 0.0001264 | 0.0003793 | 0.0008597 | 0.0002276 | 0.0000759 | 0.0002528 | 0.0070038 | 0.0001770 | 0.0000506 | 0.0002276 | 0.0009102 | 0.0002781 | 0.0000000 | 0.0010872 | 0.0001011 | 0.0020228 | 0.0005310 | 0.0012642 | 0.0002781 | 0.0000000 | 0.0006068 | 0.0000506 | 0.0002023 | 0.0000000 | 0.0001264 | 0.0001517 | 0.0000506 | 0.0002781 | 0.0019975 | 0.0009608 | 0.0005057 | 0.0002528 | 0.0011631 | 0.0002276 | 0.0002781 | 0.0001011 | 0.0012137 | 0.0002528 | 0.0003034 | 0.0002781 | 0.0005815 | 0.0001264 | 0.0033375 | 0.0000759 | 0.0004551 | 0.0005815 | 0.0006827 | 0.0002781 | 0.0000253 | 0.0001011 | 0.0003540 | 0.0000759 | 0.0000253 | 0.0004046 | 0.0001517 | 0.0007585 | 0.0006068 | 0.0012389 | 0.0013654 | 0.0001011 | 0.0009102 | 0.0000253 | 0.0017446 | 0.0004551 | 0.0002023 | 0.0004804 | 0.0001011 | 0.0011125 | 0.0037674 | 0.0016688 | 0.0001770 | 0.0001517 | 0.0002023 | 0.0005563 | 0.0017699 | 0.0009355 | 0.0000759 | 0.0001011 | 0.0004804 | 0.0000253 | 0.0002023 | 0.0008091 | 0.0007332 | 0.0014918 | 0.0001011 | 0.0002276 | 0.0000253 | 0.0003287 | 0.0003287 | 0.0003540 | 0.0002781 | 0.0000253 | 0.0007080 | 0.0014918 | 0.0005057 | 0.0015171 | 0.0002528 | 0.0004551 | 0.0001264 | 0.0000253 | 0.0002023 | 0.0011378 | 0.0000506 | 0.0000000 | 0.0001770 | 0.0004298 | 0.0004298 | 0.0008344 | 0.0004046 | 0.0000506 | 0.0000759 | 0.0001011 | 0.0017446 | 0.0005057 | 0.0006321 | 0.0008597 | 0.0006321 | 0.0005563 | 0.0016941 | 0.0010114 | 0.0002276 | 0.0002781 | 0.0012137 | 0.0007838 | 0.0000253 | 0.0001770 | 0.0009861 | 0.0037168 | 0.0006321 | 0.0001770 | 0.0012895 | 0.0011378 | 0.0003034 | 0.0002276 | 0.0000506 | 0.00e+00 | 0.0011125 | 0.0000506 | 0.0000253 | 0.0003034 | 2.53e-05 | 0.0002023 | 7.59e-05 | 0.0000000 | 0.0002276 | 0.0001011 | 0.0000759 | 0.0004298 | 0.0000759 | 0.0007585 | 0.0010872 | 0.0006068 | 0.0006321 | 0.0001264 | 0.0002276 | 0.0000759 | 0.0000000 | 0.0012389 | 0.0002276 | 5.06e-05 | 0.0000506 | 0.0006827 | 0.0019216 | 0.0004046 | 0.0002276 | 0.0001517 | 0.0002781 | 0.0008597 | 0.0001011 | 0.0000000 | 0.0001264 | 0.0001517 | 0.0000253 | 0.0001011 | 0.0001011 | 0.0002023 | 0.0001011 | 0.0001011 | 0.0000759 | 0.0001517 | 0.0003034 | 0.0003793 | 0.0001011 | 7.59e-05 | 0.0000506 | 7.59e-05 | 0.0000506 | 0.0000506 | 0.0001770 | 0.0001011 | 0.0002528 | 0.0003793 | 0.0002528 | 0.0000253 | 0.0001011 | 0.0001264 | 0.0002528 | 0.0003793 | 0.0000000 | 0.0006321 | 0.0000759 | 0.0001770 | 7.59e-05 | 0.0001264 | 2.53e-05 | 0.0033123 | 0.00e+00 | 0.0003540 | 0.0001517 | 0.0012642 | 0.0003034 | 0.0001264 | 0.00e+00 | 0.0001517 | 0.0000253 | 0.00e+00 | 0.0001264 | 0.00e+00 | 0.0001517 | 0.0003287 | 0.0001517 | 0.0000506 | 0.0001011 | 0.0000253 | 0.00e+00 | 0.0003287 | 0.0000506 | 2.53e-05 | 0.0000506 | 2.53e-05 | 0.0004298 | 0.0001011 | 0.00e+00 | 0.00e+00 | 0.0003287 | 0.0001011 | 0.0001011 | 0.0015676 | 0.0004804 | 0.0000000 | 0.0001264 | 0.0001770 | 0.0014918 | 0.0001770 | 0.0000253 | 0.0003034 | 0.0000506 | 0.0000253 | 2.53e-05 | 0.0000759 | 2.53e-05 | 2.53e-05 | 0.00e+00 | 7.59e-05 | 0.00e+00 | 0.0001264 | 0.0001517 | 0.00e+00 | 5.06e-05 | 0.0001517 | 0.0000506 | 0.00e+00 | 0.0001517 | 0.00e+00 | 0.0001770 | 0.00e+00 | 0.0000253 | 0.00e+00 | 2.53e-05 | 5.06e-05 | 2.53e-05 | 0.0000506 | 0.00e+00 | 0.00e+00 | 0.0000759 | 2.53e-05 | 0.0000253 | 0.0001517 | 0.0001770 | 0.0001011 | 0.0008344 | 5.06e-05 | 0.0000506 | 0.0001517 | 5.06e-05 | 0.0020480 | 0.0001517 | 0.00e+00 | 0.0005310 | 0.00e+00 | 0.0000759 | 0.0001770 | 2.53e-05 | 0.0003287 | 0.0000759 | 0.0000000 | 7.59e-05 | 0.00e+00 | 2.53e-05 | 0.0001011 | 2.53e-05 | 2.53e-05 | 0.0001011 | 0.0000253 | 0.0003287 | 0.00e+00 | 0.0002023 | 2.53e-05 | 2.53e-05 | 7.59e-05 | 0.0000506 | 0.00e+00 | 0.0001011 | 0.0000506 | 0.0001264 | 0.00e+00 | 0.0000759 | 5.06e-05 | 2.53e-05 | 0.00e+00 | 2.53e-05 | 0.0000506 | 0.00e+00 | 0.0001011 | 0.0000759 | 0.0002276 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.0004551 | 0.00e+00 | 0.0000506 | 0.00e+00 | 0.0000759 | 0.0005310 | 0.0000253 | 0.00e+00 | 0.0000000 | 0.0000000 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001517 | 0.0008344 | 0.0004298 | 0.0000253 | 0.0000000 | 0.0000506 | 0.0001517 | 0.0002528 | 0.0000253 | 2.53e-05 | 0.00e+00 | 0.0000000 | 2.53e-05 | 7.59e-05 | 7.59e-05 | 0.00e+00 | 0.0001011 | 0.0001517 | 0.0005057 | 0.00e+00 | 0.0000759 | 0.0000253 | 0.0001264 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.0001011 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.0003287 | 2.53e-05 | 0.00e+00 | 5.06e-05 | 2.53e-05 | 0.0002276 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.0001264 | 0.0000506 | 0.0004298 | 0.00e+00 | 0.00e+00 | 0.0002528 | 0.0001264 | 0.0003540 | 0.0002528 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0007332 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 2.53e-05 | 0.0000000 | 0.0000506 | 0.0001770 | 0.0002023 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000759 | 0.0001770 | 0.0000506 | 0.00e+00 | 0.0000000 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 5.06e-05 | 5.06e-05 | 0.0e+00 | 0.0001264 | 0.00e+00 | 0.0000759 | 0.00e+00 | 0.0001517 | 1.77e-04 | 5.06e-05 | 0.00e+00 | 0.0001517 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.53e-05 | 2.53e-05 | 0.0000506 | 0.00e+00 | 0.0000000 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0001770 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 5.06e-05 | 5.06e-05 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 7.59e-05 | 0.0000506 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 5.06e-05 | 0.0001011 | 0.0000506 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001770 | 5.06e-05 | 0.00e+00 | 0.00e+00 | 7.59e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0001264 | 0.0000759 | 2.53e-05 | 0.0004046 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 2.53e-05 | 0.0001264 | 0.0001770 | 0.0e+00 | 0.0004804 | 0.00e+00 | 0.0000759 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.0003540 | 2.53e-05 | 0.0e+00 | 0.0e+00 | 0.0001770 | 0.0000506 | 0.0003540 | 0.0001011 | 0.0002528 | 0.0000759 | 2.53e-05 | 0.0000253 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.0002276 | 0.0e+00 | 0.0e+00 | 0.0001264 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.0e+00 | 7.59e-05 | 0.00e+00 | 2.53e-05 | 0.0e+00 | 2.53e-05 | 2.53e-05 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 5.06e-05 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 7.59e-05 | 0.00e+00 | 0.00e+00 | 5.06e-05 | 0.00e+00 | 0.00e+00 | 0.0001264 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 7.59e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 7.59e-05 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 7.59e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 2.53e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.53e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 2.53e-05 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 2.53e-05 | 2.53e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 3 | 0.0360899 | 0.0064865 | 0.0312529 | 0.0047121 | 0.0156029 | 0.0068861 | 0.0031455 | 0.0347741 | 0.0323093 | 0.0443812 | 0.0003096 | 0.0357162 | 0.0217941 | 0.0101603 | 0.0112119 | 0.0002843 | 0.0009871 | 0.0102524 | 0.0001098 | 0.0325993 | 0.0087047 | 0.0045817 | 0.0005730 | 0.0008770 | 0.0139566 | 0.0036838 | 0.0044475 | 0.0039532 | 0.0009964 | 0.0046393 | 0.0149180 | 0.0021216 | 0.0027147 | 0.0002256 | 0.0064724 | 0.0088173 | 0.0040302 | 0.0080483 | 0.0014336 | 0.0104816 | 0.0003489 | 0.0029217 | 0.0021268 | 0.0019899 | 0.0034703 | 0.0037880 | 0.0024369 | 0.0004109 | 0.0153225 | 0.0011560 | 0.0051801 | 0.0016942 | 0.0055699 | 0.0014415 | 0.0012313 | 0.0050347 | 0.0108299 | 0.0024075 | 0.0059860 | 0.0021537 | 0.0030329 | 0.0183367 | 0.0027436 | 0.0006962 | 0.0019277 | 0.0002624 | 0.0003635 | 0.0004609 | 0.0027518 | 0.0007170 | 0.0030834 | 0.0020951 | 0.0005835 | 0.0254161 | 0.0008825 | 0.0013058 | 0.0009456 | 0.0018616 | 0.0021824 | 0.0019963 | 0.0035726 | 0.0033660 | 0.0037506 | 0.0004549 | 0.0004130 | 0.0119243 | 0.0009236 | 0.0015520 | 0.0078608 | 0.0062882 | 0.0001675 | 0.0023060 | 0.0003315 | 0.0015469 | 0.0018344 | 0.0042996 | 0.0004072 | 0.0002685 | 0.0012730 | 0.0001179 | 0.0046173 | 0.0035460 | 0.0121942 | 0.0000834 | 0.0003617 | 0.0098891 | 0.0148581 | 0.0093878 | 0.0000648 | 0.0004673 | 0.0001596 | 0.0013189 | 0.0020580 | 0.0002467 | 0.0169324 | 0.0012099 | 0.0005529 | 0.0004484 | 0.0001920 | 0.0000928 | 0.0006939 | 0.0008789 | 0.0008913 | 0.0006530 | 0.0012642 | 0.0064907 | 0.0014699 | 0.0007178 | 0.0018248 | 0.0039678 | 0.0025972 | 0.0010502 | 0.0017920 | 0.0053780 | 0.0001939 | 0.0001990 | 0.0000188 | 0.0012096 | 0.0008588 | 0.0014100 | 0.0034088 | 0.0016424 | 0.0048639 | 0.0000212 | 0.0045729 | 0.0000689 | 0.0071505 | 0.0002053 | 0.0010977 | 0.0000076 | 0.0011877 | 0.0006438 | 0.0013168 | 0.0077908 | 0.0001650 | 0.0015034 | 0.0088468 | 0.0012940 | 0.0002783 | 0.0005507 | 0.0006178 | 0.0009376 | 0.0008338 | 0.0029807 | 0.0015663 | 0.0004393 | 0.0004249 | 0.0003830 | 0.0009745 | 0.0011776 | 0.0009638 | 0.0003854 | 0.0004890 | 0.0008604 | 0.0006166 | 0.0005761 | 0.0014066 | 0.0048440 | 0.0018462 | 0.0005072 | 0.0010498 | 0.0012044 | 0.0001493 | 0.0001735 | 0.0000242 | 0.0004997 | 0.0004200 | 0.0007149 | 0.0018938 | 0.0008022 | 0.0005245 | 0.0011741 | 0.0002036 | 0.0012144 | 0.0006489 | 0.0000791 | 0.0012850 | 0.0002208 | 0.0009394 | 0.0003207 | 0.0019519 | 0.0002957 | 0.0002101 | 0.0002254 | 0.0005596 | 0.0014616 | 0.0022697 | 0.0000611 | 0.0002461 | 0.0010080 | 0.0003039 | 0.0001010 | 0.0003286 | 0.0086837 | 0.0007242 | 0.0001476 | 0.0003344 | 0.0007205 | 0.0002027 | 0.0000783 | 0.0014899 | 0.0001360 | 0.0021523 | 0.0004819 | 0.0012845 | 0.0001402 | 0.0001340 | 0.0015616 | 0.0001085 | 0.0002091 | 0.0000416 | 0.0000723 | 0.0006095 | 0.0000886 | 0.0004577 | 0.0022931 | 0.0009626 | 0.0004730 | 0.0005396 | 0.0015210 | 0.0001669 | 0.0001300 | 0.0001385 | 0.0018747 | 0.0002867 | 0.0004388 | 0.0005688 | 0.0006179 | 0.0002388 | 0.0050404 | 0.0000815 | 0.0004186 | 0.0009362 | 0.0008372 | 0.0002587 | 0.0001834 | 0.0001660 | 0.0002452 | 0.0001580 | 0.0000873 | 0.0003935 | 0.0002184 | 0.0007924 | 0.0014855 | 0.0017901 | 0.0012341 | 0.0001815 | 0.0014978 | 0.0001955 | 0.0017311 | 0.0004592 | 0.0001710 | 0.0003754 | 0.0000954 | 0.0010069 | 0.0031362 | 0.0015957 | 0.0001892 | 0.0002630 | 0.0002366 | 0.0006589 | 0.0017063 | 0.0006943 | 0.0002105 | 0.0000144 | 0.0002657 | 0.0000739 | 0.0003256 | 0.0009428 | 0.0007148 | 0.0027178 | 0.0002495 | 0.0001040 | 0.0001339 | 0.0004404 | 0.0003132 | 0.0002369 | 0.0003392 | 0.0000518 | 0.0019025 | 0.0010999 | 0.0002895 | 0.0023157 | 0.0003338 | 0.0007281 | 0.0003886 | 0.0000940 | 0.0001689 | 0.0018018 | 0.0001042 | 0.0000160 | 0.0002824 | 0.0003244 | 0.0002190 | 0.0017028 | 0.0004197 | 0.0001367 | 0.0000460 | 0.0002202 | 0.0026147 | 0.0003132 | 0.0005771 | 0.0008742 | 0.0005919 | 0.0005615 | 0.0010447 | 0.0009894 | 0.0003684 | 0.0002477 | 0.0012923 | 0.0004796 | 0.0000289 | 0.0002532 | 0.0009897 | 0.0031235 | 0.0006772 | 0.0002562 | 0.0008683 | 0.0013480 | 0.0004173 | 0.0003559 | 0.0000753 | 0.00e+00 | 0.0011799 | 0.0000700 | 0.0000645 | 0.0003294 | 3.09e-05 | 0.0002702 | 1.06e-05 | 0.0000357 | 0.0001649 | 0.0000666 | 0.0000939 | 0.0003197 | 0.0001196 | 0.0016576 | 0.0006665 | 0.0002533 | 0.0008478 | 0.0002312 | 0.0001040 | 0.0000243 | 0.0000115 | 0.0016680 | 0.0001439 | 1.42e-05 | 0.0000486 | 0.0007057 | 0.0018946 | 0.0003571 | 0.0006751 | 0.0002127 | 0.0006530 | 0.0010676 | 0.0000786 | 0.0000000 | 0.0000820 | 0.0005216 | 0.0000375 | 0.0000987 | 0.0001101 | 0.0001539 | 0.0001050 | 0.0001500 | 0.0000763 | 0.0001249 | 0.0001510 | 0.0002662 | 0.0000527 | 2.27e-05 | 0.0001825 | 2.07e-05 | 0.0000366 | 0.0000036 | 0.0001797 | 0.0000990 | 0.0003359 | 0.0003524 | 0.0002581 | 0.0000194 | 0.0000608 | 0.0000870 | 0.0002189 | 0.0002403 | 0.0000248 | 0.0007648 | 0.0000114 | 0.0002816 | 4.46e-05 | 0.0000283 | 4.27e-05 | 0.0020834 | 5.22e-05 | 0.0003221 | 0.0001001 | 0.0009063 | 0.0004720 | 0.0002018 | 6.10e-06 | 0.0002314 | 0.0000476 | 7.40e-06 | 0.0001140 | 3.80e-06 | 0.0000680 | 0.0002595 | 0.0002414 | 0.0000787 | 0.0000073 | 0.0000753 | 3.31e-05 | 0.0002149 | 0.0000596 | 6.74e-05 | 0.0000168 | 2.36e-05 | 0.0004354 | 0.0000968 | 3.82e-05 | 1.20e-05 | 0.0011273 | 0.0000534 | 0.0000712 | 0.0010606 | 0.0009406 | 0.0001355 | 0.0001132 | 0.0001820 | 0.0014200 | 0.0000462 | 0.0000460 | 0.0002291 | 0.0000561 | 0.0000991 | 1.12e-05 | 0.0001066 | 3.35e-05 | 4.56e-05 | 3.80e-06 | 3.60e-06 | 0.00e+00 | 0.0001030 | 0.0000895 | 1.98e-05 | 9.21e-05 | 0.0000487 | 0.0000826 | 3.25e-05 | 0.0000373 | 0.00e+00 | 0.0001241 | 1.18e-05 | 0.0000599 | 8.70e-06 | 2.29e-05 | 1.60e-05 | 2.75e-05 | 0.0000581 | 7.40e-06 | 1.22e-05 | 0.0001281 | 1.47e-05 | 0.0000711 | 0.0005859 | 0.0002364 | 0.0001280 | 0.0008387 | 2.36e-05 | 0.0000934 | 0.0000983 | 1.09e-04 | 0.0012978 | 0.0001145 | 6.12e-05 | 0.0004693 | 3.60e-05 | 0.0000275 | 0.0000688 | 3.22e-05 | 0.0003408 | 0.0001753 | 0.0000304 | 2.57e-05 | 7.70e-06 | 5.73e-05 | 0.0000355 | 3.64e-05 | 2.21e-05 | 0.0000590 | 0.0000266 | 0.0001538 | 3.26e-05 | 0.0000833 | 1.14e-05 | 4.70e-06 | 4.15e-05 | 0.0001090 | 1.38e-05 | 0.0000602 | 0.0000657 | 0.0000909 | 8.40e-06 | 0.0000287 | 3.38e-05 | 1.44e-05 | 2.43e-05 | 2.96e-05 | 0.0000408 | 3.80e-06 | 0.0000966 | 0.0001445 | 0.0002611 | 3.48e-05 | 8.49e-05 | 2.74e-05 | 0.0003842 | 1.79e-05 | 0.0000082 | 7.70e-06 | 0.0001754 | 0.0003091 | 0.0000778 | 3.69e-05 | 0.0000188 | 0.0000061 | 1.57e-05 | 2.63e-05 | 2.34e-05 | 1.12e-05 | 1.71e-05 | 0.0001098 | 0.0006134 | 0.0005399 | 0.0000432 | 0.0000375 | 0.0000944 | 0.0000917 | 0.0003281 | 0.0000916 | 2.55e-05 | 1.04e-05 | 0.0001370 | 9.72e-05 | 2.46e-05 | 6.10e-05 | 3.80e-06 | 0.0000494 | 0.0000484 | 0.0001880 | 5.10e-06 | 0.0000304 | 0.0000873 | 0.0000289 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000782 | 2.09e-05 | 0.00e+00 | 0.00e+00 | 0.0005050 | 1.68e-05 | 0.00e+00 | 2.56e-05 | 2.44e-05 | 0.0000514 | 7.10e-06 | 5.03e-05 | 0.00e+00 | 3.60e-06 | 0.0001295 | 0.0001002 | 0.0005220 | 3.94e-05 | 1.89e-05 | 0.0002638 | 0.0003311 | 0.0006100 | 0.0000781 | 6.80e-06 | 0.00e+00 | 7.60e-06 | 0.0006331 | 2.48e-05 | 3.40e-05 | 0.00e+00 | 9.90e-06 | 0.0000125 | 0.0000981 | 0.0001251 | 0.0002031 | 3.60e-06 | 8.90e-06 | 1.04e-05 | 0.00e+00 | 0.0000591 | 0.0001716 | 0.0001165 | 8.70e-06 | 0.0000031 | 0.00e+00 | 6.10e-06 | 2.45e-05 | 1.95e-05 | 5.02e-05 | 0.0e+00 | 0.0000860 | 2.11e-05 | 0.0000963 | 0.00e+00 | 0.0001906 | 3.10e-06 | 9.05e-05 | 1.35e-05 | 0.0000745 | 5.45e-05 | 4.70e-06 | 1.55e-05 | 4.70e-06 | 3.60e-06 | 0.0e+00 | 4.08e-05 | 3.80e-05 | 0.0001808 | 9.20e-06 | 0.0000047 | 7.50e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 6.62e-05 | 3.80e-06 | 8.90e-06 | 0.0e+00 | 0.0e+00 | 1.06e-05 | 0.0e+00 | 0.0000598 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.70e-05 | 1.53e-05 | 9.54e-05 | 1.74e-05 | 7.10e-06 | 1.04e-05 | 8.60e-05 | 0.0000390 | 0.0e+00 | 3.10e-06 | 0.0e+00 | 1.30e-05 | 4.96e-05 | 6.10e-06 | 0.0e+00 | 1.06e-05 | 0.0e+00 | 6.98e-05 | 6.10e-06 | 1.25e-05 | 3.60e-06 | 3.80e-06 | 0.0e+00 | 0.0e+00 | 3.10e-06 | 0.0000541 | 0.0000409 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000816 | 6.90e-05 | 6.80e-06 | 7.70e-06 | 2.61e-05 | 3.60e-06 | 2.90e-05 | 0.0e+00 | 1.89e-05 | 0.0000828 | 0.0001814 | 3.99e-05 | 0.0002308 | 1.22e-05 | 0.0e+00 | 1.30e-05 | 1.06e-05 | 7.30e-06 | 7.10e-06 | 0.0e+00 | 0.0e+00 | 2.43e-05 | 0.0000713 | 0.0002529 | 3.6e-06 | 0.0003365 | 8.70e-06 | 0.0001790 | 0.00e+00 | 1.12e-05 | 3.8e-06 | 1.18e-05 | 0.00e+00 | 9.70e-06 | 0.00e+00 | 9.20e-06 | 0.00e+00 | 2.57e-05 | 5.21e-05 | 3.8e-06 | 3.60e-06 | 0.00e+00 | 8.90e-06 | 0.0004279 | 5.10e-06 | 0.0e+00 | 3.8e-06 | 0.0002283 | 0.0001362 | 0.0004405 | 0.0000868 | 0.0001316 | 0.0001584 | 3.59e-05 | 0.0001586 | 2.80e-05 | 1.06e-05 | 1.06e-05 | 2.54e-05 | 1.42e-05 | 0.0001680 | 6.8e-06 | 6.8e-06 | 0.0000494 | 5.59e-05 | 2.66e-05 | 1.75e-05 | 1.40e-05 | 9.90e-06 | 6.8e-06 | 9.07e-05 | 1.06e-05 | 2.86e-05 | 6.8e-06 | 6.80e-06 | 2.29e-05 | 1.06e-05 | 2.71e-05 | 1.06e-05 | 3.39e-05 | 2.22e-05 | 3.68e-05 | 2.95e-05 | 0.00e+00 | 1.23e-05 | 4.38e-05 | 2.47e-05 | 0.00e+00 | 4.70e-06 | 0.00e+00 | 6.10e-06 | 0.0e+00 | 1.53e-05 | 1.06e-05 | 0.00e+00 | 1.04e-05 | 8.40e-06 | 1.71e-05 | 3.80e-06 | 7.60e-06 | 1.51e-05 | 4.18e-05 | 3.80e-06 | 0.0000193 | 1.09e-05 | 1.71e-05 | 3.80e-06 | 0.0e+00 | 0.00e+00 | 3.10e-06 | 2.69e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 2.02e-05 | 2.17e-05 | 7.40e-06 | 1.07e-05 | 2.04e-05 | 3.80e-06 | 3.80e-06 | 0.00e+00 | 8.40e-06 | 9.70e-06 | 0.00e+00 | 0.00e+00 | 6.10e-06 | 0.0e+00 | 0.00e+00 | 9.70e-06 | 8.40e-06 | 0.00e+00 | 7.6e-06 | 5.1e-06 | 3.10e-06 | 1.04e-05 | 0.0e+00 | 6.60e-06 | 3.60e-06 | 3.10e-06 | 0.00e+00 | 0.00e+00 | 5.10e-06 | 0.0e+00 | 6.1e-06 | 0.00e+00 | 4.70e-06 | 1.61e-05 | 0.00e+00 | 3.80e-06 | 2.52e-05 | 7.50e-06 | 3.76e-05 | 3.80e-06 | 1.58e-05 | 1.47e-05 | 7.50e-06 | 1.22e-05 | 3.80e-06 | 3.80e-06 | 3.80e-06 | 1.11e-05 | 1.73e-05 | 1.20e-05 | 1.27e-05 | 6.8e-06 | 3.34e-05 | 3.80e-06 | 1.62e-05 | 0.00e+00 | 5.10e-06 | 3.60e-06 | 3.80e-06 | 3.10e-06 | 0.0e+00 | 6.10e-06 | 0.00e+00 | 4.7e-06 | 3.60e-06 | 3.80e-06 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 5.10e-06 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 3.8e-06 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 3.60e-06 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 4.70e-06 | 0.00e+00 | 7.60e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 4.70e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 8.20e-06 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 4.7e-06 | 0.0e+00 | 6.10e-06 | 0.0e+00 | 3.80e-06 | 0.00e+00 | 0.0e+00 | 1.59e-05 | 3.10e-06 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 6.90e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 6.10e-06 | 0.00e+00 | 4.70e-06 | 6.60e-06 | 3.6e-06 | 3.60e-06 | 3.60e-06 | 7.4e-06 | 3.10e-06 | 0.00e+00 | 0.00e+00 | 3.10e-06 | 3.80e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 1.07e-05 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 8.40e-06 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 9.2e-06 | 6.1e-06 | 1.14e-05 | 3.8e-06 | 3.80e-06 | 3.8e-06 | 3.8e-06 | 4.7e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 5.1e-06 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 3.1e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 5.1e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 4 | 0.0591134 | 0.0171849 | 0.0460918 | 0.0146773 | 0.0352493 | 0.0199275 | 0.0113311 | 0.0269879 | 0.0409644 | 0.0259584 | 0.0005842 | 0.0324789 | 0.0142955 | 0.0176195 | 0.0268779 | 0.0031351 | 0.0068207 | 0.0123805 | 0.0001875 | 0.0207875 | 0.0093515 | 0.0049190 | 0.0025045 | 0.0010918 | 0.0130373 | 0.0072721 | 0.0078871 | 0.0047414 | 0.0033378 | 0.0096760 | 0.0118904 | 0.0027178 | 0.0045881 | 0.0008777 | 0.0083045 | 0.0120565 | 0.0086520 | 0.0054568 | 0.0026242 | 0.0072522 | 0.0014923 | 0.0026557 | 0.0028784 | 0.0046239 | 0.0024750 | 0.0058384 | 0.0023557 | 0.0015154 | 0.0044382 | 0.0022352 | 0.0093425 | 0.0020995 | 0.0063070 | 0.0020810 | 0.0026868 | 0.0063807 | 0.0065730 | 0.0026660 | 0.0056730 | 0.0038575 | 0.0034144 | 0.0052292 | 0.0061652 | 0.0011297 | 0.0020219 | 0.0004482 | 0.0007501 | 0.0009263 | 0.0044917 | 0.0012645 | 0.0020647 | 0.0018515 | 0.0008096 | 0.0055524 | 0.0014317 | 0.0021989 | 0.0078109 | 0.0031479 | 0.0028388 | 0.0026557 | 0.0057954 | 0.0034937 | 0.0046450 | 0.0005073 | 0.0010316 | 0.0088459 | 0.0007311 | 0.0011691 | 0.0056943 | 0.0052034 | 0.0009745 | 0.0017548 | 0.0008012 | 0.0025626 | 0.0018128 | 0.0022599 | 0.0010634 | 0.0002572 | 0.0013748 | 0.0008622 | 0.0040085 | 0.0045046 | 0.0112003 | 0.0006259 | 0.0008194 | 0.0030918 | 0.0037040 | 0.0085025 | 0.0002428 | 0.0014029 | 0.0002872 | 0.0016859 | 0.0021909 | 0.0003826 | 0.0041508 | 0.0008138 | 0.0010824 | 0.0009130 | 0.0005001 | 0.0002133 | 0.0014237 | 0.0013142 | 0.0007277 | 0.0005558 | 0.0014051 | 0.0017756 | 0.0014044 | 0.0007353 | 0.0020984 | 0.0024667 | 0.0027837 | 0.0005887 | 0.0016957 | 0.0026277 | 0.0004050 | 0.0006433 | 0.0000989 | 0.0012184 | 0.0005698 | 0.0019393 | 0.0013396 | 0.0012703 | 0.0044678 | 0.0000258 | 0.0018339 | 0.0001360 | 0.0024832 | 0.0003792 | 0.0022852 | 0.0000697 | 0.0015613 | 0.0008266 | 0.0008781 | 0.0026296 | 0.0001288 | 0.0008036 | 0.0027378 | 0.0010035 | 0.0008615 | 0.0003641 | 0.0006323 | 0.0008945 | 0.0009043 | 0.0013532 | 0.0008747 | 0.0007357 | 0.0013434 | 0.0003713 | 0.0008066 | 0.0010047 | 0.0024696 | 0.0017006 | 0.0002982 | 0.0008104 | 0.0007035 | 0.0004050 | 0.0011146 | 0.0031790 | 0.0021126 | 0.0001913 | 0.0009263 | 0.0014972 | 0.0002728 | 0.0002137 | 0.0003467 | 0.0006119 | 0.0003569 | 0.0021924 | 0.0013942 | 0.0008312 | 0.0006713 | 0.0012332 | 0.0001799 | 0.0012812 | 0.0005777 | 0.0001140 | 0.0008164 | 0.0001622 | 0.0003788 | 0.0006293 | 0.0010612 | 0.0002023 | 0.0002682 | 0.0002724 | 0.0002277 | 0.0007130 | 0.0013441 | 0.0001584 | 0.0005664 | 0.0008172 | 0.0001799 | 0.0000769 | 0.0004342 | 0.0042282 | 0.0002391 | 0.0000405 | 0.0005198 | 0.0005664 | 0.0004088 | 0.0001250 | 0.0012949 | 0.0002394 | 0.0007339 | 0.0008354 | 0.0013472 | 0.0002610 | 0.0001140 | 0.0005444 | 0.0002716 | 0.0006652 | 0.0001693 | 0.0002027 | 0.0003573 | 0.0001550 | 0.0001102 | 0.0012524 | 0.0008224 | 0.0003163 | 0.0003497 | 0.0006482 | 0.0001762 | 0.0005634 | 0.0004130 | 0.0005186 | 0.0002095 | 0.0002209 | 0.0001322 | 0.0003747 | 0.0002394 | 0.0040492 | 0.0002057 | 0.0007028 | 0.0008327 | 0.0008907 | 0.0002209 | 0.0001656 | 0.0004016 | 0.0013010 | 0.0001879 | 0.0002031 | 0.0001731 | 0.0002534 | 0.0009929 | 0.0007403 | 0.0012881 | 0.0010009 | 0.0003133 | 0.0008244 | 0.0001398 | 0.0007800 | 0.0006478 | 0.0001584 | 0.0000917 | 0.0000883 | 0.0006766 | 0.0016957 | 0.0009967 | 0.0001765 | 0.0002099 | 0.0002095 | 0.0003648 | 0.0007274 | 0.0004489 | 0.0001951 | 0.0000220 | 0.0001909 | 0.0000663 | 0.0003387 | 0.0004156 | 0.0009270 | 0.0010555 | 0.0001288 | 0.0002023 | 0.0001102 | 0.0004561 | 0.0003012 | 0.0004785 | 0.0001693 | 0.0000515 | 0.0003970 | 0.0009804 | 0.0005152 | 0.0006539 | 0.0005679 | 0.0009895 | 0.0001436 | 0.0000553 | 0.0003910 | 0.0011059 | 0.0001326 | 0.0000663 | 0.0002940 | 0.0003822 | 0.0003277 | 0.0004561 | 0.0003425 | 0.0001322 | 0.0000735 | 0.0002281 | 0.0005338 | 0.0003019 | 0.0001618 | 0.0005951 | 0.0002099 | 0.0003864 | 0.0013021 | 0.0006293 | 0.0002652 | 0.0002648 | 0.0011047 | 0.0006357 | 0.0000110 | 0.0001981 | 0.0003379 | 0.0013112 | 0.0002940 | 0.0001322 | 0.0007906 | 0.0004262 | 0.0002868 | 0.0003754 | 0.0000477 | 1.10e-05 | 0.0010824 | 0.0000515 | 0.0001284 | 0.0002103 | 9.93e-05 | 0.0002095 | 2.58e-05 | 0.0000515 | 0.0001584 | 0.0000811 | 0.0000769 | 0.0002534 | 0.0000883 | 0.0002678 | 0.0003084 | 0.0002095 | 0.0008956 | 0.0000701 | 0.0002353 | 0.0001250 | 0.0001216 | 0.0012283 | 0.0003391 | 1.48e-05 | 0.0000663 | 0.0004455 | 0.0005520 | 0.0002171 | 0.0002686 | 0.0002466 | 0.0003641 | 0.0004084 | 0.0001099 | 0.0000443 | 0.0000883 | 0.0001512 | 0.0000883 | 0.0001212 | 0.0000849 | 0.0001656 | 0.0001693 | 0.0002682 | 0.0000515 | 0.0001470 | 0.0001693 | 0.0003788 | 0.0000439 | 1.48e-05 | 0.0001140 | 5.53e-05 | 0.0000258 | 0.0000549 | 0.0001360 | 0.0000735 | 0.0000663 | 0.0001508 | 0.0003497 | 0.0000148 | 0.0001178 | 0.0000553 | 0.0001216 | 0.0003539 | 0.0000663 | 0.0003978 | 0.0001985 | 0.0003785 | 8.45e-05 | 0.0000549 | 5.87e-05 | 0.0009733 | 4.05e-05 | 0.0001727 | 0.0000553 | 0.0006596 | 0.0003243 | 0.0002281 | 0.00e+00 | 0.0002758 | 0.0000773 | 3.67e-05 | 0.0001546 | 0.00e+00 | 0.0000845 | 0.0004330 | 0.0001292 | 0.0000296 | 0.0000258 | 0.0000625 | 2.58e-05 | 0.0000773 | 0.0000515 | 1.48e-05 | 0.0000296 | 3.30e-05 | 0.0002099 | 0.0000807 | 8.45e-05 | 3.67e-05 | 0.0004561 | 0.0001136 | 0.0000993 | 0.0011346 | 0.0003785 | 0.0000735 | 0.0001360 | 0.0001731 | 0.0007808 | 0.0000773 | 0.0000701 | 0.0000735 | 0.0000477 | 0.0000811 | 5.53e-05 | 0.0000000 | 4.77e-05 | 1.10e-05 | 4.05e-05 | 4.77e-05 | 1.48e-05 | 0.0001178 | 0.0000625 | 1.10e-05 | 4.77e-05 | 0.0001034 | 0.0000849 | 5.15e-05 | 0.0000110 | 0.00e+00 | 0.0000993 | 2.20e-05 | 0.0000701 | 0.00e+00 | 2.20e-05 | 4.05e-05 | 0.00e+00 | 0.0001292 | 2.96e-05 | 1.10e-05 | 0.0001212 | 3.67e-05 | 0.0001250 | 0.0002023 | 0.0000773 | 0.0000625 | 0.0005111 | 0.00e+00 | 0.0000587 | 0.0000625 | 4.43e-05 | 0.0006391 | 0.0000477 | 2.20e-05 | 0.0001913 | 2.20e-05 | 0.0000625 | 0.0001398 | 7.73e-05 | 0.0002978 | 0.0001178 | 0.0000258 | 5.87e-05 | 0.00e+00 | 3.67e-05 | 0.0000258 | 2.58e-05 | 5.91e-05 | 0.0000405 | 0.0000258 | 0.0002243 | 1.10e-05 | 0.0002137 | 5.87e-05 | 1.48e-05 | 9.21e-05 | 0.0000993 | 3.67e-05 | 0.0001398 | 0.0000000 | 0.0001068 | 3.67e-05 | 0.0000220 | 2.20e-05 | 6.63e-05 | 1.48e-05 | 2.58e-05 | 0.0000553 | 1.48e-05 | 0.0000553 | 0.0000697 | 0.0000405 | 1.48e-05 | 1.10e-05 | 0.00e+00 | 0.0003421 | 0.00e+00 | 0.0000405 | 0.00e+00 | 0.0000258 | 0.0002614 | 0.0002830 | 0.00e+00 | 0.0001068 | 0.0001652 | 3.67e-05 | 2.58e-05 | 0.00e+00 | 4.43e-05 | 2.58e-05 | 0.0000993 | 0.0003167 | 0.0003459 | 0.0002326 | 0.0000477 | 0.0000701 | 0.0001622 | 0.0001803 | 0.0000367 | 4.05e-05 | 3.67e-05 | 0.0001178 | 3.67e-05 | 2.96e-05 | 4.39e-05 | 4.39e-05 | 0.0001436 | 0.0001212 | 0.0002606 | 0.00e+00 | 0.0001394 | 0.0000553 | 0.0000515 | 1.48e-05 | 0.00e+00 | 0.00e+00 | 1.10e-05 | 0.0000477 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000477 | 2.96e-05 | 0.00e+00 | 6.63e-05 | 4.77e-05 | 0.0002470 | 2.58e-05 | 2.20e-05 | 0.00e+00 | 0.00e+00 | 0.0001140 | 0.0000845 | 0.0002902 | 1.10e-05 | 4.05e-05 | 0.0001656 | 0.0000330 | 0.0002243 | 0.0001216 | 1.10e-05 | 2.20e-05 | 1.48e-05 | 0.0004971 | 0.00e+00 | 8.45e-05 | 0.00e+00 | 1.10e-05 | 0.0000000 | 0.0000697 | 0.0000625 | 0.0001326 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000625 | 0.0001584 | 0.0001250 | 1.48e-05 | 0.0001292 | 0.00e+00 | 0.00e+00 | 2.58e-05 | 3.30e-05 | 4.05e-05 | 0.0e+00 | 0.0000258 | 5.91e-05 | 0.0001436 | 1.48e-05 | 0.0001360 | 4.05e-05 | 4.77e-05 | 2.96e-05 | 0.0001174 | 4.05e-05 | 2.58e-05 | 4.39e-05 | 1.48e-05 | 0.00e+00 | 0.0e+00 | 4.05e-05 | 2.58e-05 | 0.0001512 | 0.00e+00 | 0.0001064 | 2.20e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 9.96e-05 | 2.20e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0001144 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 4.77e-05 | 1.10e-05 | 4.05e-05 | 0.00e+00 | 0.00e+00 | 2.20e-05 | 1.10e-05 | 0.0000405 | 1.1e-05 | 0.00e+00 | 0.0e+00 | 2.58e-05 | 2.20e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 4.39e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0001030 | 0.0001584 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001064 | 9.21e-05 | 0.00e+00 | 2.58e-05 | 4.77e-05 | 0.00e+00 | 1.48e-05 | 0.0e+00 | 0.00e+00 | 0.0001068 | 0.0000845 | 1.48e-05 | 0.0000845 | 0.00e+00 | 0.0e+00 | 1.10e-05 | 1.48e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0000553 | 0.0002243 | 0.0e+00 | 0.0003519 | 0.00e+00 | 0.0001254 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.48e-05 | 1.48e-05 | 1.48e-05 | 3.67e-05 | 1.48e-05 | 0.00e+00 | 5.15e-05 | 0.0e+00 | 1.10e-05 | 2.58e-05 | 1.48e-05 | 0.0002834 | 1.10e-05 | 0.0e+00 | 0.0e+00 | 0.0001322 | 0.0001765 | 0.0005368 | 0.0000959 | 0.0001064 | 0.0000959 | 1.10e-05 | 0.0000625 | 0.00e+00 | 1.48e-05 | 2.58e-05 | 5.53e-05 | 0.00e+00 | 0.0001765 | 0.0e+00 | 0.0e+00 | 0.0000000 | 7.35e-05 | 2.58e-05 | 1.10e-05 | 2.58e-05 | 2.96e-05 | 0.0e+00 | 6.25e-05 | 0.00e+00 | 4.43e-05 | 0.0e+00 | 0.00e+00 | 2.20e-05 | 0.00e+00 | 2.58e-05 | 0.00e+00 | 0.00e+00 | 2.58e-05 | 2.20e-05 | 4.05e-05 | 0.00e+00 | 1.48e-05 | 4.39e-05 | 1.10e-05 | 0.00e+00 | 1.48e-05 | 1.10e-05 | 0.00e+00 | 0.0e+00 | 1.10e-05 | 1.10e-05 | 0.00e+00 | 0.00e+00 | 2.20e-05 | 7.73e-05 | 0.00e+00 | 1.48e-05 | 2.58e-05 | 2.96e-05 | 2.58e-05 | 0.0000296 | 1.10e-05 | 3.67e-05 | 0.00e+00 | 0.0e+00 | 2.20e-05 | 1.48e-05 | 1.48e-05 | 1.48e-05 | 1.48e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.48e-05 | 0.00e+00 | 1.48e-05 | 0.00e+00 | 0.00e+00 | 2.20e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 1.48e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 2.20e-05 | 1.48e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.10e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.48e-05 | 1.48e-05 | 5.53e-05 | 0.00e+00 | 0.00e+00 | 1.10e-05 | 0.00e+00 | 0.00e+00 | 1.10e-05 | 1.48e-05 | 2.20e-05 | 6.97e-05 | 1.48e-05 | 2.58e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 2.58e-05 | 1.48e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.48e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.10e-05 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 1.48e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.10e-05 | 0.0e+00 | 0.0e+00 | 1.48e-05 | 1.48e-05 | 0.0e+00 | 0.0e+00 | 5.53e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 7.73e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 1.48e-05 | 0.00e+00 | 0.0e+00 | 1.1e-05 | 0.00e+00 | 1.1e-05 | 0.0e+00 | 0.0e+00 | 1.48e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.58e-05 | 1.10e-05 | 0.0e+00 | 1.10e-05 | 0.0e+00 | 1.10e-05 | 0.00e+00 | 0.00e+00 | 2.96e-05 | 0.00e+00 | 1.48e-05 | 0.00e+00 | 0.00e+00 | 1.10e-05 | 0.0e+00 | 1.48e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 5.15e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 1.1e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 1.10e-05 | 0.00e+00 | 0.00e+00 | 1.48e-05 | 1.1e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 1.48e-05 | 0.0e+00 | 1.1e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 1.1e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 1.48e-05 | 0.0e+00 | 0.0e+00 | 2.96e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 2.96e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 4.43e-05 | 2.96e-05 | 1.48e-05 | 1.48e-05 | 1.48e-05 | 1.48e-05 | 3.67e-05 | 2.58e-05 | 0.00e+00 | 1.1e-05 | 1.1e-05 | 1.1e-05 | 1.1e-05 | 1.1e-05 | 1.1e-05 | 1.1e-05 | 1.1e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 5 | 0.0521285 | 0.0126292 | 0.0479568 | 0.0082196 | 0.0234903 | 0.0073818 | 0.0049712 | 0.0303256 | 0.0369273 | 0.0382607 | 0.0003741 | 0.0368926 | 0.0211030 | 0.0260748 | 0.0173939 | 0.0017564 | 0.0034267 | 0.0123949 | 0.0001483 | 0.0561596 | 0.0085439 | 0.0070987 | 0.0020747 | 0.0008372 | 0.0144790 | 0.0058633 | 0.0074459 | 0.0063433 | 0.0014121 | 0.0114320 | 0.0111031 | 0.0019618 | 0.0039772 | 0.0002470 | 0.0076568 | 0.0068575 | 0.0084379 | 0.0071601 | 0.0063729 | 0.0058245 | 0.0011350 | 0.0028252 | 0.0027219 | 0.0040362 | 0.0025869 | 0.0059253 | 0.0025955 | 0.0020665 | 0.0047928 | 0.0033041 | 0.0082117 | 0.0021800 | 0.0075343 | 0.0047413 | 0.0017977 | 0.0046410 | 0.0096030 | 0.0039631 | 0.0060577 | 0.0051580 | 0.0024549 | 0.0038768 | 0.0049488 | 0.0013663 | 0.0021207 | 0.0003298 | 0.0011165 | 0.0007756 | 0.0049002 | 0.0005909 | 0.0021507 | 0.0022042 | 0.0010030 | 0.0060310 | 0.0015236 | 0.0039558 | 0.0029360 | 0.0028426 | 0.0038460 | 0.0030549 | 0.0059218 | 0.0029678 | 0.0029771 | 0.0007720 | 0.0011880 | 0.0101439 | 0.0004429 | 0.0024967 | 0.0091579 | 0.0040991 | 0.0003044 | 0.0023041 | 0.0005367 | 0.0022411 | 0.0027642 | 0.0022231 | 0.0007089 | 0.0005809 | 0.0014266 | 0.0002474 | 0.0022954 | 0.0048116 | 0.0049885 | 0.0001630 | 0.0011738 | 0.0036609 | 0.0028400 | 0.0046391 | 0.0001243 | 0.0011155 | 0.0003028 | 0.0015784 | 0.0018364 | 0.0004499 | 0.0040739 | 0.0005560 | 0.0012045 | 0.0009873 | 0.0004066 | 0.0002655 | 0.0010602 | 0.0017099 | 0.0007451 | 0.0009880 | 0.0018731 | 0.0023783 | 0.0011591 | 0.0015560 | 0.0025964 | 0.0019487 | 0.0037955 | 0.0008677 | 0.0022813 | 0.0030916 | 0.0004560 | 0.0003979 | 0.0000428 | 0.0009096 | 0.0009148 | 0.0014823 | 0.0011830 | 0.0018725 | 0.0033086 | 0.0000157 | 0.0018952 | 0.0001927 | 0.0020675 | 0.0004164 | 0.0019531 | 0.0000485 | 0.0015275 | 0.0006615 | 0.0011020 | 0.0026403 | 0.0002066 | 0.0007589 | 0.0033403 | 0.0018754 | 0.0008515 | 0.0006835 | 0.0006365 | 0.0007473 | 0.0009419 | 0.0008123 | 0.0012325 | 0.0012525 | 0.0006873 | 0.0005366 | 0.0009792 | 0.0012739 | 0.0003220 | 0.0016774 | 0.0003878 | 0.0006650 | 0.0008271 | 0.0006393 | 0.0015401 | 0.0024165 | 0.0009013 | 0.0005025 | 0.0008457 | 0.0013136 | 0.0002101 | 0.0003370 | 0.0000526 | 0.0004983 | 0.0006734 | 0.0015015 | 0.0012327 | 0.0006588 | 0.0003140 | 0.0009357 | 0.0001647 | 0.0010964 | 0.0011465 | 0.0001107 | 0.0016717 | 0.0004173 | 0.0012532 | 0.0006206 | 0.0008818 | 0.0003494 | 0.0001815 | 0.0004109 | 0.0005164 | 0.0007718 | 0.0008979 | 0.0003408 | 0.0007521 | 0.0007212 | 0.0003385 | 0.0001213 | 0.0006255 | 0.0025355 | 0.0003642 | 0.0001854 | 0.0004619 | 0.0007607 | 0.0002892 | 0.0001047 | 0.0020783 | 0.0002206 | 0.0009054 | 0.0006823 | 0.0014420 | 0.0004998 | 0.0003007 | 0.0004866 | 0.0001480 | 0.0004122 | 0.0001411 | 0.0001539 | 0.0003667 | 0.0001318 | 0.0003277 | 0.0007867 | 0.0004785 | 0.0004066 | 0.0003923 | 0.0007952 | 0.0002898 | 0.0003186 | 0.0001828 | 0.0006328 | 0.0003038 | 0.0002764 | 0.0003064 | 0.0006334 | 0.0003243 | 0.0012071 | 0.0001468 | 0.0004723 | 0.0006981 | 0.0012915 | 0.0002264 | 0.0001458 | 0.0003527 | 0.0007028 | 0.0001774 | 0.0000893 | 0.0001520 | 0.0002557 | 0.0010999 | 0.0007824 | 0.0010493 | 0.0008261 | 0.0002223 | 0.0008761 | 0.0001336 | 0.0010951 | 0.0005700 | 0.0002769 | 0.0004159 | 0.0002277 | 0.0012067 | 0.0010638 | 0.0005262 | 0.0002205 | 0.0002684 | 0.0002861 | 0.0003428 | 0.0011985 | 0.0004906 | 0.0003457 | 0.0000636 | 0.0004054 | 0.0001963 | 0.0007139 | 0.0003516 | 0.0006098 | 0.0009254 | 0.0001635 | 0.0002797 | 0.0002069 | 0.0005924 | 0.0002958 | 0.0003110 | 0.0002457 | 0.0000967 | 0.0009025 | 0.0006700 | 0.0005676 | 0.0005642 | 0.0005088 | 0.0011292 | 0.0001481 | 0.0000849 | 0.0003684 | 0.0011064 | 0.0001548 | 0.0000613 | 0.0004008 | 0.0003486 | 0.0003262 | 0.0005575 | 0.0005870 | 0.0002091 | 0.0001313 | 0.0001810 | 0.0007390 | 0.0004234 | 0.0004220 | 0.0004304 | 0.0003200 | 0.0008600 | 0.0009225 | 0.0010668 | 0.0003054 | 0.0004162 | 0.0006813 | 0.0006299 | 0.0000408 | 0.0004122 | 0.0004249 | 0.0013035 | 0.0027402 | 0.0002476 | 0.0007144 | 0.0005243 | 0.0001925 | 0.0003927 | 0.0001057 | 3.40e-06 | 0.0008126 | 0.0000520 | 0.0000910 | 0.0002758 | 9.91e-05 | 0.0002943 | 3.69e-05 | 0.0000699 | 0.0003400 | 0.0001099 | 0.0000624 | 0.0003706 | 0.0001099 | 0.0004187 | 0.0003586 | 0.0001979 | 0.0009112 | 0.0001681 | 0.0004007 | 0.0001345 | 0.0000273 | 0.0006246 | 0.0002605 | 4.18e-05 | 0.0000733 | 0.0002872 | 0.0005364 | 0.0001478 | 0.0002800 | 0.0002530 | 0.0002891 | 0.0004174 | 0.0001036 | 0.0000066 | 0.0001119 | 0.0002296 | 0.0000561 | 0.0002127 | 0.0001582 | 0.0001913 | 0.0001983 | 0.0002626 | 0.0001401 | 0.0001883 | 0.0002108 | 0.0004461 | 0.0000593 | 2.72e-05 | 0.0001212 | 4.84e-05 | 0.0000851 | 0.0000337 | 0.0001823 | 0.0000962 | 0.0001444 | 0.0002131 | 0.0003535 | 0.0000539 | 0.0001000 | 0.0001171 | 0.0000898 | 0.0003764 | 0.0000693 | 0.0004718 | 0.0000897 | 0.0002322 | 4.60e-05 | 0.0001341 | 6.13e-05 | 0.0005396 | 5.73e-05 | 0.0002736 | 0.0001442 | 0.0001791 | 0.0003124 | 0.0002393 | 0.00e+00 | 0.0002162 | 0.0000864 | 5.39e-05 | 0.0002371 | 2.44e-05 | 0.0000995 | 0.0002533 | 0.0002790 | 0.0000347 | 0.0000463 | 0.0000535 | 2.85e-05 | 0.0000848 | 0.0000612 | 4.28e-05 | 0.0001076 | 8.06e-05 | 0.0002669 | 0.0002322 | 2.33e-05 | 6.60e-06 | 0.0004660 | 0.0001572 | 0.0001499 | 0.0003548 | 0.0002912 | 0.0001075 | 0.0003487 | 0.0001381 | 0.0006669 | 0.0001380 | 0.0000691 | 0.0001743 | 0.0001294 | 0.0001469 | 1.99e-05 | 0.0001120 | 4.97e-05 | 5.81e-05 | 2.33e-05 | 8.29e-05 | 9.80e-06 | 0.0001486 | 0.0001199 | 6.22e-05 | 9.94e-05 | 0.0001614 | 0.0001856 | 3.29e-05 | 0.0000273 | 1.57e-05 | 0.0000729 | 2.26e-05 | 0.0000709 | 1.70e-05 | 4.55e-05 | 2.53e-05 | 1.08e-05 | 0.0000416 | 1.50e-05 | 9.10e-06 | 0.0001755 | 3.59e-05 | 0.0000716 | 0.0002246 | 0.0001041 | 0.0001874 | 0.0003325 | 1.94e-05 | 0.0000950 | 0.0000959 | 9.47e-05 | 0.0005314 | 0.0001280 | 4.04e-05 | 0.0001782 | 1.99e-05 | 0.0001085 | 0.0001601 | 1.92e-05 | 0.0002816 | 0.0001420 | 0.0000182 | 4.83e-05 | 2.44e-05 | 9.20e-05 | 0.0000590 | 9.30e-06 | 5.76e-05 | 0.0000773 | 0.0000570 | 0.0002228 | 3.93e-05 | 0.0001871 | 4.43e-05 | 1.11e-05 | 6.91e-05 | 0.0000982 | 2.33e-05 | 0.0001478 | 0.0000782 | 0.0001162 | 1.15e-05 | 0.0001536 | 6.15e-05 | 2.61e-05 | 4.18e-05 | 4.48e-05 | 0.0001073 | 4.20e-06 | 0.0000864 | 0.0000740 | 0.0001864 | 2.97e-05 | 3.52e-05 | 1.33e-05 | 0.0002904 | 3.74e-05 | 0.0000275 | 2.38e-05 | 0.0000647 | 0.0001225 | 0.0000989 | 1.67e-05 | 0.0000339 | 0.0000108 | 1.67e-05 | 5.56e-05 | 1.75e-05 | 2.24e-05 | 2.83e-05 | 0.0001546 | 0.0002708 | 0.0003163 | 0.0000729 | 0.0000498 | 0.0001436 | 0.0002087 | 0.0002586 | 0.0001869 | 5.66e-05 | 3.34e-05 | 0.0002778 | 6.91e-05 | 5.79e-05 | 5.92e-05 | 1.52e-05 | 0.0001686 | 0.0001142 | 0.0003373 | 0.00e+00 | 0.0000561 | 0.0001323 | 0.0000556 | 2.40e-06 | 4.20e-06 | 2.40e-06 | 0.00e+00 | 0.0000679 | 3.96e-05 | 0.00e+00 | 0.00e+00 | 0.0001196 | 3.37e-05 | 0.00e+00 | 5.40e-05 | 6.67e-05 | 0.0000863 | 1.87e-05 | 4.77e-05 | 0.00e+00 | 4.20e-06 | 0.0000720 | 0.0001215 | 0.0002375 | 5.18e-05 | 2.41e-05 | 0.0001570 | 0.0000499 | 0.0002536 | 0.0000391 | 1.45e-05 | 3.08e-05 | 1.01e-05 | 0.0003351 | 1.15e-05 | 5.70e-05 | 0.00e+00 | 1.33e-05 | 0.0001643 | 0.0000553 | 0.0000966 | 0.0001002 | 4.20e-06 | 1.25e-05 | 4.20e-06 | 4.90e-06 | 0.0001256 | 0.0002074 | 0.0001961 | 2.80e-05 | 0.0000177 | 2.40e-06 | 1.60e-05 | 8.78e-05 | 2.53e-05 | 4.70e-05 | 7.6e-06 | 0.0000834 | 1.62e-05 | 0.0001415 | 1.08e-05 | 0.0001403 | 3.15e-05 | 7.09e-05 | 5.27e-05 | 0.0001095 | 4.05e-05 | 1.87e-05 | 2.02e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.60e-05 | 4.82e-05 | 0.0002233 | 5.90e-06 | 0.0000308 | 4.48e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 2.19e-05 | 1.25e-05 | 1.26e-05 | 0.0e+00 | 0.0e+00 | 1.62e-05 | 0.0e+00 | 0.0001762 | 0.00e+00 | 0.0e+00 | 2.40e-06 | 4.58e-05 | 1.28e-05 | 2.34e-05 | 1.92e-05 | 3.40e-06 | 1.70e-05 | 9.10e-06 | 0.0000487 | 0.0e+00 | 2.41e-05 | 0.0e+00 | 1.70e-05 | 2.29e-05 | 6.90e-06 | 0.0e+00 | 1.08e-05 | 0.0e+00 | 4.16e-05 | 4.20e-06 | 2.29e-05 | 2.04e-05 | 1.08e-05 | 0.0e+00 | 0.0e+00 | 1.91e-05 | 0.0000473 | 0.0000990 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.01e-05 | 0.00e+00 | 0.0000637 | 6.07e-05 | 4.20e-06 | 6.60e-06 | 3.18e-05 | 5.90e-06 | 8.40e-06 | 9.1e-06 | 0.00e+00 | 0.0000895 | 0.0002087 | 7.05e-05 | 0.0001014 | 4.90e-06 | 0.0e+00 | 3.79e-05 | 1.57e-05 | 8.40e-06 | 9.10e-06 | 0.0e+00 | 2.4e-06 | 1.57e-05 | 0.0000229 | 0.0000588 | 0.0e+00 | 0.0000832 | 0.00e+00 | 0.0001224 | 4.20e-06 | 4.20e-06 | 4.2e-06 | 6.60e-06 | 4.90e-06 | 4.20e-06 | 9.10e-06 | 1.50e-05 | 2.40e-06 | 6.60e-06 | 4.57e-05 | 4.2e-06 | 5.90e-06 | 8.40e-06 | 3.40e-06 | 0.0002029 | 1.67e-05 | 8.3e-06 | 0.0e+00 | 0.0001137 | 0.0001274 | 0.0003881 | 0.0000477 | 0.0000576 | 0.0000879 | 4.63e-05 | 0.0001258 | 8.40e-06 | 5.70e-05 | 4.74e-05 | 3.41e-05 | 3.30e-05 | 0.0002480 | 0.0e+00 | 0.0e+00 | 0.0000145 | 2.01e-05 | 1.70e-05 | 4.20e-06 | 4.90e-06 | 2.04e-05 | 0.0e+00 | 7.76e-05 | 1.40e-05 | 2.09e-05 | 2.4e-06 | 2.40e-06 | 6.80e-05 | 1.33e-05 | 5.01e-05 | 9.10e-06 | 2.93e-05 | 6.15e-05 | 2.41e-05 | 5.46e-05 | 4.20e-06 | 1.01e-05 | 5.39e-05 | 2.78e-05 | 0.00e+00 | 8.40e-06 | 0.00e+00 | 1.60e-05 | 2.4e-06 | 1.67e-05 | 2.26e-05 | 7.60e-06 | 4.90e-06 | 1.77e-05 | 9.11e-05 | 1.03e-05 | 1.60e-05 | 2.36e-05 | 2.69e-05 | 5.90e-06 | 0.0000649 | 3.59e-05 | 4.35e-05 | 1.67e-05 | 2.4e-06 | 6.60e-06 | 2.40e-06 | 2.54e-05 | 1.50e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 5.90e-06 | 5.90e-06 | 1.01e-05 | 2.44e-05 | 1.11e-05 | 1.35e-05 | 2.40e-06 | 9.10e-06 | 2.40e-06 | 3.29e-05 | 6.60e-06 | 6.60e-06 | 3.44e-05 | 0.0e+00 | 4.20e-06 | 9.10e-06 | 6.60e-06 | 0.00e+00 | 0.0e+00 | 2.4e-06 | 1.15e-05 | 5.90e-06 | 0.0e+00 | 1.57e-05 | 9.80e-06 | 4.20e-06 | 6.60e-06 | 0.00e+00 | 2.26e-05 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 6.60e-06 | 1.75e-05 | 6.60e-06 | 0.00e+00 | 1.35e-05 | 6.90e-06 | 5.33e-05 | 0.00e+00 | 0.00e+00 | 1.11e-05 | 0.00e+00 | 0.00e+00 | 3.40e-06 | 0.00e+00 | 9.10e-06 | 1.15e-05 | 0.00e+00 | 4.20e-06 | 2.40e-06 | 2.4e-06 | 1.75e-05 | 5.90e-06 | 5.93e-05 | 9.30e-06 | 1.75e-05 | 2.46e-05 | 2.40e-06 | 1.97e-05 | 2.4e-06 | 6.60e-06 | 2.83e-05 | 9.8e-06 | 1.08e-05 | 2.78e-05 | 4.9e-06 | 4.90e-06 | 4.9e-06 | 1.97e-05 | 3.35e-05 | 2.4e-06 | 2.4e-06 | 2.19e-05 | 1.08e-05 | 6.6e-06 | 9.30e-06 | 1.01e-05 | 2.4e-06 | 2.4e-06 | 2.40e-06 | 6.60e-06 | 2.4e-06 | 6.6e-06 | 3.15e-05 | 5.90e-06 | 3.08e-05 | 2.4e-06 | 2.4e-06 | 2.4e-06 | 2.40e-06 | 2.4e-06 | 2.4e-06 | 2.4e-06 | 2.4e-06 | 2.40e-06 | 2.40e-06 | 2.4e-06 | 2.4e-06 | 2.40e-06 | 2.4e-06 | 2.4e-06 | 2.4e-06 | 2.40e-06 | 2.4e-06 | 1.08e-05 | 1.85e-05 | 2.4e-06 | 2.40e-06 | 2.40e-06 | 2.4e-06 | 1.08e-05 | 2.4e-06 | 4.20e-06 | 0.00e+00 | 1.18e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 8.40e-06 | 2.22e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 4.2e-06 | 1.18e-05 | 0.00e+00 | 0.00e+00 | 8.40e-06 | 4.20e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 1.38e-05 | 7.6e-06 | 3.4e-06 | 7.60e-06 | 3.4e-06 | 0.00e+00 | 0.00e+00 | 8.40e-06 | 1.26e-05 | 0.00e+00 | 0.00e+00 | 4.2e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 4.2e-06 | 0.00e+00 | 0.0e+00 | 4.2e-06 | 4.2e-06 | 8.4e-06 | 8.4e-06 | 4.2e-06 | 4.2e-06 | 4.2e-06 | 4.2e-06 | 4.2e-06 | 4.2e-06 | 4.2e-06 | 4.2e-06 | 4.2e-06 | 4.20e-06 | 4.2e-06 | 4.20e-06 | 4.2e-06 | 4.2e-06 | 4.20e-06 | 4.2e-06 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 6 | 0.0475533 | 0.0104202 | 0.0425646 | 0.0070249 | 0.0253387 | 0.0093975 | 0.0033458 | 0.0587425 | 0.0318070 | 0.0632965 | 0.0002642 | 0.0407839 | 0.0249075 | 0.0111618 | 0.0111849 | 0.0005491 | 0.0011519 | 0.0127817 | 0.0001773 | 0.0209852 | 0.0133259 | 0.0037643 | 0.0007260 | 0.0009179 | 0.0246304 | 0.0037168 | 0.0057409 | 0.0035203 | 0.0013465 | 0.0050461 | 0.0124686 | 0.0024234 | 0.0031352 | 0.0002974 | 0.0062820 | 0.0109843 | 0.0061743 | 0.0076794 | 0.0016359 | 0.0098646 | 0.0005620 | 0.0023311 | 0.0017142 | 0.0026789 | 0.0016884 | 0.0043984 | 0.0021228 | 0.0005721 | 0.0104076 | 0.0012269 | 0.0076861 | 0.0018256 | 0.0043567 | 0.0014200 | 0.0012423 | 0.0039136 | 0.0064256 | 0.0028930 | 0.0070205 | 0.0025551 | 0.0026201 | 0.0116393 | 0.0043673 | 0.0010678 | 0.0015913 | 0.0001693 | 0.0003778 | 0.0004700 | 0.0036186 | 0.0008242 | 0.0036921 | 0.0017720 | 0.0005401 | 0.0154761 | 0.0010611 | 0.0015870 | 0.0012443 | 0.0022184 | 0.0023277 | 0.0016820 | 0.0041649 | 0.0035759 | 0.0030725 | 0.0005087 | 0.0004286 | 0.0122304 | 0.0003387 | 0.0014649 | 0.0053869 | 0.0052178 | 0.0003114 | 0.0017150 | 0.0002350 | 0.0018677 | 0.0019882 | 0.0023763 | 0.0003934 | 0.0002231 | 0.0023724 | 0.0001143 | 0.0021787 | 0.0030806 | 0.0103949 | 0.0001580 | 0.0002650 | 0.0060285 | 0.0101861 | 0.0087292 | 0.0000320 | 0.0004547 | 0.0001566 | 0.0011584 | 0.0020459 | 0.0005053 | 0.0079319 | 0.0017053 | 0.0005546 | 0.0003308 | 0.0003221 | 0.0000886 | 0.0008101 | 0.0006756 | 0.0007960 | 0.0003722 | 0.0012901 | 0.0040291 | 0.0012373 | 0.0010141 | 0.0013993 | 0.0043082 | 0.0020313 | 0.0012796 | 0.0013553 | 0.0026747 | 0.0001654 | 0.0002150 | 0.0000202 | 0.0009573 | 0.0007879 | 0.0014737 | 0.0026313 | 0.0016075 | 0.0043435 | 0.0000362 | 0.0043558 | 0.0000392 | 0.0043775 | 0.0002361 | 0.0013346 | 0.0000159 | 0.0015012 | 0.0007492 | 0.0006959 | 0.0051479 | 0.0001363 | 0.0015446 | 0.0044323 | 0.0016262 | 0.0004834 | 0.0005287 | 0.0002838 | 0.0006810 | 0.0007741 | 0.0033806 | 0.0013612 | 0.0005355 | 0.0004581 | 0.0003124 | 0.0007860 | 0.0009612 | 0.0006691 | 0.0003534 | 0.0003137 | 0.0006264 | 0.0005269 | 0.0005698 | 0.0014557 | 0.0040020 | 0.0015542 | 0.0005062 | 0.0009609 | 0.0009660 | 0.0001130 | 0.0001474 | 0.0000145 | 0.0006170 | 0.0004202 | 0.0006595 | 0.0019874 | 0.0008943 | 0.0005200 | 0.0011095 | 0.0001739 | 0.0014350 | 0.0009068 | 0.0000436 | 0.0007247 | 0.0002639 | 0.0008688 | 0.0003487 | 0.0012797 | 0.0003458 | 0.0001174 | 0.0002144 | 0.0003891 | 0.0013494 | 0.0013794 | 0.0001359 | 0.0003513 | 0.0007190 | 0.0002363 | 0.0001332 | 0.0004022 | 0.0072917 | 0.0003817 | 0.0001187 | 0.0003537 | 0.0008657 | 0.0001261 | 0.0000968 | 0.0012792 | 0.0000649 | 0.0010361 | 0.0005127 | 0.0012710 | 0.0002305 | 0.0001581 | 0.0072222 | 0.0000968 | 0.0002077 | 0.0000752 | 0.0001245 | 0.0004368 | 0.0000550 | 0.0002705 | 0.0014783 | 0.0006249 | 0.0003160 | 0.0004566 | 0.0008936 | 0.0001612 | 0.0001289 | 0.0001404 | 0.0009748 | 0.0002851 | 0.0002795 | 0.0002808 | 0.0008524 | 0.0004045 | 0.0025370 | 0.0001842 | 0.0003411 | 0.0008988 | 0.0009326 | 0.0001596 | 0.0000463 | 0.0001837 | 0.0002475 | 0.0001087 | 0.0000622 | 0.0002797 | 0.0003423 | 0.0010207 | 0.0014665 | 0.0014255 | 0.0013327 | 0.0001373 | 0.0011591 | 0.0000451 | 0.0013092 | 0.0008212 | 0.0001707 | 0.0002363 | 0.0001678 | 0.0006956 | 0.0026484 | 0.0012361 | 0.0001371 | 0.0001629 | 0.0002055 | 0.0005611 | 0.0008894 | 0.0005066 | 0.0001388 | 0.0000115 | 0.0001245 | 0.0000379 | 0.0002936 | 0.0007249 | 0.0005674 | 0.0016997 | 0.0001173 | 0.0001870 | 0.0000856 | 0.0006237 | 0.0002270 | 0.0002012 | 0.0003005 | 0.0000448 | 0.0010065 | 0.0011089 | 0.0003960 | 0.0012507 | 0.0003051 | 0.0010169 | 0.0002857 | 0.0000854 | 0.0002646 | 0.0009499 | 0.0000783 | 0.0000231 | 0.0001591 | 0.0004088 | 0.0002761 | 0.0009115 | 0.0003664 | 0.0001228 | 0.0001058 | 0.0002399 | 0.0013309 | 0.0002587 | 0.0004858 | 0.0006282 | 0.0004422 | 0.0003908 | 0.0008217 | 0.0009888 | 0.0003056 | 0.0002415 | 0.0007560 | 0.0003990 | 0.0000000 | 0.0002460 | 0.0008445 | 0.0022994 | 0.0004388 | 0.0002391 | 0.0007427 | 0.0019976 | 0.0006680 | 0.0003388 | 0.0000276 | 0.00e+00 | 0.0006607 | 0.0000159 | 0.0001532 | 0.0002067 | 4.40e-06 | 0.0001651 | 3.46e-05 | 0.0000722 | 0.0001375 | 0.0000522 | 0.0000420 | 0.0001754 | 0.0000825 | 0.0005670 | 0.0002905 | 0.0001944 | 0.0008327 | 0.0000866 | 0.0001330 | 0.0000204 | 0.0000204 | 0.0008612 | 0.0001944 | 5.92e-05 | 0.0001805 | 0.0004991 | 0.0013187 | 0.0002456 | 0.0003357 | 0.0001925 | 0.0001575 | 0.0005081 | 0.0002242 | 0.0000044 | 0.0000636 | 0.0002938 | 0.0000232 | 0.0000885 | 0.0001000 | 0.0001303 | 0.0000768 | 0.0001602 | 0.0000969 | 0.0000937 | 0.0001690 | 0.0002311 | 0.0000361 | 2.75e-05 | 0.0000854 | 3.05e-05 | 0.0000088 | 0.0000088 | 0.0001895 | 0.0000652 | 0.0002025 | 0.0003474 | 0.0002379 | 0.0000522 | 0.0000175 | 0.0000898 | 0.0001300 | 0.0002472 | 0.0000550 | 0.0005218 | 0.0000044 | 0.0002115 | 3.03e-05 | 0.0000435 | 4.04e-05 | 0.0011999 | 2.19e-05 | 0.0003401 | 0.0000566 | 0.0006926 | 0.0002798 | 0.0002003 | 0.00e+00 | 0.0002280 | 0.0000364 | 7.20e-06 | 0.0001558 | 0.00e+00 | 0.0000835 | 0.0004280 | 0.0001979 | 0.0000550 | 0.0000202 | 0.0000204 | 5.36e-05 | 0.0001191 | 0.0000246 | 7.94e-05 | 0.0000593 | 2.46e-05 | 0.0003730 | 0.0001070 | 4.50e-05 | 8.80e-06 | 0.0005206 | 0.0000912 | 0.0000666 | 0.0007225 | 0.0006666 | 0.0000476 | 0.0000945 | 0.0001982 | 0.0013570 | 0.0000753 | 0.0000580 | 0.0001113 | 0.0000320 | 0.0000391 | 4.35e-05 | 0.0001235 | 3.79e-05 | 2.19e-05 | 0.00e+00 | 2.48e-05 | 7.20e-06 | 0.0000479 | 0.0000810 | 3.03e-05 | 4.62e-05 | 0.0000522 | 0.0001300 | 8.80e-06 | 0.0000204 | 4.40e-06 | 0.0000534 | 3.48e-05 | 0.0000493 | 1.15e-05 | 2.89e-05 | 0.00e+00 | 1.59e-05 | 0.0000290 | 0.00e+00 | 4.40e-06 | 0.0000826 | 7.20e-06 | 0.0000506 | 0.0002288 | 0.0001376 | 0.0000969 | 0.0004930 | 7.20e-06 | 0.0000609 | 0.0000276 | 8.71e-05 | 0.0005767 | 0.0001144 | 3.20e-05 | 0.0002282 | 3.07e-05 | 0.0000305 | 0.0001083 | 4.07e-05 | 0.0002170 | 0.0001538 | 0.0000160 | 3.17e-05 | 2.32e-05 | 7.40e-05 | 0.0000449 | 2.30e-05 | 4.21e-05 | 0.0000432 | 0.0000550 | 0.0001139 | 8.80e-06 | 0.0000609 | 1.45e-05 | 0.00e+00 | 2.61e-05 | 0.0000492 | 3.35e-05 | 0.0000923 | 0.0000465 | 0.0000361 | 1.16e-05 | 0.0000333 | 1.59e-05 | 5.77e-05 | 2.31e-05 | 0.00e+00 | 0.0000317 | 7.20e-06 | 0.0000737 | 0.0001008 | 0.0001171 | 2.89e-05 | 7.08e-05 | 8.80e-06 | 0.0002516 | 2.02e-05 | 0.0000202 | 2.04e-05 | 0.0000436 | 0.0001155 | 0.0001171 | 1.15e-05 | 0.0000260 | 0.0000000 | 6.93e-05 | 9.25e-05 | 0.00e+00 | 4.40e-06 | 0.00e+00 | 0.0000724 | 0.0004288 | 0.0003303 | 0.0000724 | 0.0000593 | 0.0000449 | 0.0000893 | 0.0002434 | 0.0000880 | 7.20e-06 | 1.59e-05 | 0.0000896 | 2.90e-05 | 1.87e-05 | 0.00e+00 | 1.16e-05 | 0.0000797 | 0.0000432 | 0.0000639 | 0.00e+00 | 0.0000476 | 0.0000550 | 0.0000088 | 7.20e-06 | 0.00e+00 | 0.00e+00 | 4.40e-06 | 0.0001397 | 2.46e-05 | 0.00e+00 | 0.00e+00 | 0.0001359 | 8.80e-06 | 0.00e+00 | 4.61e-05 | 4.77e-05 | 0.0000275 | 4.40e-06 | 1.16e-05 | 0.00e+00 | 0.00e+00 | 0.0000665 | 0.0000826 | 0.0002648 | 4.40e-06 | 1.59e-05 | 0.0001117 | 0.0002927 | 0.0005494 | 0.0000608 | 0.00e+00 | 1.16e-05 | 8.80e-06 | 0.0003409 | 2.46e-05 | 7.11e-05 | 0.00e+00 | 3.90e-05 | 0.0000072 | 0.0000667 | 0.0000751 | 0.0001604 | 0.00e+00 | 4.40e-06 | 7.20e-06 | 0.00e+00 | 0.0000291 | 0.0001474 | 0.0002128 | 0.00e+00 | 0.0000000 | 0.00e+00 | 0.00e+00 | 2.19e-05 | 8.80e-06 | 1.16e-05 | 0.0e+00 | 0.0001186 | 4.40e-06 | 0.0000811 | 0.00e+00 | 0.0001125 | 8.80e-06 | 5.95e-05 | 1.16e-05 | 0.0000319 | 2.02e-05 | 0.00e+00 | 3.46e-05 | 4.40e-06 | 4.40e-06 | 0.0e+00 | 3.17e-05 | 2.30e-05 | 0.0000939 | 0.00e+00 | 0.0000116 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 1.31e-05 | 1.15e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 4.40e-06 | 0.0e+00 | 0.0000551 | 1.16e-05 | 0.0e+00 | 7.20e-06 | 0.00e+00 | 1.87e-05 | 6.08e-05 | 4.40e-06 | 4.40e-06 | 0.00e+00 | 4.40e-06 | 0.0000088 | 2.6e-05 | 0.00e+00 | 0.0e+00 | 4.40e-06 | 1.16e-05 | 4.40e-06 | 0.0e+00 | 0.00e+00 | 4.4e-06 | 2.91e-05 | 0.00e+00 | 0.00e+00 | 4.40e-06 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 4.06e-05 | 0.0000462 | 0.0000435 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000807 | 4.34e-05 | 0.00e+00 | 0.00e+00 | 2.04e-05 | 8.80e-06 | 4.40e-06 | 0.0e+00 | 0.00e+00 | 0.0000610 | 0.0001074 | 1.89e-05 | 0.0004077 | 0.00e+00 | 0.0e+00 | 2.02e-05 | 1.87e-05 | 4.40e-06 | 1.16e-05 | 0.0e+00 | 0.0e+00 | 1.16e-05 | 0.0000346 | 0.0001111 | 0.0e+00 | 0.0001087 | 7.20e-06 | 0.0000476 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 7.20e-06 | 0.00e+00 | 4.40e-06 | 0.00e+00 | 2.04e-05 | 8.80e-06 | 3.33e-05 | 2.32e-05 | 4.4e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0002470 | 1.15e-05 | 4.4e-06 | 0.0e+00 | 0.0001473 | 0.0001961 | 0.0004273 | 0.0000521 | 0.0001000 | 0.0001557 | 2.60e-05 | 0.0000755 | 1.89e-05 | 2.19e-05 | 1.59e-05 | 7.20e-06 | 0.00e+00 | 0.0000835 | 0.0e+00 | 0.0e+00 | 0.0000305 | 2.46e-05 | 0.00e+00 | 0.00e+00 | 1.16e-05 | 0.00e+00 | 0.0e+00 | 9.27e-05 | 3.62e-05 | 1.45e-05 | 0.0e+00 | 4.40e-06 | 2.31e-05 | 0.00e+00 | 2.31e-05 | 0.00e+00 | 4.94e-05 | 5.07e-05 | 6.21e-05 | 2.46e-05 | 1.31e-05 | 8.80e-06 | 7.52e-05 | 2.02e-05 | 3.17e-05 | 3.05e-05 | 8.80e-06 | 1.60e-05 | 8.8e-06 | 8.80e-06 | 8.80e-06 | 3.47e-05 | 8.80e-06 | 1.60e-05 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 1.16e-05 | 1.59e-05 | 4.40e-06 | 0.0000044 | 1.59e-05 | 1.16e-05 | 4.40e-06 | 4.4e-06 | 1.89e-05 | 4.40e-06 | 4.06e-05 | 5.03e-05 | 4.40e-06 | 4.4e-06 | 4.40e-06 | 2.31e-05 | 1.16e-05 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 1.16e-05 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 4.4e-06 | 4.40e-06 | 1.16e-05 | 4.40e-06 | 1.59e-05 | 4.4e-06 | 4.4e-06 | 3.03e-05 | 4.40e-06 | 4.4e-06 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 4.40e-06 | 1.59e-05 | 4.4e-06 | 4.4e-06 | 4.40e-06 | 4.40e-06 | 0.00e+00 | 1.15e-05 | 0.00e+00 | 0.00e+00 | 1.45e-05 | 1.15e-05 | 0.00e+00 | 0.00e+00 | 1.45e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 7.20e-06 | 7.20e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 7.20e-06 | 7.20e-06 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 7.20e-06 | 1.15e-05 | 0.0e+00 | 7.20e-06 | 7.2e-06 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 1.15e-05 | 1.15e-05 | 7.2e-06 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 7.2e-06 | 0.00e+00 | 1.15e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 7.20e-06 | 7.2e-06 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 7.20e-06 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.15e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 1.15e-05 | 1.15e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 1.15e-05 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 1.15e-05 | 1.15e-05 | 1.15e-05 | 7.20e-06 | 7.2e-06 | 7.2e-06 | 7.2e-06 | 7.2e-06 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 7 | 0.0423722 | 0.0123893 | 0.0448190 | 0.0076899 | 0.0190306 | 0.0101755 | 0.0087774 | 0.1304179 | 0.0213220 | 0.0310704 | 0.0001554 | 0.0332453 | 0.0167780 | 0.0116126 | 0.0129719 | 0.0013982 | 0.0015147 | 0.0148361 | 0.0000388 | 0.0164285 | 0.0135545 | 0.0040780 | 0.0014370 | 0.0006214 | 0.0518098 | 0.0053985 | 0.0130884 | 0.0029517 | 0.0015924 | 0.0071850 | 0.0131661 | 0.0022138 | 0.0049713 | 0.0003884 | 0.0056315 | 0.0100590 | 0.0078064 | 0.0040780 | 0.0021361 | 0.0062141 | 0.0007379 | 0.0032236 | 0.0017089 | 0.0044664 | 0.0022138 | 0.0071073 | 0.0043499 | 0.0016312 | 0.0042722 | 0.0015147 | 0.0106416 | 0.0024080 | 0.0058257 | 0.0025245 | 0.0013982 | 0.0043110 | 0.0054762 | 0.0099814 | 0.0067190 | 0.0041945 | 0.0034566 | 0.0037673 | 0.0053208 | 0.0011651 | 0.0026798 | 0.0001554 | 0.0018254 | 0.0004272 | 0.0050489 | 0.0003107 | 0.0027575 | 0.0020196 | 0.0012040 | 0.0077676 | 0.0012817 | 0.0030682 | 0.0020196 | 0.0036896 | 0.0018642 | 0.0018254 | 0.0050878 | 0.0027575 | 0.0027575 | 0.0006602 | 0.0005826 | 0.0107970 | 0.0003495 | 0.0020973 | 0.0045440 | 0.0056703 | 0.0002719 | 0.0015147 | 0.0001165 | 0.0023303 | 0.0024468 | 0.0015147 | 0.0005049 | 0.0005826 | 0.0006602 | 0.0001554 | 0.0030294 | 0.0027963 | 0.0085832 | 0.0002719 | 0.0002330 | 0.0031847 | 0.0046606 | 0.0076899 | 0.0000777 | 0.0013593 | 0.0001554 | 0.0015147 | 0.0029905 | 0.0005049 | 0.0024080 | 0.0007768 | 0.0010486 | 0.0003884 | 0.0001942 | 0.0002330 | 0.0011651 | 0.0006214 | 0.0005826 | 0.0003107 | 0.0017089 | 0.0015535 | 0.0005826 | 0.0010098 | 0.0013982 | 0.0019419 | 0.0019419 | 0.0008156 | 0.0016312 | 0.0020973 | 0.0006991 | 0.0003884 | 0.0001165 | 0.0010875 | 0.0015924 | 0.0013593 | 0.0017089 | 0.0010486 | 0.0034954 | 0.0000000 | 0.0020973 | 0.0001942 | 0.0019419 | 0.0006991 | 0.0013982 | 0.0000388 | 0.0012428 | 0.0010875 | 0.0006214 | 0.0033012 | 0.0001554 | 0.0009709 | 0.0024468 | 0.0011651 | 0.0009709 | 0.0002330 | 0.0005826 | 0.0021361 | 0.0007379 | 0.0017089 | 0.0012040 | 0.0008933 | 0.0008156 | 0.0003884 | 0.0002330 | 0.0008544 | 0.0001942 | 0.0006214 | 0.0003495 | 0.0009321 | 0.0007379 | 0.0005437 | 0.0018254 | 0.0020973 | 0.0009709 | 0.0005049 | 0.0005826 | 0.0008544 | 0.0000388 | 0.0004272 | 0.0000000 | 0.0003884 | 0.0006214 | 0.0007768 | 0.0019031 | 0.0002719 | 0.0001554 | 0.0010098 | 0.0001165 | 0.0008933 | 0.0005826 | 0.0001554 | 0.0012428 | 0.0001942 | 0.0003495 | 0.0007768 | 0.0012040 | 0.0003495 | 0.0000388 | 0.0005826 | 0.0001942 | 0.0006602 | 0.0009709 | 0.0001942 | 0.0003107 | 0.0015924 | 0.0003495 | 0.0001554 | 0.0004661 | 0.0034954 | 0.0001165 | 0.0000777 | 0.0002330 | 0.0006214 | 0.0001165 | 0.0000388 | 0.0018254 | 0.0001554 | 0.0009321 | 0.0022914 | 0.0017089 | 0.0002719 | 0.0003495 | 0.0003495 | 0.0001554 | 0.0006602 | 0.0000388 | 0.0001165 | 0.0002719 | 0.0001165 | 0.0000777 | 0.0007379 | 0.0007379 | 0.0003107 | 0.0003495 | 0.0008156 | 0.0001942 | 0.0001554 | 0.0001942 | 0.0006991 | 0.0000777 | 0.0001554 | 0.0001165 | 0.0007379 | 0.0006602 | 0.0018254 | 0.0000000 | 0.0003495 | 0.0007379 | 0.0007379 | 0.0004272 | 0.0000388 | 0.0002330 | 0.0003107 | 0.0002330 | 0.0001165 | 0.0000388 | 0.0003495 | 0.0007768 | 0.0008544 | 0.0012040 | 0.0006602 | 0.0002330 | 0.0008156 | 0.0001942 | 0.0008933 | 0.0005437 | 0.0003495 | 0.0001165 | 0.0002330 | 0.0003495 | 0.0014758 | 0.0020584 | 0.0001554 | 0.0001554 | 0.0001165 | 0.0001554 | 0.0003884 | 0.0003107 | 0.0002719 | 0.0000000 | 0.0002719 | 0.0001554 | 0.0002719 | 0.0004272 | 0.0006214 | 0.0013593 | 0.0001165 | 0.0000388 | 0.0007768 | 0.0006214 | 0.0000777 | 0.0015147 | 0.0000388 | 0.0001165 | 0.0005437 | 0.0007768 | 0.0003107 | 0.0007379 | 0.0006214 | 0.0006214 | 0.0000777 | 0.0000000 | 0.0002330 | 0.0005049 | 0.0003107 | 0.0000388 | 0.0004272 | 0.0001942 | 0.0003107 | 0.0006991 | 0.0003884 | 0.0001165 | 0.0000000 | 0.0000388 | 0.0008156 | 0.0001942 | 0.0003107 | 0.0004661 | 0.0001165 | 0.0004272 | 0.0006214 | 0.0006602 | 0.0003107 | 0.0002719 | 0.0007768 | 0.0002719 | 0.0000777 | 0.0001942 | 0.0001942 | 0.0013205 | 0.0003107 | 0.0003107 | 0.0011651 | 0.0004661 | 0.0003495 | 0.0004272 | 0.0000777 | 0.00e+00 | 0.0003107 | 0.0000000 | 0.0001165 | 0.0001942 | 3.88e-05 | 0.0003495 | 3.88e-05 | 0.0000388 | 0.0002330 | 0.0000388 | 0.0000000 | 0.0001942 | 0.0000388 | 0.0005437 | 0.0001165 | 0.0001942 | 0.0006991 | 0.0000000 | 0.0004272 | 0.0000777 | 0.0000000 | 0.0003495 | 0.0000000 | 0.00e+00 | 0.0000388 | 0.0005049 | 0.0007379 | 0.0001942 | 0.0002719 | 0.0000000 | 0.0002330 | 0.0002719 | 0.0000388 | 0.0000388 | 0.0001554 | 0.0000777 | 0.0000777 | 0.0000777 | 0.0001942 | 0.0001942 | 0.0001942 | 0.0002330 | 0.0000388 | 0.0001165 | 0.0002330 | 0.0001554 | 0.0000388 | 3.88e-05 | 0.0001165 | 0.00e+00 | 0.0000777 | 0.0000777 | 0.0001165 | 0.0000000 | 0.0001165 | 0.0001165 | 0.0003495 | 0.0000777 | 0.0001165 | 0.0000777 | 0.0001165 | 0.0003495 | 0.0000777 | 0.0003884 | 0.0000000 | 0.0004272 | 0.00e+00 | 0.0000777 | 0.00e+00 | 0.0006602 | 0.00e+00 | 0.0002330 | 0.0000388 | 0.0004272 | 0.0002330 | 0.0001165 | 0.00e+00 | 0.0004661 | 0.0001554 | 3.88e-05 | 0.0000777 | 3.88e-05 | 0.0001165 | 0.0003107 | 0.0003495 | 0.0000777 | 0.0000000 | 0.0000388 | 0.00e+00 | 0.0000388 | 0.0000777 | 3.88e-05 | 0.0001165 | 0.00e+00 | 0.0000777 | 0.0000777 | 3.88e-05 | 0.00e+00 | 0.0003884 | 0.0001165 | 0.0000388 | 0.0003495 | 0.0007379 | 0.0001165 | 0.0001165 | 0.0001942 | 0.0006214 | 0.0001942 | 0.0000388 | 0.0000777 | 0.0000000 | 0.0000000 | 3.88e-05 | 0.0001554 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.0001554 | 0.0000388 | 0.00e+00 | 3.88e-05 | 0.0002719 | 0.0000000 | 3.88e-05 | 0.0000000 | 3.88e-05 | 0.0000777 | 0.00e+00 | 0.0000000 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0000000 | 3.88e-05 | 0.00e+00 | 0.0000777 | 3.88e-05 | 0.0001165 | 0.0004272 | 0.0001165 | 0.0000388 | 0.0003107 | 3.88e-05 | 0.0001165 | 0.0000777 | 7.77e-05 | 0.0003884 | 0.0001165 | 7.77e-05 | 0.0002719 | 0.00e+00 | 0.0003495 | 0.0002330 | 0.00e+00 | 0.0003107 | 0.0003884 | 0.0000000 | 0.00e+00 | 7.77e-05 | 0.00e+00 | 0.0000777 | 0.00e+00 | 3.88e-05 | 0.0002330 | 0.0001165 | 0.0002719 | 0.00e+00 | 0.0000388 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0000388 | 0.00e+00 | 0.0000777 | 0.0000000 | 0.0000777 | 0.00e+00 | 0.0000388 | 3.88e-05 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0000000 | 0.00e+00 | 0.0000388 | 0.0000388 | 0.0001554 | 0.00e+00 | 7.77e-05 | 0.00e+00 | 0.0007768 | 3.88e-05 | 0.0000388 | 0.00e+00 | 0.0000000 | 0.0000777 | 0.0003107 | 3.88e-05 | 0.0000000 | 0.0000000 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.0000777 | 0.0001942 | 0.0002719 | 0.0001554 | 0.0001165 | 0.0000388 | 0.0001942 | 0.0000777 | 0.0000388 | 0.00e+00 | 3.88e-05 | 0.0001165 | 7.77e-05 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0000388 | 0.0000388 | 0.0001554 | 0.00e+00 | 0.0000388 | 0.0001942 | 0.0000777 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000000 | 7.77e-05 | 0.00e+00 | 0.00e+00 | 0.0001942 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.0000777 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0001554 | 0.0000000 | 0.0001165 | 0.00e+00 | 0.00e+00 | 0.0001554 | 0.0000388 | 0.0005826 | 0.0000000 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0003107 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000000 | 0.0000388 | 0.0000388 | 0.0000777 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001554 | 0.0002330 | 0.0004661 | 0.00e+00 | 0.0000000 | 0.00e+00 | 0.00e+00 | 7.77e-05 | 7.77e-05 | 3.88e-05 | 0.0e+00 | 0.0000388 | 3.88e-05 | 0.0001942 | 0.00e+00 | 0.0001165 | 0.00e+00 | 3.88e-05 | 3.88e-05 | 0.0000388 | 7.77e-05 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 3.88e-05 | 3.88e-05 | 0.0000777 | 3.88e-05 | 0.0000000 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 7.77e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 7.77e-05 | 0.0e+00 | 0.0000777 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 7.77e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001554 | 0.0e+00 | 3.88e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 3.88e-05 | 0.0e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0000388 | 0.0000388 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000777 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 0.00e+00 | 0.0000777 | 0.0001554 | 3.88e-05 | 0.0002719 | 0.00e+00 | 0.0e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0000000 | 0.0002330 | 0.0e+00 | 0.0001165 | 0.00e+00 | 0.0000388 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0005049 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0000777 | 0.0001942 | 0.0001554 | 0.0000000 | 0.0000388 | 0.0000777 | 0.00e+00 | 0.0000000 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001554 | 0.0e+00 | 0.0e+00 | 0.0000388 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0000000 | 3.88e-05 | 3.88e-05 | 0.00e+00 | 0.0e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 7.77e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 7.77e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 0.0e+00 | 3.88e-05 | 3.88e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.88e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.88e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 3.88e-05 | 0.0e+00 | 3.88e-05 | 3.88e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 8 | 0.0360106 | 0.0074931 | 0.0316152 | 0.0056620 | 0.0871104 | 0.0093714 | 0.0025849 | 0.0385643 | 0.0267481 | 0.0365675 | 0.0003339 | 0.0308889 | 0.0209624 | 0.0116677 | 0.0136133 | 0.0003074 | 0.0022470 | 0.0091299 | 0.0002259 | 0.0206292 | 0.0102604 | 0.0037237 | 0.0006180 | 0.0007224 | 0.0376340 | 0.0034857 | 0.0025559 | 0.0050870 | 0.0008565 | 0.0044292 | 0.0138384 | 0.0017752 | 0.0029490 | 0.0004477 | 0.0051493 | 0.0116149 | 0.0037013 | 0.0152097 | 0.0017267 | 0.0085848 | 0.0006194 | 0.0016604 | 0.0015672 | 0.0020960 | 0.0025217 | 0.0037050 | 0.0027078 | 0.0005248 | 0.0095359 | 0.0029546 | 0.0052896 | 0.0014055 | 0.0052407 | 0.0011904 | 0.0013973 | 0.0048127 | 0.0071656 | 0.0012993 | 0.0059082 | 0.0018155 | 0.0016609 | 0.0092496 | 0.0028615 | 0.0007578 | 0.0017725 | 0.0002254 | 0.0004061 | 0.0004271 | 0.0023685 | 0.0006822 | 0.0027692 | 0.0018710 | 0.0004634 | 0.0171919 | 0.0010106 | 0.0016783 | 0.0012091 | 0.0017330 | 0.0022143 | 0.0019370 | 0.0029915 | 0.0030415 | 0.0033727 | 0.0004616 | 0.0004042 | 0.0169971 | 0.0004952 | 0.0011406 | 0.0051443 | 0.0051605 | 0.0000838 | 0.0019276 | 0.0001905 | 0.0015528 | 0.0016538 | 0.0027486 | 0.0005216 | 0.0002129 | 0.0011406 | 0.0002030 | 0.0039634 | 0.0031573 | 0.0153441 | 0.0000363 | 0.0002608 | 0.0089995 | 0.0109279 | 0.0104400 | 0.0002120 | 0.0003567 | 0.0000825 | 0.0011043 | 0.0027458 | 0.0001676 | 0.0078511 | 0.0012432 | 0.0006660 | 0.0003437 | 0.0002035 | 0.0000601 | 0.0010425 | 0.0013453 | 0.0007560 | 0.0006781 | 0.0014932 | 0.0041823 | 0.0013395 | 0.0007857 | 0.0019123 | 0.0041838 | 0.0029998 | 0.0010088 | 0.0016367 | 0.0029741 | 0.0001649 | 0.0001542 | 0.0000233 | 0.0013485 | 0.0006418 | 0.0013395 | 0.0024305 | 0.0012575 | 0.0042659 | 0.0000121 | 0.0041048 | 0.0000713 | 0.0058118 | 0.0001918 | 0.0013028 | 0.0000242 | 0.0009739 | 0.0004033 | 0.0008295 | 0.0066660 | 0.0001430 | 0.0015609 | 0.0045159 | 0.0013244 | 0.0003097 | 0.0003312 | 0.0002980 | 0.0004979 | 0.0006395 | 0.0023019 | 0.0007834 | 0.0004499 | 0.0002604 | 0.0004015 | 0.0010074 | 0.0011666 | 0.0012501 | 0.0007542 | 0.0003679 | 0.0007457 | 0.0005705 | 0.0003894 | 0.0012571 | 0.0052024 | 0.0019524 | 0.0005840 | 0.0010303 | 0.0009506 | 0.0001197 | 0.0001770 | 0.0000354 | 0.0009291 | 0.0006507 | 0.0013295 | 0.0016497 | 0.0011616 | 0.0003567 | 0.0011338 | 0.0001900 | 0.0013253 | 0.0005347 | 0.0000238 | 0.0008627 | 0.0002026 | 0.0006893 | 0.0004602 | 0.0020914 | 0.0002590 | 0.0000834 | 0.0000592 | 0.0003218 | 0.0015920 | 0.0013817 | 0.0001174 | 0.0003455 | 0.0011141 | 0.0001766 | 0.0000713 | 0.0004047 | 0.0090677 | 0.0004401 | 0.0001439 | 0.0004150 | 0.0006082 | 0.0003298 | 0.0000349 | 0.0012320 | 0.0001439 | 0.0013848 | 0.0004751 | 0.0014802 | 0.0001663 | 0.0001425 | 0.0004145 | 0.0000843 | 0.0001663 | 0.0000242 | 0.0001295 | 0.0005472 | 0.0000946 | 0.0003563 | 0.0016743 | 0.0005257 | 0.0004853 | 0.0004979 | 0.0010401 | 0.0002017 | 0.0004029 | 0.0001188 | 0.0014784 | 0.0002268 | 0.0003325 | 0.0004024 | 0.0005235 | 0.0002384 | 0.0029108 | 0.0000587 | 0.0002738 | 0.0006906 | 0.0008206 | 0.0002613 | 0.0001291 | 0.0002599 | 0.0009043 | 0.0001658 | 0.0000480 | 0.0001313 | 0.0002631 | 0.0005790 | 0.0018760 | 0.0015680 | 0.0011303 | 0.0000955 | 0.0013669 | 0.0001071 | 0.0016106 | 0.0008884 | 0.0002496 | 0.0003442 | 0.0001421 | 0.0007117 | 0.0025968 | 0.0011728 | 0.0001304 | 0.0002133 | 0.0001793 | 0.0008832 | 0.0011406 | 0.0003903 | 0.0000950 | 0.0000000 | 0.0001286 | 0.0000834 | 0.0003204 | 0.0009940 | 0.0006651 | 0.0017913 | 0.0001421 | 0.0001291 | 0.0000592 | 0.0004518 | 0.0002985 | 0.0003567 | 0.0002366 | 0.0000825 | 0.0015220 | 0.0010953 | 0.0003316 | 0.0016430 | 0.0002846 | 0.0006306 | 0.0003218 | 0.0000950 | 0.0001672 | 0.0022945 | 0.0001058 | 0.0000121 | 0.0002716 | 0.0004531 | 0.0002599 | 0.0009403 | 0.0004415 | 0.0001784 | 0.0000471 | 0.0001681 | 0.0015108 | 0.0002604 | 0.0004387 | 0.0007381 | 0.0005298 | 0.0004755 | 0.0007816 | 0.0007754 | 0.0003307 | 0.0001788 | 0.0011271 | 0.0004132 | 0.0000820 | 0.0001770 | 0.0008560 | 0.0027512 | 0.0005965 | 0.0003729 | 0.0008444 | 0.0012018 | 0.0002496 | 0.0003540 | 0.0000829 | 0.00e+00 | 0.0013117 | 0.0000475 | 0.0000475 | 0.0002841 | 3.49e-05 | 0.0001076 | 6.01e-05 | 0.0000717 | 0.0003917 | 0.0000354 | 0.0001179 | 0.0002599 | 0.0000834 | 0.0009344 | 0.0002348 | 0.0001434 | 0.0006893 | 0.0000601 | 0.0001430 | 0.0000471 | 0.0000116 | 0.0013521 | 0.0005758 | 7.03e-05 | 0.0000484 | 0.0004890 | 0.0014754 | 0.0003339 | 0.0003442 | 0.0002380 | 0.0001300 | 0.0006274 | 0.0001174 | 0.0000121 | 0.0000829 | 0.0002416 | 0.0000116 | 0.0001430 | 0.0001076 | 0.0000834 | 0.0000596 | 0.0001421 | 0.0000601 | 0.0001188 | 0.0001062 | 0.0002962 | 0.0000471 | 2.38e-05 | 0.0002501 | 0.00e+00 | 0.0001999 | 0.0000587 | 0.0001663 | 0.0000587 | 0.0002393 | 0.0003200 | 0.0003070 | 0.0000722 | 0.0000349 | 0.0000834 | 0.0001905 | 0.0001672 | 0.0000359 | 0.0008366 | 0.0002334 | 0.0002729 | 5.96e-05 | 0.0001169 | 3.49e-05 | 0.0010447 | 8.15e-05 | 0.0003707 | 0.0001304 | 0.0008067 | 0.0002250 | 0.0001555 | 0.00e+00 | 0.0001071 | 0.0000238 | 0.00e+00 | 0.0001658 | 1.21e-05 | 0.0000936 | 0.0003949 | 0.0003881 | 0.0001179 | 0.0001058 | 0.0001071 | 4.75e-05 | 0.0002142 | 0.0000703 | 2.38e-05 | 0.0000475 | 1.21e-05 | 0.0003577 | 0.0002819 | 6.05e-05 | 0.00e+00 | 0.0010549 | 0.0000941 | 0.0000717 | 0.0007843 | 0.0004760 | 0.0001286 | 0.0000946 | 0.0001067 | 0.0016837 | 0.0000121 | 0.0000596 | 0.0001891 | 0.0000722 | 0.0000592 | 1.16e-05 | 0.0000946 | 2.42e-05 | 3.54e-05 | 0.00e+00 | 1.21e-05 | 0.00e+00 | 0.0000233 | 0.0001770 | 4.75e-05 | 5.87e-05 | 0.0000592 | 0.0010633 | 8.20e-05 | 0.0001300 | 0.00e+00 | 0.0000121 | 4.80e-05 | 0.0000717 | 2.38e-05 | 4.75e-05 | 8.15e-05 | 8.25e-05 | 0.0000592 | 1.21e-05 | 0.00e+00 | 0.0001412 | 0.00e+00 | 0.0000000 | 0.0002873 | 0.0001309 | 0.0000950 | 0.0005207 | 2.38e-05 | 0.0000834 | 0.0000955 | 4.71e-05 | 0.0005207 | 0.0002272 | 3.63e-05 | 0.0001905 | 2.38e-05 | 0.0000233 | 0.0000596 | 3.49e-05 | 0.0001775 | 0.0001542 | 0.0000238 | 7.17e-05 | 0.00e+00 | 3.59e-05 | 0.0000354 | 0.00e+00 | 8.20e-05 | 0.0000349 | 0.0000359 | 0.0002380 | 2.33e-05 | 0.0003070 | 4.80e-05 | 1.21e-05 | 3.54e-05 | 0.0001067 | 1.21e-05 | 0.0001058 | 0.0001076 | 0.0000941 | 1.16e-05 | 0.0000359 | 3.54e-05 | 5.96e-05 | 9.55e-05 | 3.54e-05 | 0.0000601 | 2.38e-05 | 0.0000717 | 0.0001188 | 0.0002738 | 0.00e+00 | 5.96e-05 | 0.00e+00 | 0.0004639 | 2.38e-05 | 0.0000238 | 1.21e-05 | 0.0000121 | 0.0002021 | 0.0000950 | 0.00e+00 | 0.0000116 | 0.0000238 | 4.75e-05 | 2.42e-05 | 2.42e-05 | 1.16e-05 | 0.00e+00 | 0.0000475 | 0.0005105 | 0.0005132 | 0.0000121 | 0.0000825 | 0.0000466 | 0.0000475 | 0.0003195 | 0.0000717 | 2.38e-05 | 2.42e-05 | 0.0002487 | 1.21e-05 | 4.80e-05 | 4.71e-05 | 2.38e-05 | 0.0001649 | 0.0001421 | 0.0001421 | 0.00e+00 | 0.0000121 | 0.0001174 | 0.0000238 | 1.16e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001058 | 2.33e-05 | 0.00e+00 | 0.00e+00 | 0.0002250 | 7.08e-05 | 0.00e+00 | 2.38e-05 | 4.71e-05 | 0.0001887 | 3.59e-05 | 4.71e-05 | 0.00e+00 | 0.00e+00 | 0.0000592 | 0.0000959 | 0.0004015 | 1.16e-05 | 3.59e-05 | 0.0002353 | 0.0002465 | 0.0004123 | 0.0000363 | 0.00e+00 | 1.21e-05 | 2.33e-05 | 0.0002971 | 2.38e-05 | 7.17e-05 | 0.00e+00 | 1.16e-05 | 0.0000000 | 0.0001793 | 0.0001076 | 0.0002711 | 0.00e+00 | 1.21e-05 | 0.00e+00 | 0.00e+00 | 0.0001183 | 0.0001676 | 0.0002222 | 4.71e-05 | 0.0000242 | 0.00e+00 | 0.00e+00 | 3.63e-05 | 3.59e-05 | 3.59e-05 | 0.0e+00 | 0.0001067 | 0.00e+00 | 0.0001900 | 0.00e+00 | 0.0000829 | 3.49e-05 | 3.59e-05 | 4.75e-05 | 0.0000592 | 2.33e-05 | 1.16e-05 | 2.38e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 3.54e-05 | 2.33e-05 | 0.0001775 | 2.42e-05 | 0.0000349 | 3.63e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 2.42e-05 | 1.21e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 3.63e-05 | 0.0e+00 | 0.0001421 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 8.29e-05 | 5.92e-05 | 4.75e-05 | 0.00e+00 | 2.33e-05 | 1.16e-05 | 3.54e-05 | 0.0000242 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 5.96e-05 | 0.00e+00 | 0.0e+00 | 1.16e-05 | 0.0e+00 | 3.54e-05 | 2.42e-05 | 1.16e-05 | 1.16e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 3.54e-05 | 0.0000713 | 0.0000703 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001425 | 2.38e-05 | 0.00e+00 | 4.75e-05 | 3.54e-05 | 0.00e+00 | 1.16e-05 | 0.0e+00 | 1.16e-05 | 0.0000480 | 0.0002272 | 1.21e-05 | 0.0002026 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.16e-05 | 0.00e+00 | 3.54e-05 | 0.0e+00 | 0.0e+00 | 2.38e-05 | 0.0000480 | 0.0000829 | 0.0e+00 | 0.0000703 | 0.00e+00 | 0.0000354 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.42e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 2.38e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0005571 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0001183 | 0.0001080 | 0.0004419 | 0.0000233 | 0.0001062 | 0.0001443 | 0.00e+00 | 0.0001909 | 1.16e-05 | 0.00e+00 | 2.42e-05 | 1.16e-05 | 1.21e-05 | 0.0002832 | 0.0e+00 | 0.0e+00 | 0.0000116 | 0.00e+00 | 0.00e+00 | 2.38e-05 | 3.54e-05 | 0.00e+00 | 0.0e+00 | 8.34e-05 | 1.16e-05 | 1.16e-05 | 0.0e+00 | 0.00e+00 | 7.17e-05 | 1.21e-05 | 1.16e-05 | 0.00e+00 | 1.16e-05 | 2.33e-05 | 1.21e-05 | 7.13e-05 | 1.16e-05 | 0.00e+00 | 8.29e-05 | 4.80e-05 | 0.00e+00 | 1.16e-05 | 1.16e-05 | 0.00e+00 | 0.0e+00 | 2.42e-05 | 0.00e+00 | 2.38e-05 | 0.00e+00 | 0.00e+00 | 1.16e-05 | 1.16e-05 | 1.21e-05 | 0.00e+00 | 3.54e-05 | 0.00e+00 | 0.0000475 | 0.00e+00 | 1.21e-05 | 1.21e-05 | 0.0e+00 | 4.66e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 1.16e-05 | 3.49e-05 | 1.16e-05 | 0.00e+00 | 1.16e-05 | 1.21e-05 | 1.21e-05 | 2.38e-05 | 0.00e+00 | 4.75e-05 | 2.33e-05 | 0.00e+00 | 0.00e+00 | 2.33e-05 | 0.0e+00 | 1.16e-05 | 3.54e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 1.21e-05 | 1.16e-05 | 0.0e+00 | 7.08e-05 | 1.16e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 4.75e-05 | 0.0e+00 | 0.0e+00 | 1.16e-05 | 0.00e+00 | 1.21e-05 | 0.00e+00 | 0.00e+00 | 5.96e-05 | 2.33e-05 | 4.71e-05 | 0.00e+00 | 1.21e-05 | 1.21e-05 | 0.00e+00 | 0.00e+00 | 1.16e-05 | 0.00e+00 | 0.00e+00 | 6.99e-05 | 1.16e-05 | 0.00e+00 | 1.16e-05 | 0.0e+00 | 0.00e+00 | 1.16e-05 | 2.38e-05 | 0.00e+00 | 1.16e-05 | 1.21e-05 | 0.00e+00 | 2.42e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.63e-05 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 2.38e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 1.16e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 1.16e-05 | 0.00e+00 | 2.33e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 1.21e-05 | 0.0e+00 | 0.0e+00 | 1.21e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 2.38e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 2.33e-05 | 1.16e-05 | 1.16e-05 | 1.16e-05 | 1.16e-05 | 1.16e-05 | 1.16e-05 | 1.16e-05 | 9.68e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 1.21e-05 | 1.21e-05 | 1.21e-05 | 1.21e-05 | 1.21e-05 | 1.21e-05 | 1.21e-05 | 1.21e-05 | 1.21e-05 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 9 | 0.0433537 | 0.0055010 | 0.0435934 | 0.0046210 | 0.0161780 | 0.0060779 | 0.0027272 | 0.0300306 | 0.0403382 | 0.0372629 | 0.0003862 | 0.0316387 | 0.0199329 | 0.0132014 | 0.0131210 | 0.0004696 | 0.0012346 | 0.0114280 | 0.0001060 | 0.0235400 | 0.0087325 | 0.0054049 | 0.0010563 | 0.0007397 | 0.0264693 | 0.0044543 | 0.0043029 | 0.0046503 | 0.0014236 | 0.0053030 | 0.0202058 | 0.0018229 | 0.0035409 | 0.0004939 | 0.0072622 | 0.0097314 | 0.0062206 | 0.0052002 | 0.0015973 | 0.0109448 | 0.0006443 | 0.0014596 | 0.0017466 | 0.0028318 | 0.0038869 | 0.0050194 | 0.0031610 | 0.0005296 | 0.0128932 | 0.0016743 | 0.0080610 | 0.0020355 | 0.0054769 | 0.0016458 | 0.0019789 | 0.0056403 | 0.0077169 | 0.0020322 | 0.0054785 | 0.0029967 | 0.0020836 | 0.0110629 | 0.0040454 | 0.0008718 | 0.0023241 | 0.0001679 | 0.0003173 | 0.0004974 | 0.0044925 | 0.0005893 | 0.0033874 | 0.0021634 | 0.0005559 | 0.0168443 | 0.0009016 | 0.0020089 | 0.0013409 | 0.0022365 | 0.0028782 | 0.0024102 | 0.0048745 | 0.0040457 | 0.0042144 | 0.0005947 | 0.0005536 | 0.0131518 | 0.0004417 | 0.0012986 | 0.0067455 | 0.0059879 | 0.0001615 | 0.0022661 | 0.0002927 | 0.0018354 | 0.0020874 | 0.0028660 | 0.0006812 | 0.0002183 | 0.0010787 | 0.0001256 | 0.0076439 | 0.0030262 | 0.0130695 | 0.0001608 | 0.0004448 | 0.0120995 | 0.0125174 | 0.0064595 | 0.0000799 | 0.0006749 | 0.0001550 | 0.0014777 | 0.0022267 | 0.0001477 | 0.0089477 | 0.0016116 | 0.0009221 | 0.0003783 | 0.0001994 | 0.0001158 | 0.0007991 | 0.0008051 | 0.0009853 | 0.0006416 | 0.0014628 | 0.0061065 | 0.0019452 | 0.0008138 | 0.0016003 | 0.0049353 | 0.0020778 | 0.0007613 | 0.0017265 | 0.0041463 | 0.0001314 | 0.0000993 | 0.0000092 | 0.0015527 | 0.0006663 | 0.0020359 | 0.0030398 | 0.0015910 | 0.0055570 | 0.0000480 | 0.0036506 | 0.0001118 | 0.0052420 | 0.0002695 | 0.0015324 | 0.0000164 | 0.0015766 | 0.0005353 | 0.0006755 | 0.0098116 | 0.0002802 | 0.0016939 | 0.0050539 | 0.0010780 | 0.0003719 | 0.0005350 | 0.0005176 | 0.0006908 | 0.0008558 | 0.0022223 | 0.0008218 | 0.0006256 | 0.0006367 | 0.0005078 | 0.0008389 | 0.0011272 | 0.0004264 | 0.0004952 | 0.0004782 | 0.0008657 | 0.0005854 | 0.0003908 | 0.0013790 | 0.0050191 | 0.0027325 | 0.0002878 | 0.0009685 | 0.0011523 | 0.0001332 | 0.0000944 | 0.0000164 | 0.0007968 | 0.0004462 | 0.0006247 | 0.0017470 | 0.0011793 | 0.0003956 | 0.0015308 | 0.0001571 | 0.0007177 | 0.0005286 | 0.0000635 | 0.0011083 | 0.0002489 | 0.0005607 | 0.0004493 | 0.0018644 | 0.0001575 | 0.0001425 | 0.0001078 | 0.0004031 | 0.0010152 | 0.0013767 | 0.0000945 | 0.0003743 | 0.0013039 | 0.0001591 | 0.0000738 | 0.0003347 | 0.0064099 | 0.0004251 | 0.0000918 | 0.0005616 | 0.0006391 | 0.0001971 | 0.0000482 | 0.0016889 | 0.0000503 | 0.0017976 | 0.0007366 | 0.0018545 | 0.0002238 | 0.0001142 | 0.0007355 | 0.0001355 | 0.0002235 | 0.0000502 | 0.0000395 | 0.0004688 | 0.0001194 | 0.0004480 | 0.0010824 | 0.0006195 | 0.0003543 | 0.0004354 | 0.0017562 | 0.0001817 | 0.0001204 | 0.0001769 | 0.0020892 | 0.0003659 | 0.0005145 | 0.0004630 | 0.0003215 | 0.0002936 | 0.0049347 | 0.0000559 | 0.0003522 | 0.0006670 | 0.0007694 | 0.0001795 | 0.0001257 | 0.0001944 | 0.0002896 | 0.0001697 | 0.0001806 | 0.0003022 | 0.0002640 | 0.0010160 | 0.0025900 | 0.0022976 | 0.0012713 | 0.0002760 | 0.0015392 | 0.0000768 | 0.0016377 | 0.0004353 | 0.0002485 | 0.0003430 | 0.0000712 | 0.0007914 | 0.0028674 | 0.0015043 | 0.0001656 | 0.0002144 | 0.0001519 | 0.0007499 | 0.0009324 | 0.0004748 | 0.0001966 | 0.0000082 | 0.0001424 | 0.0000803 | 0.0002541 | 0.0012197 | 0.0007473 | 0.0020249 | 0.0000948 | 0.0001560 | 0.0000861 | 0.0006024 | 0.0002874 | 0.0004163 | 0.0003404 | 0.0000691 | 0.0019419 | 0.0009469 | 0.0003617 | 0.0013806 | 0.0003126 | 0.0009114 | 0.0003721 | 0.0000454 | 0.0002987 | 0.0030588 | 0.0000962 | 0.0000544 | 0.0001810 | 0.0001273 | 0.0002452 | 0.0013293 | 0.0003601 | 0.0001140 | 0.0000455 | 0.0001789 | 0.0022708 | 0.0002903 | 0.0004288 | 0.0004417 | 0.0003044 | 0.0004101 | 0.0011817 | 0.0007437 | 0.0003606 | 0.0001914 | 0.0016157 | 0.0004484 | 0.0000208 | 0.0003046 | 0.0009902 | 0.0029937 | 0.0004357 | 0.0002828 | 0.0006709 | 0.0011332 | 0.0003202 | 0.0004605 | 0.0000593 | 1.64e-05 | 0.0016481 | 0.0001043 | 0.0001160 | 0.0003396 | 3.72e-05 | 0.0001755 | 1.05e-05 | 0.0000405 | 0.0003038 | 0.0000174 | 0.0000543 | 0.0002160 | 0.0000740 | 0.0013295 | 0.0003141 | 0.0001459 | 0.0009005 | 0.0001074 | 0.0001513 | 0.0000583 | 0.0000000 | 0.0028709 | 0.0002474 | 1.06e-05 | 0.0000465 | 0.0006305 | 0.0020653 | 0.0002050 | 0.0004456 | 0.0001347 | 0.0003416 | 0.0008043 | 0.0001914 | 0.0000000 | 0.0001506 | 0.0001899 | 0.0000803 | 0.0001511 | 0.0001173 | 0.0001240 | 0.0001986 | 0.0002727 | 0.0000628 | 0.0001093 | 0.0002423 | 0.0004423 | 0.0000323 | 4.28e-05 | 0.0001852 | 4.15e-05 | 0.0000126 | 0.0001188 | 0.0001265 | 0.0000593 | 0.0002104 | 0.0002531 | 0.0004037 | 0.0000405 | 0.0001890 | 0.0001376 | 0.0002652 | 0.0004380 | 0.0000927 | 0.0008383 | 0.0000126 | 0.0002449 | 9.20e-06 | 0.0000713 | 3.37e-05 | 0.0032662 | 6.19e-05 | 0.0001468 | 0.0000324 | 0.0005874 | 0.0004153 | 0.0001014 | 3.16e-05 | 0.0003195 | 0.0000106 | 1.05e-05 | 0.0001531 | 0.00e+00 | 0.0000584 | 0.0001456 | 0.0001808 | 0.0000797 | 0.0000356 | 0.0000281 | 8.20e-06 | 0.0001047 | 0.0001211 | 8.80e-05 | 0.0000408 | 2.08e-05 | 0.0005212 | 0.0000562 | 9.08e-05 | 1.05e-05 | 0.0018916 | 0.0001533 | 0.0000771 | 0.0005534 | 0.0005307 | 0.0000584 | 0.0002302 | 0.0001099 | 0.0021843 | 0.0001753 | 0.0001102 | 0.0001463 | 0.0000541 | 0.0000490 | 0.00e+00 | 0.0000826 | 4.40e-05 | 7.52e-05 | 0.00e+00 | 1.74e-05 | 1.74e-05 | 0.0000561 | 0.0000861 | 1.06e-05 | 7.67e-05 | 0.0001306 | 0.0001336 | 0.00e+00 | 0.0000510 | 0.00e+00 | 0.0000896 | 4.15e-05 | 0.0000208 | 1.98e-05 | 1.87e-05 | 1.05e-05 | 1.97e-05 | 0.0001003 | 9.20e-06 | 9.20e-06 | 0.0001989 | 2.18e-05 | 0.0000164 | 0.0002525 | 0.0001880 | 0.0000884 | 0.0008806 | 3.02e-05 | 0.0000501 | 0.0001424 | 9.22e-05 | 0.0006436 | 0.0001176 | 6.52e-05 | 0.0003082 | 2.10e-05 | 0.0000426 | 0.0000890 | 2.79e-05 | 0.0002600 | 0.0003054 | 0.0000082 | 2.67e-05 | 1.06e-05 | 2.93e-05 | 0.0000208 | 0.00e+00 | 5.09e-05 | 0.0000499 | 0.0000357 | 0.0002003 | 0.00e+00 | 0.0000408 | 0.00e+00 | 8.20e-06 | 5.69e-05 | 0.0000317 | 2.30e-05 | 0.0001011 | 0.0000105 | 0.0000251 | 8.20e-06 | 0.0000396 | 0.00e+00 | 1.74e-05 | 1.87e-05 | 9.20e-06 | 0.0000187 | 0.00e+00 | 0.0000854 | 0.0000848 | 0.0005434 | 1.87e-05 | 8.17e-05 | 7.32e-05 | 0.0005187 | 4.82e-05 | 0.0000709 | 0.00e+00 | 0.0000654 | 0.0002635 | 0.0001544 | 0.00e+00 | 0.0000082 | 0.0000126 | 2.10e-05 | 3.24e-05 | 0.00e+00 | 1.05e-05 | 2.10e-05 | 0.0001533 | 0.0004820 | 0.0006148 | 0.0000610 | 0.0000198 | 0.0000198 | 0.0001506 | 0.0002453 | 0.0000697 | 2.32e-05 | 2.51e-05 | 0.0001707 | 2.30e-05 | 1.87e-05 | 4.55e-05 | 0.00e+00 | 0.0000706 | 0.0000991 | 0.0000780 | 0.00e+00 | 0.0000445 | 0.0000876 | 0.0000082 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001013 | 4.66e-05 | 0.00e+00 | 0.00e+00 | 0.0002059 | 8.20e-06 | 0.00e+00 | 8.20e-06 | 2.71e-05 | 0.0000399 | 0.00e+00 | 1.06e-05 | 0.00e+00 | 0.00e+00 | 0.0001335 | 0.0000966 | 0.0004702 | 2.51e-05 | 0.00e+00 | 0.0002372 | 0.0003590 | 0.0004277 | 0.0001114 | 0.00e+00 | 0.00e+00 | 1.26e-05 | 0.0005277 | 1.26e-05 | 5.53e-05 | 0.00e+00 | 8.20e-06 | 0.0000126 | 0.0000833 | 0.0001722 | 0.0002352 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001209 | 0.0002460 | 0.0002393 | 0.00e+00 | 0.0000082 | 0.00e+00 | 0.00e+00 | 2.90e-05 | 1.87e-05 | 1.88e-05 | 0.0e+00 | 0.0001142 | 0.00e+00 | 0.0001052 | 1.06e-05 | 0.0001485 | 0.00e+00 | 8.10e-05 | 4.92e-05 | 0.0000666 | 4.01e-05 | 0.00e+00 | 1.64e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 4.18e-05 | 1.05e-05 | 0.0001562 | 2.32e-05 | 0.0000126 | 2.12e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 9.51e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0001353 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 2.30e-05 | 2.30e-05 | 3.69e-05 | 1.05e-05 | 0.00e+00 | 8.20e-06 | 6.82e-05 | 0.0000174 | 0.0e+00 | 4.19e-05 | 0.0e+00 | 1.05e-05 | 5.44e-05 | 1.74e-05 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 9.47e-05 | 0.00e+00 | 9.20e-06 | 1.88e-05 | 0.00e+00 | 8.2e-06 | 0.0e+00 | 1.64e-05 | 0.0001322 | 0.0000487 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0001013 | 1.04e-04 | 2.32e-05 | 1.26e-05 | 5.32e-05 | 1.05e-05 | 4.38e-05 | 9.2e-06 | 0.00e+00 | 0.0000416 | 0.0001438 | 1.26e-05 | 0.0002061 | 8.20e-06 | 0.0e+00 | 1.74e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 2.32e-05 | 0.0000398 | 0.0000888 | 0.0e+00 | 0.0001951 | 0.00e+00 | 0.0001375 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 2.30e-05 | 0.00e+00 | 2.10e-05 | 1.05e-05 | 3.57e-05 | 5.31e-05 | 0.0e+00 | 1.05e-05 | 1.06e-05 | 1.26e-05 | 0.0005891 | 2.81e-05 | 0.0e+00 | 0.0e+00 | 0.0000957 | 0.0002183 | 0.0005807 | 0.0000468 | 0.0000683 | 0.0000557 | 2.57e-05 | 0.0001464 | 0.00e+00 | 0.00e+00 | 1.05e-05 | 1.87e-05 | 0.00e+00 | 0.0002228 | 0.0e+00 | 0.0e+00 | 0.0000415 | 1.64e-05 | 0.00e+00 | 0.00e+00 | 2.32e-05 | 1.26e-05 | 0.0e+00 | 9.27e-05 | 3.03e-05 | 5.13e-05 | 0.0e+00 | 0.00e+00 | 1.64e-05 | 9.20e-06 | 1.05e-05 | 0.00e+00 | 5.83e-05 | 0.00e+00 | 3.85e-05 | 2.18e-05 | 0.00e+00 | 1.74e-05 | 2.79e-05 | 8.20e-06 | 0.00e+00 | 0.00e+00 | 1.05e-05 | 1.97e-05 | 0.0e+00 | 3.23e-05 | 1.97e-05 | 6.27e-05 | 0.00e+00 | 0.00e+00 | 3.16e-05 | 0.00e+00 | 0.00e+00 | 9.20e-06 | 3.03e-05 | 0.00e+00 | 0.0000318 | 3.97e-05 | 3.24e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 8.20e-06 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 8.20e-06 | 1.05e-05 | 1.06e-05 | 1.98e-05 | 0.00e+00 | 0.00e+00 | 2.08e-05 | 0.00e+00 | 0.00e+00 | 1.06e-05 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 8.20e-06 | 0.0e+00 | 9.20e-06 | 0.00e+00 | 2.08e-05 | 2.51e-05 | 1.26e-05 | 4.16e-05 | 0.0e+00 | 8.2e-06 | 0.00e+00 | 0.00e+00 | 2.10e-05 | 3.35e-05 | 1.05e-05 | 1.87e-05 | 1.87e-05 | 3.96e-05 | 1.05e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.24e-05 | 2.08e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.83e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 2.51e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 8.20e-06 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 9.20e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 1.06e-05 | 0.0e+00 | 0.00e+00 | 1.64e-05 | 0.0e+00 | 1.06e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 8.20e-06 | 1.06e-05 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 8.20e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 2.32e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 9.2e-06 | 0.00e+00 | 0.0e+00 | 8.2e-06 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 2.51e-05 | 0.00e+00 | 0.00e+00 | 1.26e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 |
| 10 | 0.0989819 | 0.0488437 | 0.0438533 | 0.0279644 | 0.0545479 | 0.0295244 | 0.0204591 | 0.0323510 | 0.0220163 | 0.0307473 | 0.0121831 | 0.0270013 | 0.0250711 | 0.0174782 | 0.0168188 | 0.0115409 | 0.0118140 | 0.0154538 | 0.0059699 | 0.0163738 | 0.0125670 | 0.0070667 | 0.0076563 | 0.0042487 | 0.0103787 | 0.0053594 | 0.0091312 | 0.0047789 | 0.0044562 | 0.0063880 | 0.0066837 | 0.0039059 | 0.0056521 | 0.0029693 | 0.0055016 | 0.0076383 | 0.0072082 | 0.0051919 | 0.0035793 | 0.0046736 | 0.0027249 | 0.0048379 | 0.0026202 | 0.0036335 | 0.0027661 | 0.0052723 | 0.0028104 | 0.0033136 | 0.0030799 | 0.0026400 | 0.0040203 | 0.0025244 | 0.0039256 | 0.0025745 | 0.0026026 | 0.0028075 | 0.0039232 | 0.0045304 | 0.0049228 | 0.0031083 | 0.0025503 | 0.0024622 | 0.0028420 | 0.0019347 | 0.0027498 | 0.0020485 | 0.0017335 | 0.0016775 | 0.0046619 | 0.0014559 | 0.0027847 | 0.0019096 | 0.0017629 | 0.0028857 | 0.0020402 | 0.0023022 | 0.0019490 | 0.0030005 | 0.0018792 | 0.0019424 | 0.0027166 | 0.0017558 | 0.0018680 | 0.0016565 | 0.0015128 | 0.0037927 | 0.0022545 | 0.0018931 | 0.0025858 | 0.0022780 | 0.0011287 | 0.0015987 | 0.0012399 | 0.0021003 | 0.0021431 | 0.0015667 | 0.0009851 | 0.0011926 | 0.0013191 | 0.0011351 | 0.0010974 | 0.0019456 | 0.0023202 | 0.0011856 | 0.0012702 | 0.0014797 | 0.0015736 | 0.0023469 | 0.0007403 | 0.0010997 | 0.0007357 | 0.0013377 | 0.0013428 | 0.0011981 | 0.0013149 | 0.0006742 | 0.0010728 | 0.0008185 | 0.0007721 | 0.0007461 | 0.0010886 | 0.0009699 | 0.0009378 | 0.0007013 | 0.0011320 | 0.0010607 | 0.0008955 | 0.0007732 | 0.0014252 | 0.0018854 | 0.0016418 | 0.0009282 | 0.0011922 | 0.0011948 | 0.0006586 | 0.0008350 | 0.0005317 | 0.0006816 | 0.0009196 | 0.0009803 | 0.0007724 | 0.0010185 | 0.0013218 | 0.0004156 | 0.0011032 | 0.0005670 | 0.0009166 | 0.0006241 | 0.0010130 | 0.0004345 | 0.0010768 | 0.0007378 | 0.0007332 | 0.0009606 | 0.0003969 | 0.0004682 | 0.0010452 | 0.0011201 | 0.0011344 | 0.0005279 | 0.0005554 | 0.0008194 | 0.0005483 | 0.0013546 | 0.0005758 | 0.0005901 | 0.0008898 | 0.0005702 | 0.0005560 | 0.0006630 | 0.0004454 | 0.0006345 | 0.0005845 | 0.0004810 | 0.0005336 | 0.0005871 | 0.0008047 | 0.0008226 | 0.0008761 | 0.0005219 | 0.0005361 | 0.0007099 | 0.0003639 | 0.0004923 | 0.0003282 | 0.0004852 | 0.0005876 | 0.0006090 | 0.0007304 | 0.0004699 | 0.0005270 | 0.0006162 | 0.0003369 | 0.0006080 | 0.0005795 | 0.0003262 | 0.0005403 | 0.0007115 | 0.0005321 | 0.0005107 | 0.0003965 | 0.0004598 | 0.0003385 | 0.0005240 | 0.0004195 | 0.0005158 | 0.0005158 | 0.0004078 | 0.0005398 | 0.0004685 | 0.0004353 | 0.0003176 | 0.0005567 | 0.0007993 | 0.0002926 | 0.0002962 | 0.0003247 | 0.0005245 | 0.0002738 | 0.0002310 | 0.0006841 | 0.0002764 | 0.0003584 | 0.0005903 | 0.0005547 | 0.0004288 | 0.0003646 | 0.0003681 | 0.0003217 | 0.0003360 | 0.0002254 | 0.0002351 | 0.0002922 | 0.0002137 | 0.0003100 | 0.0004278 | 0.0003029 | 0.0003386 | 0.0003457 | 0.0004742 | 0.0003065 | 0.0002377 | 0.0002484 | 0.0003411 | 0.0002402 | 0.0002331 | 0.0002688 | 0.0003366 | 0.0005471 | 0.0004936 | 0.0003865 | 0.0003508 | 0.0003927 | 0.0006032 | 0.0003070 | 0.0003106 | 0.0003096 | 0.0003203 | 0.0001954 | 0.0002097 | 0.0002097 | 0.0004095 | 0.0003988 | 0.0003310 | 0.0004559 | 0.0003871 | 0.0002265 | 0.0002658 | 0.0002622 | 0.0003157 | 0.0003504 | 0.0002469 | 0.0002220 | 0.0003005 | 0.0002612 | 0.0003897 | 0.0003468 | 0.0001781 | 0.0002317 | 0.0001460 | 0.0001853 | 0.0002852 | 0.0002138 | 0.0002424 | 0.0001532 | 0.0002459 | 0.0001807 | 0.0003520 | 0.0001878 | 0.0003199 | 0.0003805 | 0.0002093 | 0.0002200 | 0.0002806 | 0.0002735 | 0.0002057 | 0.0002342 | 0.0001664 | 0.0001084 | 0.0003117 | 0.0003296 | 0.0002903 | 0.0002439 | 0.0004437 | 0.0004330 | 0.0001405 | 0.0001405 | 0.0003082 | 0.0001726 | 0.0003214 | 0.0002073 | 0.0002679 | 0.0002037 | 0.0002108 | 0.0002358 | 0.0002394 | 0.0001823 | 0.0001466 | 0.0001644 | 0.0002501 | 0.0003143 | 0.0002501 | 0.0002536 | 0.0002429 | 0.0002322 | 0.0002394 | 0.0002429 | 0.0001644 | 0.0002073 | 0.0001894 | 0.0002705 | 0.0001099 | 0.0001920 | 0.0001599 | 0.0003062 | 0.0001991 | 0.0001456 | 0.0002669 | 0.0002954 | 0.0001492 | 0.0002277 | 0.0001171 | 8.14e-05 | 0.0002205 | 0.0001063 | 0.0001848 | 0.0001848 | 9.46e-05 | 0.0001731 | 9.46e-05 | 0.0001053 | 0.0001410 | 0.0001125 | 0.0001018 | 0.0001767 | 0.0001053 | 0.0001125 | 0.0001874 | 0.0001696 | 0.0002873 | 0.0001482 | 0.0002623 | 0.0000911 | 0.0000946 | 0.0001945 | 0.0001258 | 9.01e-05 | 0.0001365 | 0.0001757 | 0.0001721 | 0.0001258 | 0.0001186 | 0.0001436 | 0.0001436 | 0.0001828 | 0.0001436 | 0.0001329 | 0.0001365 | 0.0001900 | 0.0001008 | 0.0001248 | 0.0000998 | 0.0001355 | 0.0001176 | 0.0001212 | 0.0000962 | 0.0001140 | 0.0000998 | 0.0001925 | 0.0000748 | 6.77e-05 | 0.0001105 | 8.91e-05 | 0.0000819 | 0.0000677 | 0.0001997 | 0.0001069 | 0.0000998 | 0.0001176 | 0.0001319 | 0.0001105 | 0.0000748 | 0.0000748 | 0.0000998 | 0.0001212 | 0.0000784 | 0.0001533 | 0.0000738 | 0.0001237 | 7.74e-05 | 0.0000881 | 7.02e-05 | 0.0001523 | 7.74e-05 | 0.0001023 | 0.0000845 | 0.0001059 | 0.0001130 | 0.0001130 | 4.88e-05 | 0.0001273 | 0.0001237 | 8.09e-05 | 0.0000692 | 5.14e-05 | 0.0000835 | 0.0001227 | 0.0001085 | 0.0000728 | 0.0000514 | 0.0000835 | 4.78e-05 | 0.0000728 | 0.0002619 | 5.14e-05 | 0.0000871 | 7.28e-05 | 0.0001263 | 0.0001549 | 6.92e-05 | 5.50e-05 | 0.0001335 | 0.0000764 | 0.0000764 | 0.0001691 | 0.0001299 | 0.0000692 | 0.0000764 | 0.0001156 | 0.0002262 | 0.0001227 | 0.0000692 | 0.0000514 | 0.0000647 | 0.0000504 | 5.04e-05 | 0.0000682 | 6.11e-05 | 5.75e-05 | 7.18e-05 | 9.32e-05 | 3.97e-05 | 0.0000718 | 0.0000575 | 3.97e-05 | 5.40e-05 | 0.0000861 | 0.0000540 | 4.33e-05 | 0.0000468 | 3.61e-05 | 0.0000397 | 5.40e-05 | 0.0000754 | 3.61e-05 | 5.04e-05 | 3.97e-05 | 4.33e-05 | 0.0000682 | 3.97e-05 | 4.33e-05 | 0.0001824 | 3.25e-05 | 0.0000504 | 0.0000861 | 0.0000718 | 0.0000647 | 0.0000968 | 3.61e-05 | 0.0000825 | 0.0000789 | 7.54e-05 | 0.0001574 | 0.0000754 | 6.11e-05 | 0.0000611 | 4.68e-05 | 0.0000896 | 0.0001325 | 5.75e-05 | 0.0001110 | 0.0000896 | 0.0001182 | 4.58e-05 | 3.51e-05 | 3.87e-05 | 0.0000423 | 2.44e-05 | 7.44e-05 | 0.0000530 | 0.0000601 | 0.0000494 | 2.44e-05 | 0.0000601 | 7.44e-05 | 3.15e-05 | 3.51e-05 | 0.0000530 | 5.30e-05 | 0.0000387 | 0.0000423 | 0.0000530 | 2.80e-05 | 0.0000423 | 4.58e-05 | 5.30e-05 | 3.87e-05 | 2.44e-05 | 0.0000351 | 3.51e-05 | 0.0000458 | 0.0000315 | 0.0000494 | 4.94e-05 | 3.87e-05 | 3.15e-05 | 0.0001422 | 3.87e-05 | 0.0000530 | 5.30e-05 | 0.0000494 | 0.0000851 | 0.0000458 | 3.15e-05 | 0.0000351 | 0.0000244 | 8.86e-05 | 5.65e-05 | 3.51e-05 | 4.23e-05 | 2.80e-05 | 0.0000565 | 0.0000993 | 0.0001100 | 0.0000637 | 0.0000494 | 0.0000458 | 0.0001172 | 0.0000744 | 0.0000565 | 2.70e-05 | 3.05e-05 | 0.0000734 | 1.98e-05 | 3.41e-05 | 1.98e-05 | 2.34e-05 | 0.0000734 | 0.0000520 | 0.0000484 | 1.98e-05 | 0.0000270 | 0.0000341 | 0.0000448 | 1.63e-05 | 1.63e-05 | 1.98e-05 | 1.63e-05 | 0.0000484 | 4.12e-05 | 1.63e-05 | 1.98e-05 | 0.0000341 | 1.63e-05 | 1.98e-05 | 4.48e-05 | 3.77e-05 | 0.0000163 | 2.34e-05 | 2.70e-05 | 1.63e-05 | 1.98e-05 | 0.0000448 | 0.0000412 | 0.0000948 | 1.98e-05 | 1.63e-05 | 0.0000876 | 0.0000377 | 0.0000912 | 0.0000305 | 2.70e-05 | 1.98e-05 | 2.34e-05 | 0.0000983 | 5.20e-05 | 7.69e-05 | 1.63e-05 | 2.34e-05 | 0.0000163 | 0.0000555 | 0.0000412 | 0.0000520 | 1.98e-05 | 1.63e-05 | 2.34e-05 | 1.98e-05 | 0.0000270 | 0.0000234 | 0.0000520 | 1.88e-05 | 0.0000153 | 1.53e-05 | 1.17e-05 | 5.45e-05 | 2.60e-05 | 2.24e-05 | 8.1e-06 | 0.0000367 | 1.17e-05 | 0.0000474 | 1.17e-05 | 0.0000367 | 2.95e-05 | 1.88e-05 | 1.88e-05 | 0.0000153 | 1.88e-05 | 8.10e-06 | 2.24e-05 | 8.10e-06 | 8.10e-06 | 8.1e-06 | 1.53e-05 | 1.88e-05 | 0.0000617 | 8.10e-06 | 0.0000081 | 1.53e-05 | 8.1e-06 | 8.1e-06 | 8.1e-06 | 1.17e-05 | 8.10e-06 | 8.10e-06 | 8.1e-06 | 8.1e-06 | 1.17e-05 | 8.1e-06 | 0.0000402 | 8.10e-06 | 8.1e-06 | 1.53e-05 | 1.53e-05 | 1.53e-05 | 1.17e-05 | 8.10e-06 | 8.10e-06 | 1.17e-05 | 1.53e-05 | 0.0000295 | 8.1e-06 | 1.17e-05 | 8.1e-06 | 1.17e-05 | 1.53e-05 | 1.53e-05 | 8.1e-06 | 1.53e-05 | 8.1e-06 | 2.60e-05 | 8.10e-06 | 2.60e-05 | 1.53e-05 | 8.10e-06 | 8.1e-06 | 8.1e-06 | 2.60e-05 | 0.0000402 | 0.0000438 | 1.17e-05 | 8.1e-06 | 1.17e-05 | 1.17e-05 | 1.53e-05 | 0.0000331 | 2.95e-05 | 1.17e-05 | 1.17e-05 | 2.60e-05 | 8.10e-06 | 2.24e-05 | 8.1e-06 | 1.53e-05 | 0.0000474 | 0.0000617 | 2.60e-05 | 0.0000224 | 8.10e-06 | 8.1e-06 | 3.67e-05 | 8.10e-06 | 1.17e-05 | 1.88e-05 | 8.1e-06 | 8.1e-06 | 1.17e-05 | 0.0000117 | 0.0000117 | 8.1e-06 | 0.0000688 | 1.88e-05 | 0.0000831 | 1.53e-05 | 2.60e-05 | 8.1e-06 | 1.17e-05 | 8.10e-06 | 1.17e-05 | 8.10e-06 | 2.60e-05 | 8.10e-06 | 2.95e-05 | 3.31e-05 | 8.1e-06 | 1.53e-05 | 8.10e-06 | 8.10e-06 | 0.0000617 | 1.53e-05 | 8.1e-06 | 8.1e-06 | 0.0000402 | 0.0000474 | 0.0001142 | 0.0000071 | 0.0000143 | 0.0000535 | 7.10e-06 | 0.0000178 | 0.00e+00 | 1.43e-05 | 1.07e-05 | 0.00e+00 | 0.00e+00 | 0.0000285 | 3.6e-06 | 3.6e-06 | 0.0000036 | 3.60e-06 | 1.07e-05 | 0.00e+00 | 3.60e-06 | 0.00e+00 | 7.1e-06 | 1.07e-05 | 3.60e-06 | 1.07e-05 | 0.0e+00 | 3.60e-06 | 7.10e-06 | 3.60e-06 | 3.21e-05 | 7.10e-06 | 1.07e-05 | 2.50e-05 | 2.50e-05 | 3.21e-05 | 0.00e+00 | 3.60e-06 | 7.10e-06 | 7.10e-06 | 0.00e+00 | 7.10e-06 | 3.60e-06 | 3.60e-06 | 0.0e+00 | 2.14e-05 | 1.43e-05 | 0.00e+00 | 3.60e-06 | 3.21e-05 | 1.43e-05 | 0.00e+00 | 3.60e-06 | 2.14e-05 | 1.43e-05 | 0.00e+00 | 0.0000036 | 3.60e-06 | 1.07e-05 | 1.43e-05 | 0.0e+00 | 1.43e-05 | 0.00e+00 | 1.07e-05 | 0.00e+00 | 0.00e+00 | 3.6e-06 | 0.00e+00 | 1.07e-05 | 7.10e-06 | 0.00e+00 | 7.10e-06 | 3.60e-06 | 0.00e+00 | 7.10e-06 | 7.10e-06 | 3.60e-06 | 7.10e-06 | 1.43e-05 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 3.60e-06 | 3.60e-06 | 3.60e-06 | 3.60e-06 | 3.6e-06 | 0.0e+00 | 3.57e-05 | 0.00e+00 | 0.0e+00 | 3.60e-06 | 7.10e-06 | 0.00e+00 | 3.60e-06 | 0.00e+00 | 3.60e-06 | 3.6e-06 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 1.07e-05 | 3.60e-06 | 0.00e+00 | 3.21e-05 | 0.00e+00 | 2.50e-05 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.60e-06 | 0.00e+00 | 0.00e+00 | 3.60e-06 | 0.00e+00 | 7.10e-06 | 3.60e-06 | 0.0e+00 | 1.07e-05 | 0.00e+00 | 0.00e+00 | 1.43e-05 | 7.10e-06 | 7.10e-06 | 0.00e+00 | 7.10e-06 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 3.60e-06 | 3.60e-06 | 0.0e+00 | 3.60e-06 | 3.6e-06 | 3.60e-06 | 3.60e-06 | 0.0e+00 | 0.0e+00 | 7.10e-06 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 3.6e-06 | 0.0e+00 | 1.07e-05 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 3.60e-06 | 1.07e-05 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 3.60e-06 | 0.0e+00 | 0.0e+00 | 3.6e-06 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 3.60e-06 | 0.0e+00 | 3.6e-06 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 3.60e-06 | 0.00e+00 | 0.0e+00 | 3.60e-06 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.60e-06 | 0.00e+00 | 3.60e-06 | 3.60e-06 | 3.60e-06 | 0.00e+00 | 3.60e-06 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 3.60e-06 | 0.0e+00 | 3.60e-06 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.6e-06 | 3.60e-06 | 0.0e+00 | 0.0e+00 | 7.10e-06 | 0.0e+00 | 3.60e-06 | 3.60e-06 | 3.60e-06 | 0.00e+00 | 0.00e+00 | 3.60e-06 | 3.6e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 3.6e-06 | 0.0e+00 | 0.00e+00 | 3.6e-06 | 7.10e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 7.1e-06 | 3.6e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 3.6e-06 | 3.6e-06 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.00e+00 | 3.60e-06 | 0.0e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 0.00e+00 | 3.60e-06 | 7.10e-06 | 0.00e+00 | 7.1e-06 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 0.0e+00 | 7.1e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 | 3.6e-06 |
Rule of thumb: \(k = \sqrt{n/2}\)
The elbow method
Compute k-means clustering for different values of k
Calculate within cluster variation \(SS_{within}\)
Plot and spot the loction of a bend
Source: @boehmke2019hands
Agglomerative clustering (AGNES – AGglomerative NESting)
Divisive hierarchical clustering (DIANA – DIvise ANAlysis)
Dissimilarity (distance) of observations
# pairwise distances between all observations
d <- dist(la.sic) # print(d) to see how it looks like
# creates labels for the dendrogam
l <- london.firms %>% distinct(oslaua) %>% arrange(oslaua)
hclust = hclust(d) # Perform hierarchical clustering using d
plot(hclust, hang=-1, labels=l$oslaua, main='Default from hclust') Tip
Explore what the 2 cluster solution tells us about London?
Reduce the data dimensions: from \(33 (LA) * 1,037 (SIC)\) matrix to an array of \(33\): LA membership to the k clusters
Create k clusters of LA with similar business structure
london.firms %>%
group_by(SICCode.SicText_1) %>%
summarise(n=n()) %>%
arrange(-n) %>%
kbl() %>%
kable_styling(full_width = F, font_size = 11) %>%
scroll_box(width = "1200px", height = "400px")| SICCode.SicText_1 | n |
|---|---|
| 82990 - Other business support service activities n.e.c. | 72756 |
| 70229 - Management consultancy activities other than financial management | 58526 |
| 68100 - Buying and selling of own real estate | 55309 |
| 68209 - Other letting and operating of own or leased real estate | 52058 |
| 96090 - Other service activities n.e.c. | 46572 |
| 99999 - Dormant Company | 45312 |
| 47910 - Retail sale via mail order houses or via Internet | 44270 |
| 62020 - Information technology consultancy activities | 43932 |
| None Supplied | 37778 |
| 41100 - Development of building projects | 29979 |
| 98000 - Residents property management | 29955 |
| 62012 - Business and domestic software development | 21947 |
| 64209 - Activities of other holding companies n.e.c. | 20554 |
| 62090 - Other information technology service activities | 20231 |
| 74909 - Other professional, scientific and technical activities n.e.c. | 17017 |
| 86900 - Other human health activities | 16856 |
| 41202 - Construction of domestic buildings | 16593 |
| 74990 - Non-trading company | 16049 |
| 68320 - Management of real estate on a fee or contract basis | 14885 |
| 96020 - Hairdressing and other beauty treatment | 14281 |
| 64999 - Financial intermediation not elsewhere classified | 13238 |
| 56101 - Licensed restaurants | 12682 |
| 56103 - Take-away food shops and mobile food stands | 11655 |
| 47990 - Other retail sale not in stores, stalls or markets | 11409 |
| 41201 - Construction of commercial buildings | 11393 |
| 69201 - Accounting and auditing activities | 11080 |
| 43999 - Other specialised construction activities n.e.c. | 11075 |
| 43390 - Other building completion and finishing | 9982 |
| 73110 - Advertising agencies | 9849 |
| 46900 - Non-specialised wholesale trade | 9814 |
| 74100 - specialised design activities | 9420 |
| 49410 - Freight transport by road | 9317 |
| 85590 - Other education n.e.c. | 9245 |
| 90030 - Artistic creation | 9223 |
| 56102 - Unlicensed restaurants and cafes | 9129 |
| 59111 - Motion picture production activities | 9112 |
| 47190 - Other retail sale in non-specialised stores | 9054 |
| 70100 - Activities of head offices | 8882 |
| 68310 - Real estate agencies | 8544 |
| 47710 - Retail sale of clothing in specialised stores | 8030 |
| 43210 - Electrical installation | 7821 |
| 78109 - Other activities of employment placement agencies | 7391 |
| 59200 - Sound recording and music publishing activities | 6948 |
| 63990 - Other information service activities n.e.c. | 6635 |
| 47110 - Retail sale in non-specialised stores with food, beverages or tobacco predominating | 6623 |
| 56290 - Other food services | 6560 |
| 43220 - Plumbing, heat and air-conditioning installation | 6327 |
| 46190 - Agents involved in the sale of a variety of goods | 6292 |
| 85600 - Educational support services | 6265 |
| 59112 - Video production activities | 6017 |
| 45112 - Sale of used cars and light motor vehicles | 5781 |
| 90010 - Performing arts | 5764 |
| 70221 - Financial management | 5509 |
| 71111 - Architectural activities | 5452 |
| 56210 - Event catering activities | 5190 |
| 46420 - Wholesale of clothing and footwear | 4969 |
| 45200 - Maintenance and repair of motor vehicles | 4960 |
| 43290 - Other construction installation | 4840 |
| 59113 - Television programme production activities | 4807 |
| 64205 - Activities of financial services holding companies | 4730 |
| 58190 - Other publishing activities | 4649 |
| 70210 - Public relations and communications activities | 4561 |
| 81210 - General cleaning of buildings | 4454 |
| 88990 - Other social work activities without accommodation n.e.c. | 4400 |
| 86210 - General medical practice activities | 4343 |
| 80100 - Private security activities | 4275 |
| 55100 - Hotels and similar accommodation | 4202 |
| 58290 - Other software publishing | 4195 |
| 86101 - Hospital activities | 4151 |
| 86220 - Specialists medical practice activities | 4066 |
| 71129 - Other engineering activities | 4056 |
| 69202 - Bookkeeping activities | 3946 |
| 93199 - Other sports activities | 3714 |
| 46160 - Agents involved in the sale of textiles, clothing, fur, footwear and leather goods | 3699 |
| 49320 - Taxi operation | 3655 |
| 79110 - Travel agency activities | 3652 |
| 78200 - Temporary employment agency activities | 3644 |
| 71122 - Engineering related scientific and technical consulting activities | 3616 |
| 90020 - Support activities to performing arts | 3541 |
| 63120 - Web portals | 3447 |
| 52290 - Other transportation support activities | 3409 |
| 58110 - Book publishing | 3333 |
| 69102 - Solicitors | 3165 |
| 56302 - Public houses and bars | 3113 |
| 93290 - Other amusement and recreation activities n.e.c. | 3105 |
| 66300 - Fund management activities | 3097 |
| 35110 - Production of electricity | 3062 |
| 61900 - Other telecommunications activities | 2964 |
| 82110 - Combined office administrative service activities | 2942 |
| 63110 - Data processing, hosting and related activities | 2930 |
| 62011 - Ready-made interactive leisure and entertainment software development | 2862 |
| 55900 - Other accommodation | 2850 |
| 86230 - Dental practice activities | 2807 |
| 73120 - Media representation services | 2786 |
| 32990 - Other manufacturing n.e.c. | 2766 |
| 78300 - Human resources provision and management of human resources functions | 2752 |
| 69109 - Activities of patent and copyright agents; other legal activities n.e.c. | 2678 |
| 42990 - Construction of other civil engineering projects n.e.c. | 2654 |
| 46450 - Wholesale of perfume and cosmetics | 2594 |
| 43341 - Painting | 2582 |
| 81299 - Other cleaning services | 2524 |
| 52103 - Operation of warehousing and storage facilities for land transport activities | 2473 |
| 46180 - Agents specialized in the sale of other particular products | 2457 |
| 94990 - Activities of other membership organizations n.e.c. | 2456 |
| 66190 - Activities auxiliary to financial intermediation n.e.c. | 2440 |
| 47750 - Retail sale of cosmetic and toilet articles in specialised stores | 2423 |
| 96040 - Physical well-being activities | 2180 |
| 47789 - Other retail sale of new goods in specialised stores (not commercial art galleries and opticians) | 2138 |
| 93130 - Fitness facilities | 2109 |
| 85520 - Cultural education | 2083 |
| 47290 - Other retail sale of food in specialised stores | 2043 |
| 14190 - Manufacture of other wearing apparel and accessories n.e.c. | 2017 |
| 47770 - Retail sale of watches and jewellery in specialised stores | 2012 |
| 94910 - Activities of religious organizations | 1972 |
| 64303 - Activities of venture and development capital companies | 1966 |
| 65120 - Non-life insurance | 1963 |
| 46342 - Wholesale of wine, beer, spirits and other alcoholic beverages | 1962 |
| 49390 - Other passenger land transport | 1953 |
| 68201 - Renting and operating of Housing Association real estate | 1944 |
| 85100 - Pre-primary education | 1886 |
| 59120 - Motion picture, video and television programme post-production activities | 1867 |
| 47599 - Retail of furniture, lighting, and similar (not musical instruments or scores) in specialised store | 1850 |
| 85510 - Sports and recreation education | 1814 |
| 64304 - Activities of open-ended investment companies | 1782 |
| 43320 - Joinery installation | 1741 |
| 77110 - Renting and leasing of cars and light motor vehicles | 1738 |
| 81300 - Landscape service activities | 1698 |
| 18129 - Printing n.e.c. | 1675 |
| 46310 - Wholesale of fruit and vegetables | 1674 |
| 87200 - Residential care activities for learning difficulties, mental health and substance abuse | 1621 |
| 66220 - Activities of insurance agents and brokers | 1609 |
| 49420 - Removal services | 1597 |
| 87900 - Other residential care activities n.e.c. | 1572 |
| 64991 - Security dealing on own account | 1563 |
| 10890 - Manufacture of other food products n.e.c. | 1546 |
| 47640 - Retail sale of sports goods, fishing gear, camping goods, boats and bicycles | 1543 |
| 81222 - Specialised cleaning services | 1543 |
| 45190 - Sale of other motor vehicles | 1540 |
| 46510 - Wholesale of computers, computer peripheral equipment and software | 1516 |
| 46499 - Wholesale of household goods (other than musical instruments) n.e.c. | 1507 |
| 42120 - Construction of railways and underground railways | 1503 |
| 81100 - Combined facilities support activities | 1480 |
| 43910 - Roofing activities | 1477 |
| 85200 - Primary education | 1467 |
| 96010 - Washing and (dry-)cleaning of textile and fur products | 1465 |
| 43330 - Floor and wall covering | 1458 |
| 88910 - Child day-care activities | 1446 |
| 46410 - Wholesale of textiles | 1426 |
| 87300 - Residential care activities for the elderly and disabled | 1419 |
| 46170 - Agents involved in the sale of food, beverages and tobacco | 1402 |
| 53202 - Unlicensed carrier | 1394 |
| 46150 - Agents involved in the sale of furniture, household goods, hardware and ironmongery | 1380 |
| 43310 - Plastering | 1369 |
| 73200 - Market research and public opinion polling | 1365 |
| 64301 - Activities of investment trusts | 1364 |
| 71121 - Engineering design activities for industrial process and production | 1361 |
| 45320 - Retail trade of motor vehicle parts and accessories | 1359 |
| 38110 - Collection of non-hazardous waste | 1354 |
| 46390 - Non-specialised wholesale of food, beverages and tobacco | 1353 |
| 80200 - Security systems service activities | 1337 |
| 10710 - Manufacture of bread; manufacture of fresh pastry goods and cakes | 1330 |
| 86102 - Medical nursing home activities | 1325 |
| 32120 - Manufacture of jewellery and related articles | 1321 |
| 46520 - Wholesale of electronic and telecommunications equipment and parts | 1321 |
| 87100 - Residential nursing care facilities | 1301 |
| 47730 - Dispensing chemist in specialised stores | 1280 |
| 46460 - Wholesale of pharmaceutical goods | 1254 |
| 93120 - Activities of sport clubs | 1243 |
| 74901 - Environmental consulting activities | 1242 |
| 72190 - Other research and experimental development on natural sciences and engineering | 1235 |
| 79120 - Tour operator activities | 1231 |
| 74209 - Photographic activities not elsewhere classified | 1209 |
| 58210 - Publishing of computer games | 1206 |
| 74202 - Other specialist photography | 1193 |
| 47240 - Retail sale of bread, cakes, flour confectionery and sugar confectionery in specialised stores | 1168 |
| 62030 - Computer facilities management activities | 1162 |
| 88100 - Social work activities without accommodation for the elderly and disabled | 1156 |
| 47820 - Retail sale via stalls and markets of textiles, clothing and footwear | 1146 |
| 60200 - Television programming and broadcasting activities | 1145 |
| 58142 - Publishing of consumer and business journals and periodicals | 1143 |
| 84120 - Regulation of health care, education, cultural and other social services, not incl. social security | 1137 |
| 69203 - Tax consultancy | 1136 |
| 45111 - Sale of new cars and light motor vehicles | 1132 |
| 16230 - Manufacture of other builders' carpentry and joinery | 1130 |
| 45310 - Wholesale trade of motor vehicle parts and accessories | 1119 |
| 50200 - Sea and coastal freight water transport | 1114 |
| 94120 - Activities of professional membership organizations | 1113 |
| 72110 - Research and experimental development on biotechnology | 1109 |
| 74902 - Quantity surveying activities | 1107 |
| 47760 - Retail sale of flowers, plants, seeds, fertilizers, pet animals and pet food in specialised stores | 1095 |
| 47410 - Retail sale of computers, peripheral units and software in specialised stores | 1093 |
| 46480 - Wholesale of watches and jewellery | 1092 |
| 47890 - Retail sale via stalls and markets of other goods | 1090 |
| 85320 - Technical and vocational secondary education | 1065 |
| 64922 - Activities of mortgage finance companies | 1038 |
| 31090 - Manufacture of other furniture | 1018 |
| 55209 - Other holiday and other collective accommodation | 1013 |
| 94110 - Activities of business and employers membership organizations | 1008 |
| 66120 - Security and commodity contracts dealing activities | 989 |
| 43342 - Glazing | 984 |
| 64306 - Activities of real estate investment trusts | 981 |
| 79909 - Other reservation service activities n.e.c. | 977 |
| 47510 - Retail sale of textiles in specialised stores | 970 |
| 47781 - Retail sale in commercial art galleries | 965 |
| 85310 - General secondary education | 946 |
| 74300 - Translation and interpretation activities | 941 |
| 90040 - Operation of arts facilities | 935 |
| 43991 - Scaffold erection | 929 |
| 65110 - Life insurance | 921 |
| 82301 - Activities of exhibition and fair organisers | 918 |
| 61100 - Wired telecommunications activities | 913 |
| 47421 - Retail sale of mobile telephones | 912 |
| 46370 - Wholesale of coffee, tea, cocoa and spices | 897 |
| 47250 - Retail sale of beverages in specialised stores | 871 |
| 61200 - Wireless telecommunications activities | 867 |
| 66290 - Other activities auxiliary to insurance and pension funding | 859 |
| 46320 - Wholesale of meat and meat products | 854 |
| 47210 - Retail sale of fruit and vegetables in specialised stores | 840 |
| 93110 - Operation of sports facilities | 824 |
| 66110 - Administration of financial markets | 819 |
| 33140 - Repair of electrical equipment | 818 |
| 33190 - Repair of other equipment | 818 |
| 46380 - Wholesale of other food, including fish, crustaceans and molluscs | 803 |
| 46470 - Wholesale of furniture, carpets and lighting equipment | 759 |
| 53201 - Licensed carriers | 758 |
| 46341 - Wholesale of fruit and vegetable juices, mineral water and soft drinks | 744 |
| 06100 - Extraction of crude petroleum | 741 |
| 46760 - Wholesale of other intermediate products | 740 |
| 14132 - Manufacture of other women's outerwear | 736 |
| 71200 - Technical testing and analysis | 730 |
| 47650 - Retail sale of games and toys in specialised stores | 720 |
| 46140 - Agents involved in the sale of machinery, industrial equipment, ships and aircraft | 718 |
| 95110 - Repair of computers and peripheral equipment | 712 |
| 35140 - Trade of electricity | 710 |
| 47220 - Retail sale of meat and meat products in specialised stores | 702 |
| 64191 - Banks | 701 |
| 74201 - Portrait photographic activities | 697 |
| 82302 - Activities of conference organisers | 686 |
| 47530 - Retail sale of carpets, rugs, wall and floor coverings in specialised stores | 677 |
| 72200 - Research and experimental development on social sciences and humanities | 675 |
| 14131 - Manufacture of other men's outerwear | 669 |
| 64929 - Other credit granting n.e.c. | 668 |
| 09100 - Support activities for petroleum and natural gas extraction | 663 |
| 47540 - Retail sale of electrical household appliances in specialised stores | 653 |
| 26400 - Manufacture of consumer electronics | 650 |
| 33170 - Repair and maintenance of other transport equipment n.e.c. | 650 |
| 46120 - Agents involved in the sale of fuels, ores, metals and industrial chemicals | 637 |
| 46690 - Wholesale of other machinery and equipment | 635 |
| 77390 - Renting and leasing of other machinery, equipment and tangible goods n.e.c. | 631 |
| 42110 - Construction of roads and motorways | 630 |
| 32500 - Manufacture of medical and dental instruments and supplies | 629 |
| 47749 - Retail sale of medical and orthopaedic goods in specialised stores (not incl. hearing aids) n.e.c. | 590 |
| 42220 - Construction of utility projects for electricity and telecommunications | 586 |
| 43120 - Site preparation | 585 |
| 64203 - Activities of construction holding companies | 580 |
| 60100 - Radio broadcasting | 577 |
| 18130 - Pre-press and pre-media services | 566 |
| 20420 - Manufacture of perfumes and toilet preparations | 564 |
| 47610 - Retail sale of books in specialised stores | 561 |
| 46130 - Agents involved in the sale of timber and building materials | 559 |
| 85421 - First-degree level higher education | 557 |
| 25990 - Manufacture of other fabricated metal products n.e.c. | 556 |
| 71112 - Urban planning and landscape architectural activities | 551 |
| 52219 - Other service activities incidental to land transportation, n.e.c. | 550 |
| 46730 - Wholesale of wood, construction materials and sanitary equipment | 536 |
| 47791 - Retail sale of antiques including antique books in stores | 534 |
| 47721 - Retail sale of footwear in specialised stores | 529 |
| 47810 - Retail sale via stalls and markets of food, beverages and tobacco products | 519 |
| 47520 - Retail sale of hardware, paints and glass in specialised stores | 515 |
| 85530 - Driving school activities | 510 |
| 47429 - Retail sale of telecommunications equipment other than mobile telephones | 505 |
| 64202 - Activities of production holding companies | 503 |
| 64921 - Credit granting by non-deposit taking finance houses and other specialist consumer credit grantors | 502 |
| 99000 - Activities of extraterritorial organizations and bodies | 501 |
| 47799 - Retail sale of other second-hand goods in stores (not incl. antiques) | 496 |
| 81229 - Other building and industrial cleaning activities | 493 |
| 7487 - Other business activities | 490 |
| 53100 - Postal activities under universal service obligation | 484 |
| 64910 - Financial leasing | 480 |
| 77400 - Leasing of intellectual property and similar products, except copyright works | 478 |
| 46740 - Wholesale of hardware, plumbing and heating equipment and supplies | 462 |
| 46110 - Agents selling agricultural raw materials, livestock, textile raw materials and semi-finished goods | 459 |
| 33200 - Installation of industrial machinery and equipment | 458 |
| 75000 - Veterinary activities | 458 |
| 92000 - Gambling and betting activities | 452 |
| 45400 - Sale, maintenance and repair of motorcycles and related parts and accessories | 451 |
| 18201 - Reproduction of sound recording | 448 |
| 39000 - Remediation activities and other waste management services | 448 |
| 84110 - General public administration activities | 441 |
| 01500 - Mixed farming | 439 |
| 58130 - Publishing of newspapers | 438 |
| 47782 - Retail sale by opticians | 434 |
| 46439 - Wholesale of radio, television goods & electrical household appliances (other than records, tapes, CD's & video tapes and the equipment used for playing them) | 432 |
| 46720 - Wholesale of metals and metal ores | 432 |
| 51210 - Freight air transport | 429 |
| 59131 - Motion picture distribution activities | 429 |
| 13990 - Manufacture of other textiles n.e.c. | 424 |
| 81221 - Window cleaning services | 420 |
| 43110 - Demolition | 417 |
| 7499 - Non-trading company | 415 |
| 25110 - Manufacture of metal structures and parts of structures | 407 |
| 49319 - Other urban, suburban or metropolitan passenger land transport (not underground, metro or similar) | 405 |
| 56301 - Licensed clubs | 402 |
| 33120 - Repair of machinery | 398 |
| 21100 - Manufacture of basic pharmaceutical products | 397 |
| 11070 - Manufacture of soft drinks; production of mineral waters and other bottled waters | 396 |
| 32300 - Manufacture of sports goods | 392 |
| 78101 - Motion picture, television and other theatrical casting activities | 388 |
| 32409 - Manufacture of other games and toys, n.e.c. | 385 |
| 11010 - Distilling, rectifying and blending of spirits | 384 |
| 82920 - Packaging activities | 381 |
| 31020 - Manufacture of kitchen furniture | 380 |
| 85410 - Post-secondary non-tertiary education | 377 |
| 85422 - Post-graduate level higher education | 375 |
| 22290 - Manufacture of other plastic products | 372 |
| 47630 - Retail sale of music and video recordings in specialised stores | 372 |
| 97000 - Activities of households as employers of domestic personnel | 365 |
| 15120 - Manufacture of luggage, handbags and the like, saddlery and harness | 364 |
| 82190 - Photocopying, document preparation and other specialised office support activities | 360 |
| 69101 - Barristers at law | 358 |
| 96030 - Funeral and related activities | 354 |
| 47620 - Retail sale of newspapers and stationery in specialised stores | 351 |
| 77291 - Renting and leasing of media entertainment equipment | 351 |
| 46360 - Wholesale of sugar and chocolate and sugar confectionery | 346 |
| 82200 - Activities of call centres | 343 |
| 64204 - Activities of distribution holding companies | 342 |
| 13300 - Finishing of textiles | 339 |
| 63910 - News agency activities | 337 |
| 46750 - Wholesale of chemical products | 328 |
| 08990 - Other mining and quarrying n.e.c. | 326 |
| 51102 - Non-scheduled passenger air transport | 326 |
| 26200 - Manufacture of computers and peripheral equipment | 325 |
| 46220 - Wholesale of flowers and plants | 325 |
| 27900 - Manufacture of other electrical equipment | 320 |
| 13921 - Manufacture of soft furnishings | 318 |
| 26110 - Manufacture of electronic components | 318 |
| 59132 - Video distribution activities | 317 |
| 10850 - Manufacture of prepared meals and dishes | 316 |
| 36000 - Water collection, treatment and supply | 316 |
| 80300 - Investigation activities | 316 |
| 77320 - Renting and leasing of construction and civil engineering machinery and equipment | 311 |
| 79901 - Activities of tourist guides | 310 |
| 95220 - Repair of household appliances and home and garden equipment | 310 |
| 52243 - Cargo handling for land transport activities | 309 |
| 10832 - Production of coffee and coffee substitutes | 308 |
| 46330 - Wholesale of dairy products, eggs and edible oils and fats | 306 |
| 20411 - Manufacture of soap and detergents | 305 |
| 09900 - Support activities for other mining and quarrying | 297 |
| 38320 - Recovery of sorted materials | 296 |
| 11050 - Manufacture of beer | 287 |
| 47722 - Retail sale of leather goods in specialised stores | 280 |
| 18203 - Reproduction of computer media | 279 |
| 31010 - Manufacture of office and shop furniture | 275 |
| 47430 - Retail sale of audio and video equipment in specialised stores | 275 |
| 66210 - Risk and damage evaluation | 269 |
| 58141 - Publishing of learned journals | 268 |
| 52230 - Service activities incidental to air transportation | 266 |
| 14110 - Manufacture of leather clothes | 259 |
| 47260 - Retail sale of tobacco products in specialised stores | 258 |
| 28990 - Manufacture of other special-purpose machinery n.e.c. | 257 |
| 25120 - Manufacture of doors and windows of metal | 254 |
| 4521 - Gen construction & civil engineer | 254 |
| 10840 - Manufacture of condiments and seasonings | 253 |
| 38210 - Treatment and disposal of non-hazardous waste | 253 |
| 46210 - Wholesale of grain, unmanufactured tobacco, seeds and animal feeds | 248 |
| 64305 - Activities of property unit trusts | 248 |
| 59133 - Television programme distribution activities | 247 |
| 07290 - Mining of other non-ferrous metal ores | 245 |
| 10320 - Manufacture of fruit and vegetable juice | 244 |
| 10390 - Other processing and preserving of fruit and vegetables | 243 |
| 35300 - Steam and air conditioning supply | 242 |
| 47300 - Retail sale of automotive fuel in specialised stores | 240 |
| 52241 - Cargo handling for water transport activities | 240 |
| 65300 - Pension funding | 239 |
| 35130 - Distribution of electricity | 238 |
| 58120 - Publishing of directories and mailing lists | 238 |
| 46770 - Wholesale of waste and scrap | 237 |
| 47230 - Retail sale of fish, crustaceans and molluscs in specialised stores | 237 |
| 46711 - Wholesale of petroleum and petroleum products | 235 |
| 51101 - Scheduled passenger air transport | 235 |
| 13923 - manufacture of household textiles | 234 |
| 98200 - Undifferentiated service-producing activities of private households for own use | 234 |
| 27400 - Manufacture of electric lighting equipment | 233 |
| 98100 - Undifferentiated goods-producing activities of private households for own use | 232 |
| 52242 - Cargo handling for air transport activities | 229 |
| 17230 - Manufacture of paper stationery | 227 |
| 7011 - Development & sell real estate | 227 |
| 02100 - Silviculture and other forestry activities | 223 |
| 95240 - Repair of furniture and home furnishings | 223 |
| 18202 - Reproduction of video recording | 222 |
| 29100 - Manufacture of motor vehicles | 222 |
| 10821 - Manufacture of cocoa and chocolate confectionery | 221 |
| 33150 - Repair and maintenance of ships and boats | 220 |
| 74203 - Film processing | 216 |
| 01490 - Raising of other animals | 213 |
| 52220 - Service activities incidental to water transportation | 211 |
| 01110 - Growing of cereals (except rice), leguminous crops and oil seeds | 210 |
| 16290 - Manufacture of other products of wood; manufacture of articles of cork, straw and plaiting materials | 210 |
| 49100 - Passenger rail transport, interurban | 209 |
| 46440 - Wholesale of china and glassware and cleaning materials | 208 |
| 50100 - Sea and coastal passenger water transport | 207 |
| 61300 - Satellite telecommunications activities | 203 |
| 95210 - Repair of consumer electronics | 203 |
| 01130 - Growing of vegetables and melons, roots and tubers | 200 |
| 29320 - Manufacture of other parts and accessories for motor vehicles | 198 |
| 81291 - Disinfecting and exterminating services | 195 |
| 94920 - Activities of political organizations | 192 |
| 84250 - Fire service activities | 191 |
| 25620 - Machining | 186 |
| 01610 - Support activities for crop production | 185 |
| 23700 - Cutting, shaping and finishing of stone | 182 |
| 49200 - Freight rail transport | 180 |
| 95120 - Repair of communication equipment | 179 |
| 10831 - Tea processing | 178 |
| 15200 - Manufacture of footwear | 178 |
| 55300 - Recreational vehicle parks, trailer parks and camping grounds | 178 |
| 21200 - Manufacture of pharmaceutical preparations | 177 |
| 33130 - Repair of electronic and optical equipment | 177 |
| 17220 - Manufacture of household and sanitary goods and of toilet requisites | 175 |
| 95290 - Repair of personal and household goods n.e.c. | 175 |
| 68202 - Letting and operating of conference and exhibition centres | 169 |
| 91020 - Museums activities | 168 |
| 20590 - Manufacture of other chemical products n.e.c. | 166 |
| 01430 - Raising of horses and other equines | 165 |
| 10720 - Manufacture of rusks and biscuits; manufacture of preserved pastry goods and cakes | 165 |
| 47591 - Retail sale of musical instruments and scores | 165 |
| 33160 - Repair and maintenance of aircraft and spacecraft | 164 |
| 02400 - Support services to forestry | 162 |
| 10520 - Manufacture of ice cream | 160 |
| 77210 - Renting and leasing of recreational and sports goods | 155 |
| 26511 - Manufacture of electronic measuring, testing etc. equipment, not for industrial process control | 154 |
| 35120 - Transmission of electricity | 150 |
| 59140 - Motion picture projection activities | 149 |
| 20530 - Manufacture of essential oils | 146 |
| 46431 - Wholesale of audio tapes, records, CDs and video tapes and the equipment on which these are played | 146 |
| 46719 - Wholesale of other fuels and related products | 145 |
| 52213 - Operation of bus and coach passenger facilities at bus and coach stations | 144 |
| 95250 - Repair of watches, clocks and jewellery | 144 |
| 10920 - Manufacture of prepared pet foods | 143 |
| 14142 - Manufacture of women's underwear | 143 |
| 82911 - Activities of collection agencies | 142 |
| 37000 - Sewerage | 141 |
| 9305 - Other service activities n.e.c. | 140 |
| 55202 - Youth hostels | 138 |
| 01629 - Support activities for animal production (other than farm animal boarding and care) n.e.c. | 135 |
| 24100 - Manufacture of basic iron and steel and of ferro-alloys | 135 |
| 77351 - Renting and leasing of air passenger transport equipment | 135 |
| 10612 - Manufacture of breakfast cereals and cereals-based food | 133 |
| 10860 - Manufacture of homogenized food preparations and dietetic food | 133 |
| 23410 - Manufacture of ceramic household and ornamental articles | 132 |
| 10130 - Production of meat and poultry meat products | 130 |
| 64201 - Activities of agricultural holding companies | 130 |
| 77299 - Renting and leasing of other personal and household goods | 130 |
| 29310 - Manufacture of electrical and electronic equipment for motor vehicles and their engines | 128 |
| 46610 - Wholesale of agricultural machinery, equipment and supplies | 128 |
| 30300 - Manufacture of air and spacecraft and related machinery | 127 |
| 42910 - Construction of water projects | 127 |
| 35230 - Trade of gas through mains | 126 |
| 46650 - Wholesale of office furniture | 125 |
| 84240 - Public order and safety activities | 124 |
| 7414 - Business & management consultancy | 123 |
| 14120 - Manufacture of workwear | 122 |
| 30990 - Manufacture of other transport equipment n.e.c. | 118 |
| 46620 - Wholesale of machine tools | 118 |
| 46660 - Wholesale of other office machinery and equipment | 116 |
| 18121 - Manufacture of printed labels | 115 |
| 46630 - Wholesale of mining, construction and civil engineering machinery | 115 |
| 52101 - Operation of warehousing and storage facilities for water transport activities | 115 |
| 95230 - Repair of footwear and leather goods | 114 |
| 01300 - Plant propagation | 111 |
| 13200 - Weaving of textiles | 111 |
| 27110 - Manufacture of electric motors, generators and transformers | 111 |
| 38120 - Collection of hazardous waste | 111 |
| 77330 - Renting and leasing of office machinery and equipment (including computers) | 111 |
| 94200 - Activities of trade unions | 109 |
| 10410 - Manufacture of oils and fats | 108 |
| 7415 - Holding Companies including Head Offices | 108 |
| 24410 - Precious metals production | 106 |
| 23320 - Manufacture of bricks, tiles and construction products, in baked clay | 105 |
| 46350 - Wholesale of tobacco products | 105 |
| 84130 - Regulation of and contribution to more efficient operation of businesses | 105 |
| 06200 - Extraction of natural gas | 104 |
| 55201 - Holiday centres and villages | 104 |
| 77120 - Renting and leasing of trucks and other heavy vehicles | 104 |
| 10110 - Processing and preserving of meat | 103 |
| 91011 - Library activities | 103 |
| 22190 - Manufacture of other rubber products | 102 |
| 25730 - Manufacture of tools | 102 |
| 35210 - Manufacture of gas | 102 |
| 23610 - Manufacture of concrete products for construction purposes | 101 |
| 33110 - Repair of fabricated metal products | 100 |
| 46240 - Wholesale of hides, skins and leather | 99 |
| 32130 - Manufacture of imitation jewellery and related articles | 98 |
| 13910 - Manufacture of knitted and crocheted fabrics | 97 |
| 24200 - Manufacture of tubes, pipes, hollow profiles and related fittings, of steel | 97 |
| 64110 - Central banking | 97 |
| 27510 - Manufacture of electric domestic appliances | 96 |
| 28290 - Manufacture of other general-purpose machinery n.e.c. | 96 |
| 42210 - Construction of utility projects for fluids | 96 |
| 64992 - Factoring | 96 |
| 84220 - Defence activities | 95 |
| 01280 - Growing of spices, aromatic, drug and pharmaceutical crops | 93 |
| 52102 - Operation of warehousing and storage facilities for air transport activities | 93 |
| 26520 - Manufacture of watches and clocks | 92 |
| 27120 - Manufacture of electricity distribution and control apparatus | 91 |
| 65202 - Non-life reinsurance | 91 |
| 30110 - Building of ships and floating structures | 89 |
| 13960 - Manufacture of other technical and industrial textiles | 88 |
| 26309 - Manufacture of communication equipment other than telegraph, and telephone apparatus and equipment | 88 |
| 32401 - Manufacture of professional and arcade games and toys | 87 |
| 08910 - Mining of chemical and fertilizer minerals | 86 |
| 43130 - Test drilling and boring | 84 |
| 5530 - Restaurants | 84 |
| 84230 - Justice and judicial activities | 84 |
| 32200 - Manufacture of musical instruments | 83 |
| 22220 - Manufacture of plastic packing goods | 82 |
| 91012 - Archives activities | 82 |
| 10822 - Manufacture of sugar confectionery | 81 |
| 30920 - Manufacture of bicycles and invalid carriages | 81 |
| 91040 - Botanical and zoological gardens and nature reserves activities | 81 |
| 01621 - Farm animal boarding and care | 79 |
| 03110 - Marine fishing | 79 |
| 20140 - Manufacture of other organic basic chemicals | 79 |
| 28220 - Manufacture of lifting and handling equipment | 79 |
| 11040 - Manufacture of other non-distilled fermented beverages | 78 |
| 17290 - Manufacture of other articles of paper and paperboard n.e.c. | 78 |
| 26512 - Manufacture of electronic industrial process control equipment | 78 |
| 91030 - Operation of historical sites and buildings and similar visitor attractions | 78 |
| 42130 - Construction of bridges and tunnels | 77 |
| 49311 - Urban and suburban passenger railway transportation by underground, metro and similar systems | 77 |
| 77341 - Renting and leasing of passenger water transport equipment | 73 |
| 25720 - Manufacture of locks and hinges | 72 |
| 29201 - Manufacture of bodies (coachwork) for motor vehicles (except caravans) | 72 |
| 11020 - Manufacture of wine from grape | 71 |
| 4525 - Other special trades construction | 71 |
| 03210 - Marine aquaculture | 70 |
| 20301 - Manufacture of paints, varnishes and similar coatings, mastics and sealants | 70 |
| 12000 - Manufacture of tobacco products | 69 |
| 17219 - Manufacture of other paper and paperboard containers | 69 |
| 20412 - Manufacture of cleaning and polishing preparations | 69 |
| 25610 - Treatment and coating of metals | 69 |
| 64302 - Activities of unit trusts | 68 |
| 93210 - Activities of amusement parks and theme parks | 67 |
| 07100 - Mining of iron ores | 66 |
| 30120 - Building of pleasure and sporting boats | 66 |
| 35220 - Distribution of gaseous fuels through mains | 66 |
| 28250 - Manufacture of non-domestic cooling and ventilation equipment | 65 |
| 27320 - Manufacture of other electronic and electric wires and cables | 63 |
| 01700 - Hunting, trapping and related service activities | 62 |
| 03120 - Freshwater fishing | 62 |
| 10200 - Processing and preserving of fish, crustaceans and molluscs | 62 |
| 27200 - Manufacture of batteries and accumulators | 62 |
| 13100 - Preparation and spinning of textile fibres | 61 |
| 14390 - Manufacture of other knitted and crocheted apparel | 61 |
| 18110 - Printing of newspapers | 61 |
| 01630 - Post-harvest crop activities | 59 |
| 20130 - Manufacture of other inorganic basic chemicals | 59 |
| 5190 - Other wholesale | 59 |
| 7020 - Letting of own property | 59 |
| 01250 - Growing of other tree and bush fruits and nuts | 58 |
| 10519 - Manufacture of other milk products | 58 |
| 50300 - Inland passenger water transport | 57 |
| 02200 - Logging | 56 |
| 7220 - Software consultancy and supply | 56 |
| 23120 - Shaping and processing of flat glass | 55 |
| 26600 - Manufacture of irradiation, electromedical and electrotherapeutic equipment | 55 |
| 47741 - Retail sale of hearing aids | 55 |
| 19201 - Mineral oil refining | 54 |
| 22110 - Manufacture of rubber tyres and tubes; retreading and rebuilding of rubber tyres | 54 |
| 23990 - Manufacture of other non-metallic mineral products n.e.c. | 54 |
| 26120 - Manufacture of loaded electronic boards | 54 |
| 01120 - Growing of rice | 53 |
| 18140 - Binding and related services | 53 |
| 52212 - Operation of rail passenger facilities at railway stations | 53 |
| 9999 - Dormant company | 53 |
| 7012 - Buying & sell own real estate | 52 |
| 7260 - Other computer related activities | 52 |
| 13922 - manufacture of canvas goods, sacks, etc. | 51 |
| 28131 - Manufacture of pumps | 51 |
| 13931 - Manufacture of woven or tufted carpets and rugs | 50 |
| 17120 - Manufacture of paper and paperboard | 50 |
| 20160 - Manufacture of plastics in primary forms | 50 |
| 26701 - Manufacture of optical precision instruments | 49 |
| 46491 - Wholesale of musical instruments | 49 |
| 08110 - Quarrying of ornamental and building stone, limestone, gypsum, chalk and slate | 48 |
| 19209 - Other treatment of petroleum products (excluding petrochemicals manufacture) | 48 |
| 7412 - Accounting, auditing; tax consult | 48 |
| 01190 - Growing of other non-perennial crops | 47 |
| 20150 - Manufacture of fertilizers and nitrogen compounds | 47 |
| 28930 - Manufacture of machinery for food, beverage and tobacco processing | 47 |
| 4531 - Installation electrical wiring etc. | 47 |
| 84210 - Foreign affairs | 47 |
| 10512 - Butter and cheese production | 46 |
| 26702 - Manufacture of photographic and cinematographic equipment | 46 |
| 23190 - Manufacture and processing of other glass, including technical glassware | 45 |
| 5540 - Bars | 45 |
| 20200 - Manufacture of pesticides and other agrochemical products | 44 |
| 28110 - Manufacture of engines and turbines, except aircraft, vehicle and cycle engines | 44 |
| 64192 - Building societies | 44 |
| 6523 - Other financial intermediation | 44 |
| 93191 - Activities of racehorse owners | 44 |
| 24420 - Aluminium production | 43 |
| 28490 - Manufacture of other machine tools | 43 |
| 24450 - Other non-ferrous metal production | 42 |
| 26301 - Manufacture of telegraph and telephone apparatus and equipment | 42 |
| 01210 - Growing of grapes | 41 |
| 11030 - Manufacture of cider and other fruit wines | 41 |
| 13950 - Manufacture of non-wovens and articles made from non-wovens, except apparel | 41 |
| 22210 - Manufacture of plastic plates, sheets, tubes and profiles | 41 |
| 16240 - Manufacture of wooden containers | 40 |
| 23630 - Manufacture of ready-mixed concrete | 40 |
| 6024 - Freight transport by road | 40 |
| 23620 - Manufacture of plaster products for construction purposes | 39 |
| 23690 - Manufacture of other articles of concrete, plaster and cement | 39 |
| 16100 - Sawmilling and planing of wood | 38 |
| 25210 - Manufacture of central heating radiators and boilers | 38 |
| 51220 - Space transport | 37 |
| 6420 - Telecommunications | 37 |
| 14141 - Manufacture of men's underwear | 36 |
| 5010 - Sale of motor vehicles | 36 |
| 77342 - Renting and leasing of freight water transport equipment | 36 |
| 01160 - Growing of fibre crops | 35 |
| 2222 - Printing not elsewhere classified | 35 |
| 3663 - Other manufacturing | 35 |
| 4545 - Other building completion | 35 |
| 03220 - Freshwater aquaculture | 34 |
| 01290 - Growing of other perennial crops | 33 |
| 15110 - Tanning and dressing of leather; dressing and dyeing of fur | 33 |
| 46230 - Wholesale of live animals | 33 |
| 5510 - Hotels & motels with or without restaurant | 33 |
| 01410 - Raising of dairy cattle | 32 |
| 10810 - Manufacture of sugar | 32 |
| 31030 - Manufacture of mattresses | 32 |
| 10611 - Grain milling | 31 |
| 16210 - Manufacture of veneer sheets and wood-based panels | 31 |
| 28140 - Manufacture of taps and valves | 31 |
| 30910 - Manufacture of motorcycles | 31 |
| 28150 - Manufacture of bearings, gears, gearing and driving elements | 30 |
| 28940 - Manufacture of machinery for textile, apparel and leather production | 30 |
| 30200 - Manufacture of railway locomotives and rolling stock | 30 |
| 50400 - Inland freight water transport | 30 |
| 7420 - Architectural, technical consult | 30 |
| 05101 - Deep coal mines | 29 |
| 16220 - Manufacture of assembled parquet floors | 29 |
| 23110 - Manufacture of flat glass | 29 |
| 25500 - Forging, pressing, stamping and roll-forming of metal; powder metallurgy | 29 |
| 38220 - Treatment and disposal of hazardous waste | 29 |
| 4534 - Other building installation | 29 |
| 01450 - Raising of sheep and goats | 28 |
| 01470 - Raising of poultry | 28 |
| 10120 - Processing and preserving of poultry meat | 28 |
| 13939 - Manufacture of other carpets and rugs | 28 |
| 24540 - Casting of other non-ferrous metals | 28 |
| 25940 - Manufacture of fasteners and screw machine products | 28 |
| 01220 - Growing of tropical and subtropical fruits | 27 |
| 17211 - Manufacture of corrugated paper and paperboard, sacks and bags | 27 |
| 22230 - Manufacture of builders ware of plastic | 27 |
| 5142 - Wholesale of clothing and footwear | 27 |
| 7222 - Other software consultancy and supply | 27 |
| 7440 - Advertising | 27 |
| 17240 - Manufacture of wallpaper | 26 |
| 01420 - Raising of other cattle and buffaloes | 25 |
| 4533 - Plumbing | 25 |
| 46640 - Wholesale of machinery for the textile industry and of sewing and knitting machines | 25 |
| 29202 - Manufacture of trailers and semi-trailers | 24 |
| 6330 - Travel agencies etc; tourist | 24 |
| 6603 - Non-life insurance/reinsurance | 24 |
| 7032 - Manage real estate, fee or contract | 24 |
| 01270 - Growing of beverage crops | 23 |
| 5212 - Other retail non-specialised stores | 23 |
| 5242 - Retail sale of clothing | 23 |
| 32110 - Striking of coins | 22 |
| 84300 - Compulsory social security activities | 22 |
| 9231 - Artistic & literary creation etc | 22 |
| 10511 - Liquid milk and cream production | 21 |
| 4544 - Painting and glazing | 21 |
| 7031 - Real estate agencies | 21 |
| 7450 - Labour recruitment | 21 |
| 01240 - Growing of pome fruits and stone fruits | 20 |
| 10730 - Manufacture of macaroni, noodles, couscous and similar farinaceous products | 20 |
| 24530 - Casting of light metals | 20 |
| 28302 - Manufacture of agricultural and forestry machinery other than tractors | 20 |
| 77310 - Renting and leasing of agricultural machinery and equipment | 20 |
| 05102 - Open cast coal working | 19 |
| 10310 - Processing and preserving of potatoes | 19 |
| 10910 - Manufacture of prepared feeds for farm animals | 19 |
| 20120 - Manufacture of dyes and pigments | 19 |
| 25930 - Manufacture of wire products, chain and springs | 19 |
| 28210 - Manufacture of ovens, furnaces and furnace burners | 19 |
| 3614 - Manufacture of other furniture | 19 |
| 7411 - Legal activities | 19 |
| 24520 - Casting of steel | 18 |
| 25400 - Manufacture of weapons and ammunition | 18 |
| 25710 - Manufacture of cutlery | 18 |
| 27310 - Manufacture of fibre optic cables | 18 |
| 2852 - General mechanical engineering | 18 |
| 29203 - Manufacture of caravans | 18 |
| 5147 - Wholesale of other household goods | 18 |
| 01640 - Seed processing for propagation | 17 |
| 27520 - Manufacture of non-electric domestic appliances | 17 |
| 28120 - Manufacture of fluid power equipment | 17 |
| 2875 - Manufacture other fabricated metal products | 17 |
| 5244 - Retail furniture household etc | 17 |
| 7210 - Hardware consultancy | 17 |
| 81223 - Furnace and chimney cleaning services | 17 |
| 82912 - Activities of credit bureaus | 17 |
| 02300 - Gathering of wild growing non-wood products | 16 |
| 20110 - Manufacture of industrial gases | 16 |
| 20302 - Manufacture of printing ink | 16 |
| 23310 - Manufacture of ceramic tiles and flags | 16 |
| 23490 - Manufacture of other ceramic products n.e.c. | 16 |
| 24440 - Copper production | 16 |
| 28230 - Manufacture of office machinery and equipment (except computers and peripheral equipment) | 16 |
| 5552 - Catering | 16 |
| 65201 - Life reinsurance | 16 |
| 01260 - Growing of oleaginous fruits | 15 |
| 07210 - Mining of uranium and thorium ores | 15 |
| 2213 - Publish journals & periodicals | 15 |
| 28921 - Manufacture of machinery for mining | 15 |
| 28960 - Manufacture of plastics and rubber machinery | 15 |
| 5248 - Other retail specialist stores | 15 |
| 08930 - Extraction of salt | 14 |
| 14200 - Manufacture of articles of fur | 14 |
| 23140 - Manufacture of glass fibres | 14 |
| 24510 - Casting of iron | 14 |
| 28410 - Manufacture of metal forming machinery | 14 |
| 32910 - Manufacture of brooms and brushes | 14 |
| 4522 - Erection of roof covering & frames | 14 |
| 4542 - Joinery installation | 14 |
| 49500 - Transport via pipeline | 14 |
| 5143 - Wholesale electric household goods | 14 |
| 08120 - Operation of gravel and sand pits; mining of clays and kaolin | 13 |
| 14310 - Manufacture of knitted and crocheted hosiery | 13 |
| 23440 - Manufacture of other technical ceramic products | 13 |
| 25290 - Manufacture of other tanks, reservoirs and containers of metal | 13 |
| 38310 - Dismantling of wrecks | 13 |
| 5134 - Wholesale of alcohol and other drinks | 13 |
| 26513 - Manufacture of non-electronic measuring, testing etc. equipment, not for industrial process control | 12 |
| 27330 - Manufacture of wiring devices | 12 |
| 28240 - Manufacture of power-driven hand tools | 12 |
| 3162 - Manufacture other electrical equipment | 12 |
| 6340 - Other transport agencies | 12 |
| 6512 - Other monetary intermediation | 12 |
| 13940 - Manufacture of cordage, rope, twine and netting | 11 |
| 17110 - Manufacture of pulp | 11 |
| 28923 - Manufacture of equipment for concrete crushing and screening and roadworks | 11 |
| 5245 - Retail electric h'hold, etc. goods | 11 |
| 6312 - Storage & warehousing | 11 |
| 6601 - Life insurance/reinsurance | 11 |
| 9234 - Other entertainment activities | 11 |
| 01140 - Growing of sugar cane | 10 |
| 1822 - Manufacture of other outerwear | 10 |
| 25910 - Manufacture of steel drums and similar containers | 10 |
| 25920 - Manufacture of light metal packaging | 10 |
| 2811 - Manufacture metal structures & parts | 10 |
| 7221 - Software publishing | 10 |
| 7484 - Other business activities | 10 |
| 8514 - Other human health activities | 10 |
| 9261 - Operate sports arenas & stadiums | 10 |
| 01230 - Growing of citrus fruits | 9 |
| 01440 - Raising of camels and camelids | 9 |
| 10420 - Manufacture of margarine and similar edible fats | 9 |
| 4010 - Production | 9 |
| 5020 - Maintenance & repair of motors | 9 |
| 5263 - Other non-store retail sale | 9 |
| 7460 - Investigation & security | 9 |
| 10620 - Manufacture of starches and starch products | 8 |
| 2211 - Publishing of books | 8 |
| 2524 - Manufacture of other plastic products | 8 |
| 25300 - Manufacture of steam generators, except central heating hot water boilers | 8 |
| 26514 - Manufacture of non-electronic industrial process control equipment | 8 |
| 2710 - Manufacture of basic iron & steel & of Ferro-alloys | 8 |
| 3611 - Manufacture of chairs and seats | 8 |
| 4550 - Rent construction equipment with operator | 8 |
| 5132 - Wholesale of meat and meat products | 8 |
| 5141 - Wholesale of textiles | 8 |
| 7250 - Maintenance office & computing mach | 8 |
| 7481 - Portrait photographic activities, other specialist photography, film processing | 8 |
| 9302 - Hairdressing & other beauty treatment | 8 |
| 01150 - Growing of tobacco | 7 |
| 23200 - Manufacture of refractory products | 7 |
| 23420 - Manufacture of ceramic sanitary fixtures | 7 |
| 23430 - Manufacture of ceramic insulators and insulating fittings | 7 |
| 26800 - Manufacture of magnetic and optical media | 7 |
| 28922 - Manufacture of earthmoving equipment | 7 |
| 2922 - Manufacture of lift & handling equipment | 7 |
| 4511 - Demolition buildings; earth moving | 7 |
| 4532 - Insulation work activities | 7 |
| 5050 - Retail sale of automotive fuel | 7 |
| 5114 - Agents in industrial equipment, etc. | 7 |
| 5184 - Wholesale of computers, computer peripheral equipment & software | 7 |
| 5211 - Retail in non-specialised stores holding an alcohol licence, with food, beverages or tobacco predominating, not elsewhere classified | 7 |
| 5250 - Retail other secondhand goods | 7 |
| 6022 - Taxi operation | 7 |
| 7134 - Rent other machinery & equip | 7 |
| 7482 - Packaging activities | 7 |
| 9211 - Motion picture and video production | 7 |
| 01460 - Raising of swine/pigs | 6 |
| 11060 - Manufacture of malt | 6 |
| 1824 - Manufacture other wearing apparel etc. | 6 |
| 20170 - Manufacture of synthetic rubber in primary forms | 6 |
| 20520 - Manufacture of glues | 6 |
| 24330 - Cold forming or folding | 6 |
| 5139 - Non-specialised wholesale food, etc. | 6 |
| 5156 - Wholesale other intermediate goods | 6 |
| 5261 - Retail sale via mail order houses | 6 |
| 7470 - Other cleaning activities | 6 |
| 77220 - Renting of video tapes and disks | 6 |
| 77352 - Renting and leasing of freight air transport equipment | 6 |
| 8021 - General secondary education | 6 |
| 8042 - Adult and other education | 6 |
| 9220 - Radio and television activities | 6 |
| 9271 - Gambling and betting activities | 6 |
| 9800 - Residents property management | 6 |
| 1533 - Process etc. fruit, vegetables | 5 |
| 1581 - Manufacture of bread, fresh pastry & cakes | 5 |
| 19100 - Manufacture of coke oven products | 5 |
| 2215 - Other publishing | 5 |
| 28301 - Manufacture of agricultural tractors | 5 |
| 28910 - Manufacture of machinery for metallurgy | 5 |
| 2924 - Manufacture of other general machinery | 5 |
| 30400 - Manufacture of military fighting vehicles | 5 |
| 3511 - Building and repairing of ships | 5 |
| 4541 - Plastering | 5 |
| 4543 - Floor and wall covering | 5 |
| 5113 - Agents in building materials | 5 |
| 5152 - Wholesale of metals and metal ores | 5 |
| 5186 - Wholesale of other electronic parts & equipment | 5 |
| 6712 - Security broking & fund management | 5 |
| 7240 - Data base activities | 5 |
| 8030 - Higher education | 5 |
| 8531 - Social work with accommodation | 5 |
| 8532 - Social work without accommodation | 5 |
| 9112 - Professional organisations | 5 |
| 9262 - Other sporting activities | 5 |
| 9272 - Other recreational activities nec | 5 |
| 0141 - Agricultural service activities | 4 |
| 05200 - Mining of lignite | 4 |
| 1589 - Manufacture of other food products | 4 |
| 1717 - Preparation & spin of other textiles | 4 |
| 1823 - Manufacture of underwear | 4 |
| 2051 - Manufacture of other products of wood | 4 |
| 20600 - Manufacture of man-made fibres | 4 |
| 2121 - Manufacture of cartons, boxes & cases of corrugated paper & paperboard | 4 |
| 2225 - Ancillary printing operations | 4 |
| 23510 - Manufacture of cement | 4 |
| 23520 - Manufacture of lime and plaster | 4 |
| 23910 - Production of abrasive products | 4 |
| 2862 - Manufacture of tools | 4 |
| 28950 - Manufacture of machinery for paper and paperboard production | 4 |
| 3110 - Manufacture electric motors, generators etc. | 4 |
| 3230 - Manufacture TV & radio, sound or video etc. | 4 |
| 3410 - Manufacture of motor vehicles | 4 |
| 4523 - Construction roads, airfields etc. | 4 |
| 5145 - Wholesale of perfume and cosmetics | 4 |
| 52211 - Operation of rail freight terminals | 4 |
| 5226 - Retail sale of tobacco products | 4 |
| 5231 - Dispensing chemists | 4 |
| 5243 - Retail of footwear & leather goods | 4 |
| 5247 - Retail books, newspapers etc. | 4 |
| 6010 - Transport via railways | 4 |
| 6110 - Sea and coastal water transport | 4 |
| 6210 - Scheduled air transport | 4 |
| 6511 - Central banking | 4 |
| 6521 - Financial leasing | 4 |
| 7310 - R & d on nat sciences & engineering | 4 |
| 7413 - Market research, opinion polling | 4 |
| 9301 - Wash & dry clean textile & fur | 4 |
| 08920 - Extraction of peat | 3 |
| 1110 - Extraction petroleum & natural gas | 3 |
| 2123 - Manufacture of paper stationery | 3 |
| 23640 - Manufacture of mortars | 3 |
| 2416 - Manufacture of plastics in primary forms | 3 |
| 24430 - Lead, zinc and tin production | 3 |
| 24460 - Processing of nuclear fuel | 3 |
| 2466 - Manufacture of other chemical products | 3 |
| 2621 - Manufacture of ceramic household etc. goods | 3 |
| 2625 - Manufacture of other ceramic products | 3 |
| 28132 - Manufacture of compressors | 3 |
| 2874 - Manufacture fasteners, screw, chains etc. | 3 |
| 3210 - Manufacture of electronic components | 3 |
| 3612 - Manufacture other office & shop furniture | 3 |
| 4020 - Mfr of gas; mains distribution | 3 |
| 5119 - Agents in sale of variety of goods | 3 |
| 5131 - Wholesale of fruit and vegetables | 3 |
| 5222 - Retail of meat and meat products | 3 |
| 5225 - Retail alcoholic & other beverages | 3 |
| 5227 - Other retail food etc. specialised | 3 |
| 5241 - Retail sale of textiles | 3 |
| 6021 - Other scheduled passenger land transport | 3 |
| 6023 - Other passenger land transport | 3 |
| 6321 - Other supporting land transport | 3 |
| 6323 - Other supporting air transport | 3 |
| 6412 - Courier other than national post | 3 |
| 6713 - Auxiliary financial intermed | 3 |
| 8513 - Dental practice activities | 3 |
| 0111 - Grow cereals & other crops | 2 |
| 1513 - Production meat & poultry products | 2 |
| 1571 - Manufacture of prepared farm animal feeds | 2 |
| 1598 - Produce mineral water, soft drinks | 2 |
| 1740 - Manufacture made-up textiles, not apparel | 2 |
| 1910 - Tanning and dressing of leather | 2 |
| 1920 - Manufacture of luggage & the like, saddlery | 2 |
| 2112 - Manufacture of paper & paperboard | 2 |
| 2212 - Publishing of newspapers | 2 |
| 23130 - Manufacture of hollow glass | 2 |
| 2320 - Manufacture of refined petroleum products | 2 |
| 2413 - Manufacture other inorganic basic chemicals | 2 |
| 2415 - Manufacture fertilizers, nitrogen compounds | 2 |
| 2430 - Manufacture of paints, print ink & mastics etc. | 2 |
| 2452 - Manufacture perfumes & toilet preparations | 2 |
| 2513 - Manufacture of other rubber products | 2 |
| 2742 - Aluminium production | 2 |
| 2851 - Treatment and coat metals | 2 |
| 2912 - Manufacture of pumps & compressors | 2 |
| 2952 - Manufacture machines for mining, quarry etc. | 2 |
| 2954 - Manufacture for textile, apparel & leather | 2 |
| 2956 - Manufacture other special purpose machine | 2 |
| 3002 - Manufacture computers & process equipment | 2 |
| 3130 - Manufacture of insulated wire & cable | 2 |
| 3310 - Manufacture medical, orthopaedic etc. equipment | 2 |
| 3420 - Manufacture motor vehicle bodies etc. | 2 |
| 3430 - Manufacture motor vehicle & engine parts | 2 |
| 5030 - Sale of motor vehicle parts etc. | 2 |
| 5116 - Agents in textiles, footwear etc. | 2 |
| 5117 - Agents in food, drink & tobacco | 2 |
| 5144 - Wholesale of china, wallpaper etc. | 2 |
| 5146 - Wholesale of pharmaceutical goods | 2 |
| 5153 - Wholesale wood, construction etc. | 2 |
| 5164 - Wholesale office machinery & equip | 2 |
| 5170 - Other wholesale | 2 |
| 5185 - Wholesale of other office machinery & equipment | 2 |
| 5221 - Retail of fruit and vegetables | 2 |
| 5224 - Retail bread, cakes, confectionery | 2 |
| 5274 - Repair not elsewhere classified | 2 |
| 6120 - Inland water transport | 2 |
| 6311 - Cargo handling | 2 |
| 6411 - National post activities | 2 |
| 6711 - Administration of financial markets | 2 |
| 7110 - Renting of automobiles | 2 |
| 7132 - Rent civil engineering machinery | 2 |
| 7133 - Rent office machinery inc computers | 2 |
| 8041 - Driving school activities | 2 |
| 8512 - Medical practice activities | 2 |
| 9251 - Library and archives activities | 2 |
| 9500 - Private households with employees | 2 |
| 0130 - Crops combined with animals, mixed farms | 1 |
| 0150 - Hunting and game rearing inc. services | 1 |
| 0501 - Fishing | 1 |
| 1010 - Mining & agglomeration of hard coal | 1 |
| 1320 - Mining non-ferrous metal ores | 1 |
| 1552 - Manufacture of ice cream | 1 |
| 1583 - Manufacture of sugar | 1 |
| 1596 - Manufacture of beer | 1 |
| 1711 - Prepare & spin cotton-type fibres | 1 |
| 1713 - Prepare & spin worsted-type fibres | 1 |
| 1721 - Cotton-type weaving | 1 |
| 1723 - Worsted-type weaving | 1 |
| 1725 - Other textile weaving | 1 |
| 1730 - Finishing of textiles | 1 |
| 1751 - Manufacture of carpets and rugs | 1 |
| 1752 - Manufacture cordage, rope, twine & netting | 1 |
| 2010 - Sawmill, plane, impregnation wood | 1 |
| 2030 - Manufacture builders' carpentry & joinery | 1 |
| 20510 - Manufacture of explosives | 1 |
| 2125 - Manufacture of paper & paperboard goods | 1 |
| 2214 - Publishing of sound recordings | 1 |
| 2223 - Bookbinding and finishing | 1 |
| 2231 - Reproduction of sound recording | 1 |
| 23650 - Manufacture of fibre cement | 1 |
| 24310 - Cold drawing of bars | 1 |
| 24340 - Cold drawing of wire | 1 |
| 2441 - Manufacture of basic pharmaceutical prods | 1 |
| 2451 - Manufacture soap & detergents, polishes etc. | 1 |
| 2522 - Manufacture of plastic pack goods | 1 |
| 2611 - Manufacture of flat glass | 1 |
| 2612 - Shaping & process of flat glass | 1 |
| 2661 - Manufacture concrete goods for construction | 1 |
| 2681 - Production of abrasive products | 1 |
| 2733 - Cold forming or folding | 1 |
| 2743 - Lead, zinc and tin production | 1 |
| 2812 - Manufacture builders' carpentry of metal | 1 |
| 2821 - Manufacture tanks, etc. & metal containers | 1 |
| 2873 - Manufacture of wire products | 1 |
| 2923 - Manufacture non-domestic ventilation | 1 |
| 2940 - Manufacture of machine tools | 1 |
| 2943 - Manufacture of other machine tools not elsewhere classified | 1 |
| 2971 - Manufacture of electric domestic appliances | 1 |
| 3140 - Manufacture of accumulators, batteries etc. | 1 |
| 3320 - Manufacture instruments for measuring etc. | 1 |
| 3340 - Manufacture optical, photographic etc. equipment | 1 |
| 3350 - Manufacture of watches and clocks | 1 |
| 3520 - Manufacture of railway locomotives & stock | 1 |
| 3541 - Manufacture of motorcycles | 1 |
| 3622 - Manufacture of jewellery & related | 1 |
| 3630 - Manufacture of musical instruments | 1 |
| 3640 - Manufacture of sports goods | 1 |
| 3710 - Recycling of metal waste and scrap | 1 |
| 3720 - Recycling non-metal waste & scrap | 1 |
| 4012 - Transmission of electricity | 1 |
| 4013 - Distribution & trade in electricity | 1 |
| 4030 - Steam and hot water supply | 1 |
| 5111 - Agents agricultural & textile raw materials | 1 |
| 5112 - Agents in sale of fuels, ores, etc. | 1 |
| 5115 - Agents in household goods, etc. | 1 |
| 5118 - Agents in particular products | 1 |
| 5135 - Wholesale of tobacco products | 1 |
| 5136 - Wholesale sugar, chocolate etc. | 1 |
| 5138 - Wholesale other food inc fish, etc. | 1 |
| 5154 - Wholesale hardware, plumbing etc. | 1 |
| 5157 - Wholesale of waste and scrap | 1 |
| 5223 - Retail of fish, crustaceans etc. | 1 |
| 5232 - Retail medical & orthopaedic goods | 1 |
| 5233 - Retail cosmetic & toilet articles | 1 |
| 5272 - Repair electrical household goods | 1 |
| 5511 - Hotels & motels | 1 |
| 5521 - Youth hostels and mountain refuges | 1 |
| 6220 - Non-scheduled air transport | 1 |
| 6322 - Other supporting water transport | 1 |
| 6522 - Other credit granting | 1 |
| 6720 - Auxiliary insurance & pension fund | 1 |
| 7122 - Rent water transport equipment | 1 |
| 7140 - Rent personal & household goods | 1 |
| 7230 - Data processing | 1 |
| 7430 - Technical testing and analysis | 1 |
| 7514 - Support services for government | 1 |
| 7524 - Public security, law & order | 1 |
| 8010 - Primary education | 1 |
| 8022 - Technical & vocational secondary | 1 |
| 9002 - Collection and treatment of other waste | 1 |
| 9003 - Sanitation remediation and similar activities | 1 |
| 9131 - Religious organisations | 1 |
| 9213 - Motion picture projection | 1 |
| 9232 - Operation of arts facilities | 1 |
| 9303 - Funeral and related activities | 1 |
| 9304 - Physical well-being activities | 1 |
| 9600 - Undifferentiated goods producing activities of private households for own use | 1 |
The below code creates a list of points (easting and northing) of all the Financial management firms in London:
Because these are points and we know their geometries, we can plot them in space.
Tip
How are the above ‘clusters in space’ different to the previous k-means clustering which ignored space?
Hierarchical Density-Based Spatial Clustering of Applications with Noise
Transform the space according to the density/sparsity
Build the minimum spanning tree of the distance weighted graph
Construct a cluster hierarchy of connected components
Condense the cluster hierarchy based on minimum cluster size
Extract the stable clusters from the condensed tree.
Resources: SciKit-learn docs and dbscan package