Network science, urban laws and scaling
1st milestone: Random networks (RN)
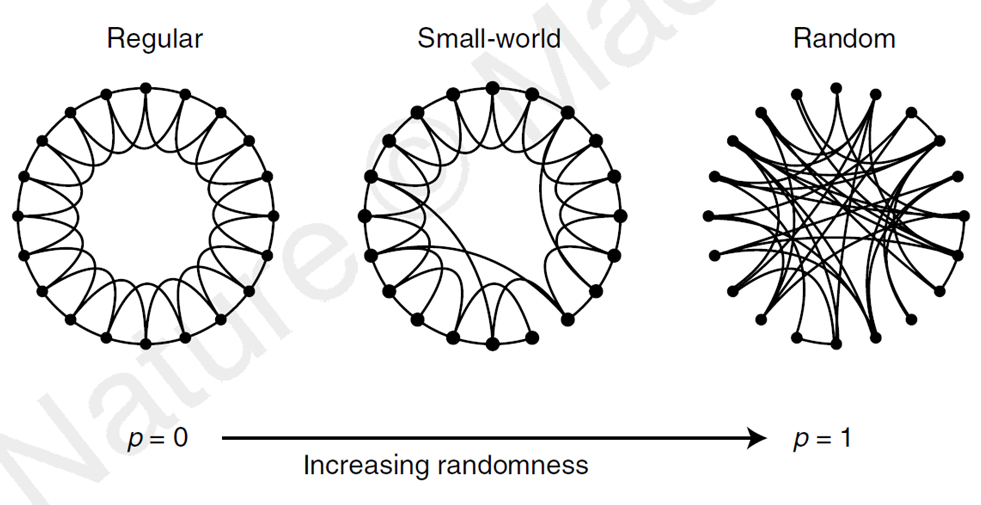
Source: Watts and Strogatz (1998)
1st milestone: Random networks (RN)
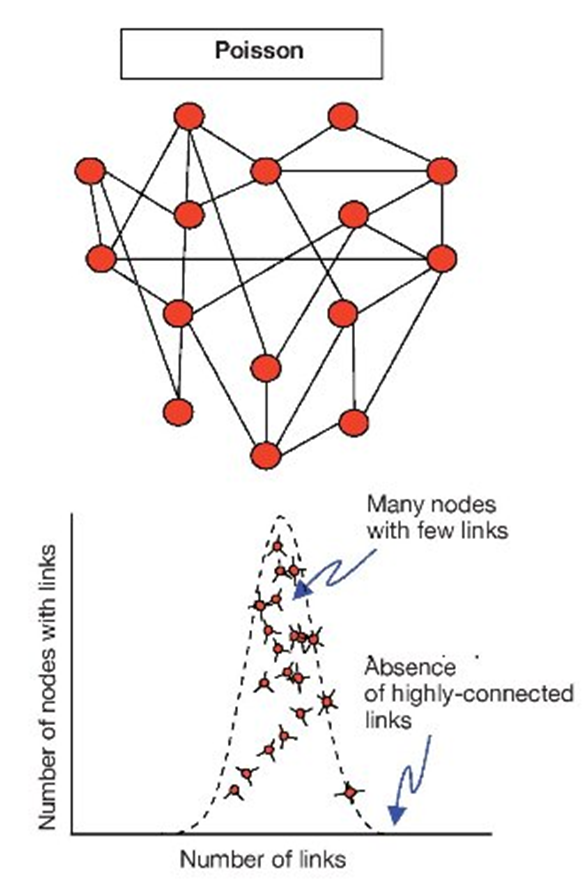
Source: Torres et al. (2009)
2nd milestone: Small-worlds
Source: Watts and Strogatz (1998)
3rd milestone: Scale-free (SF) networks
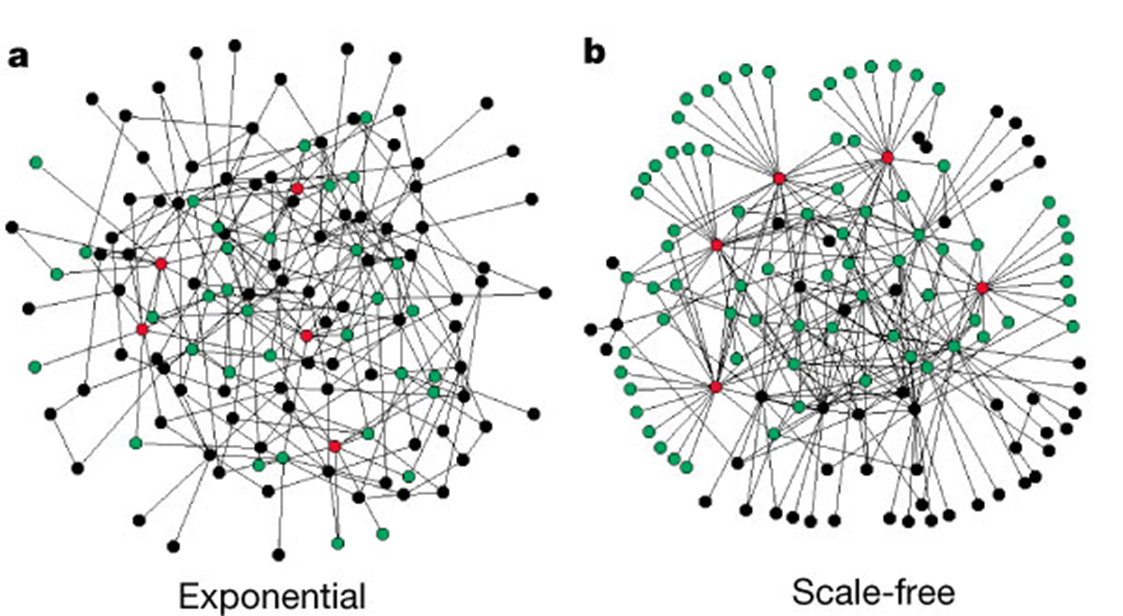
Source: Albert, Jeong, and Barabási (2000)
3rd milestone: Scale-free (SF) networks
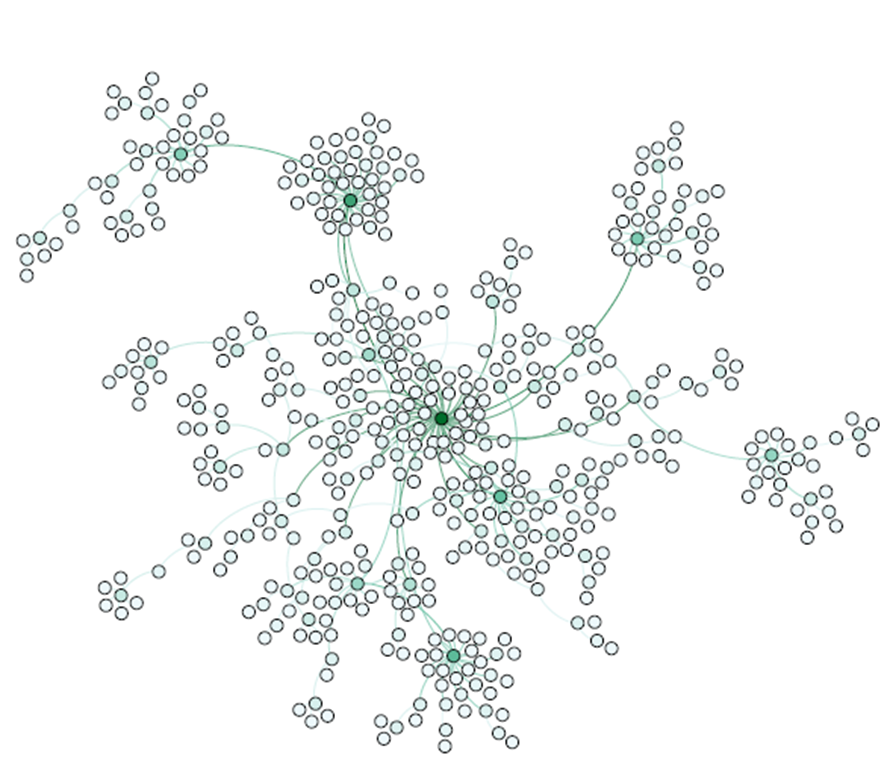
3rd milestone: Scale-free (SF) networks
And finally the power law…
von Thunen’s law
As cities grow in size …
land values decline non-linearly from the centre
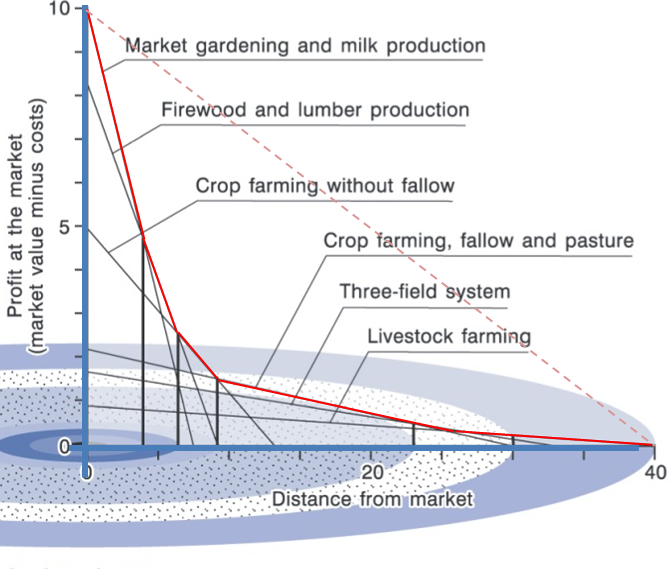
Source: Coe, Kelly, and Yeung (2019)
Law of gravitation / Tobler’s law
As cities grow…
.. interactions between them decline with increasing distance
Newton law of gravitation

Source: I, Dennis Nilsson, CC BY 3.0, https://commons.wikimedia.org/w/index.php?curid=3455682
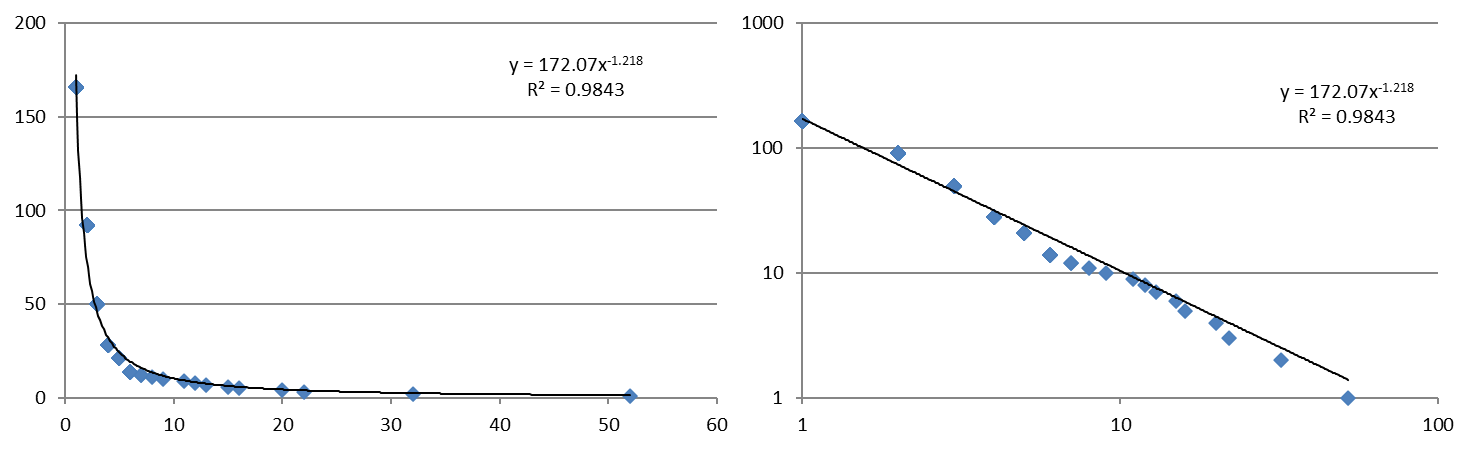
Zipf law
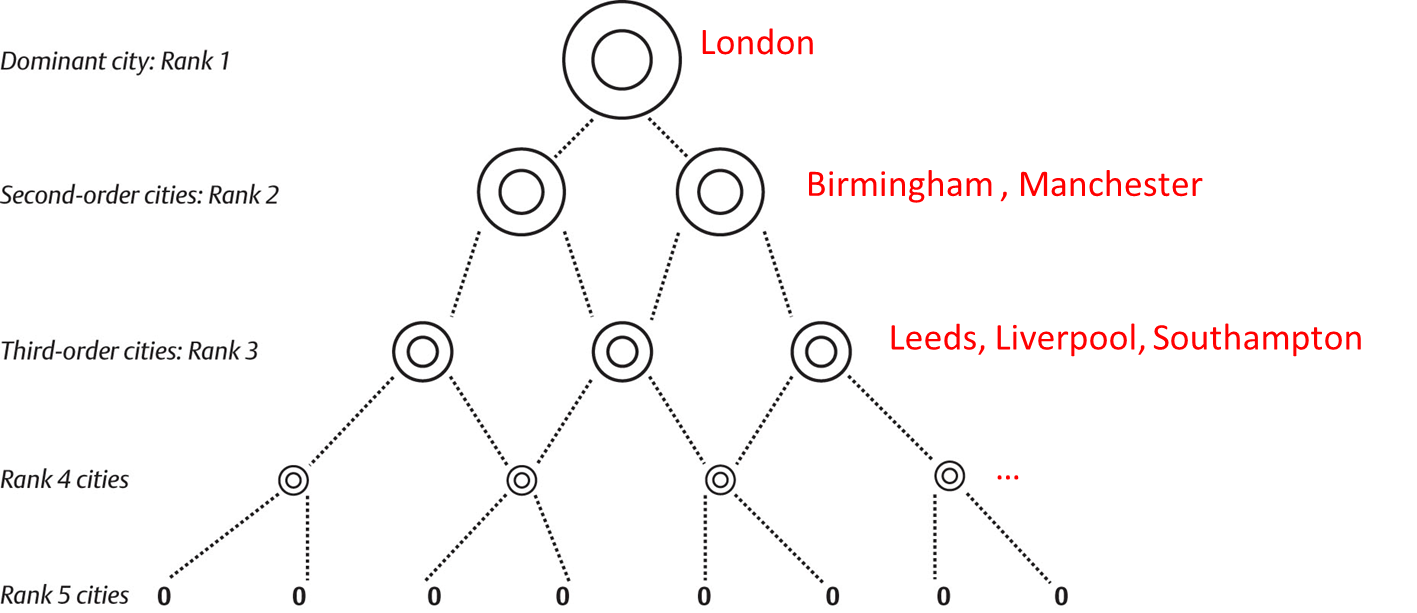
Zipf law
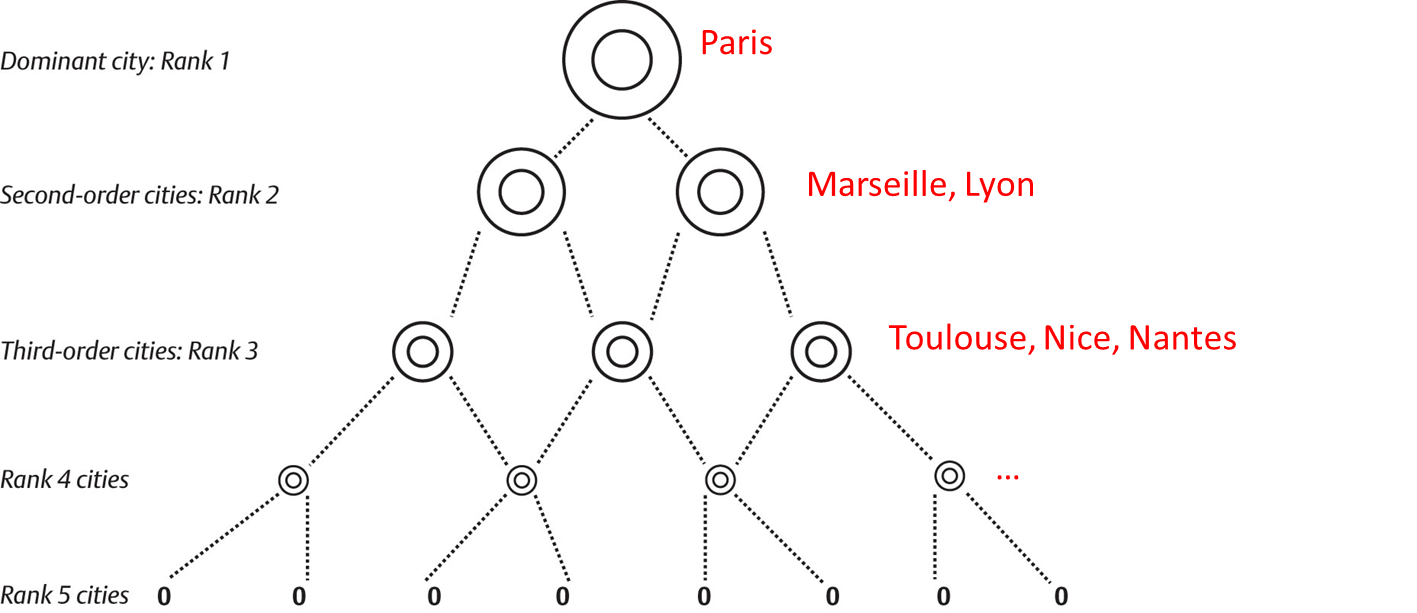
Zipf law
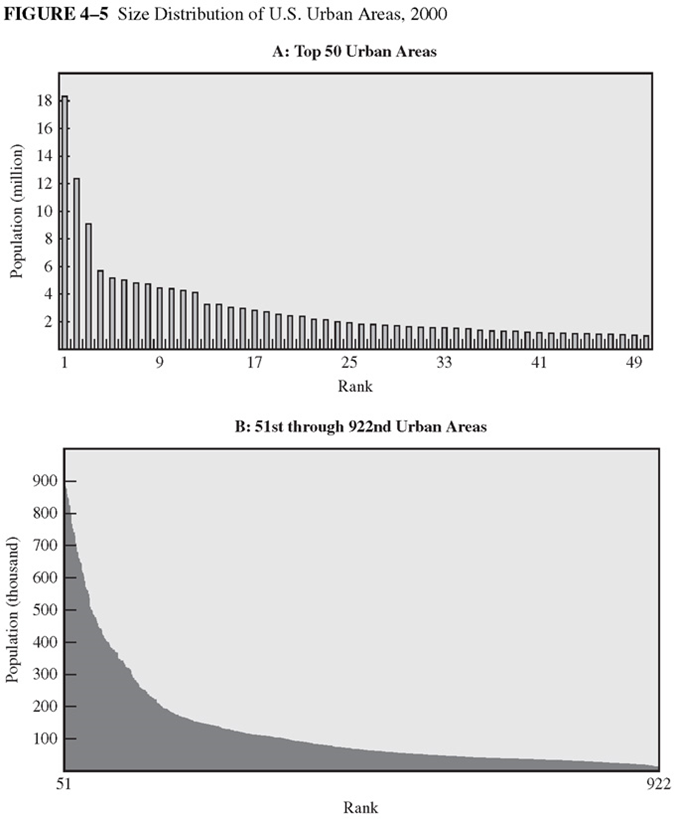
Source: O’sullivan (2012)
Rank size rule
\(pop_i = pop_d r_i^{-a}\)
if \(a=1\): Zipf law
\(pop_i = pop_d / r_i\)
Zipf law
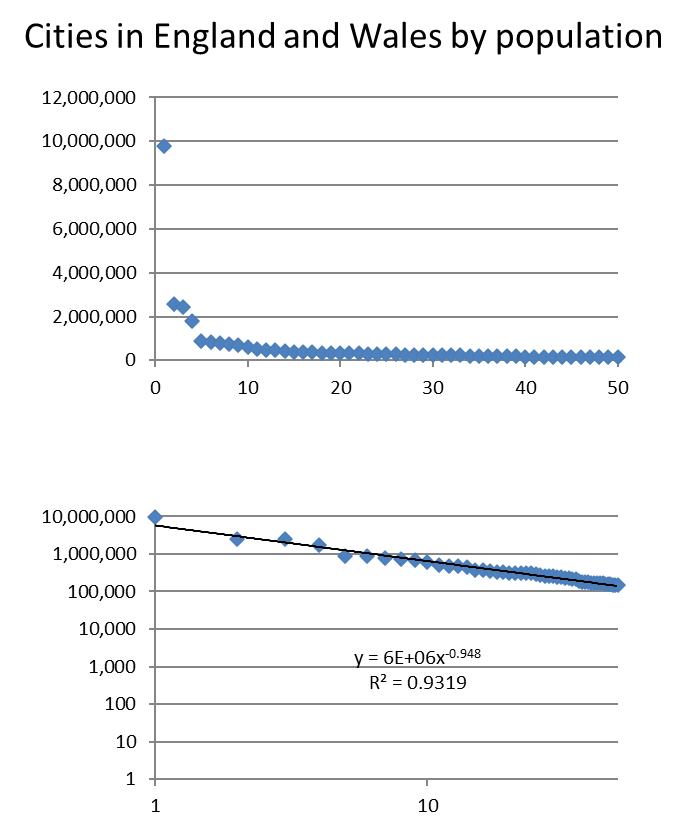
Rank size rule
\(pop_i = pop_d r_i^{-a}\)
if \(a=1\): Zipf law
\(pop_i = pop_d / r_i\)
Bettencourt-West or Marshall’s law
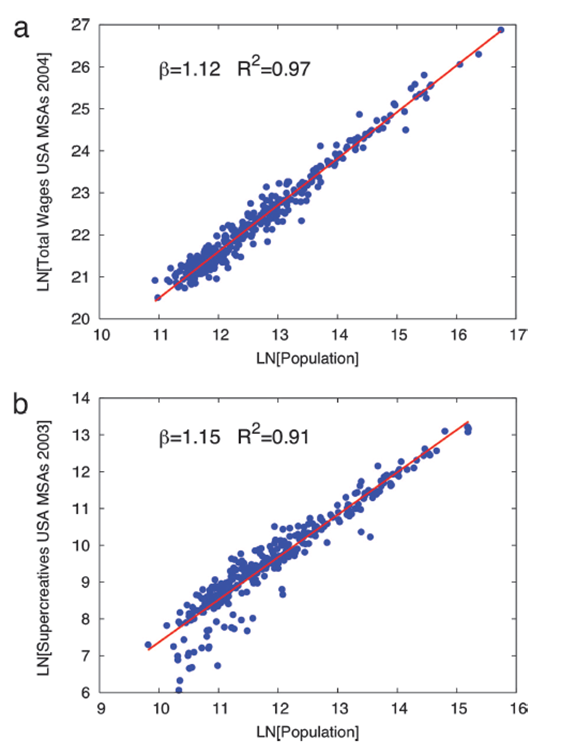
Source: Bettencourt et al. (2007)
Not surprisingly another straight line
Another power law
Bettencourt-West or Marshall’s law
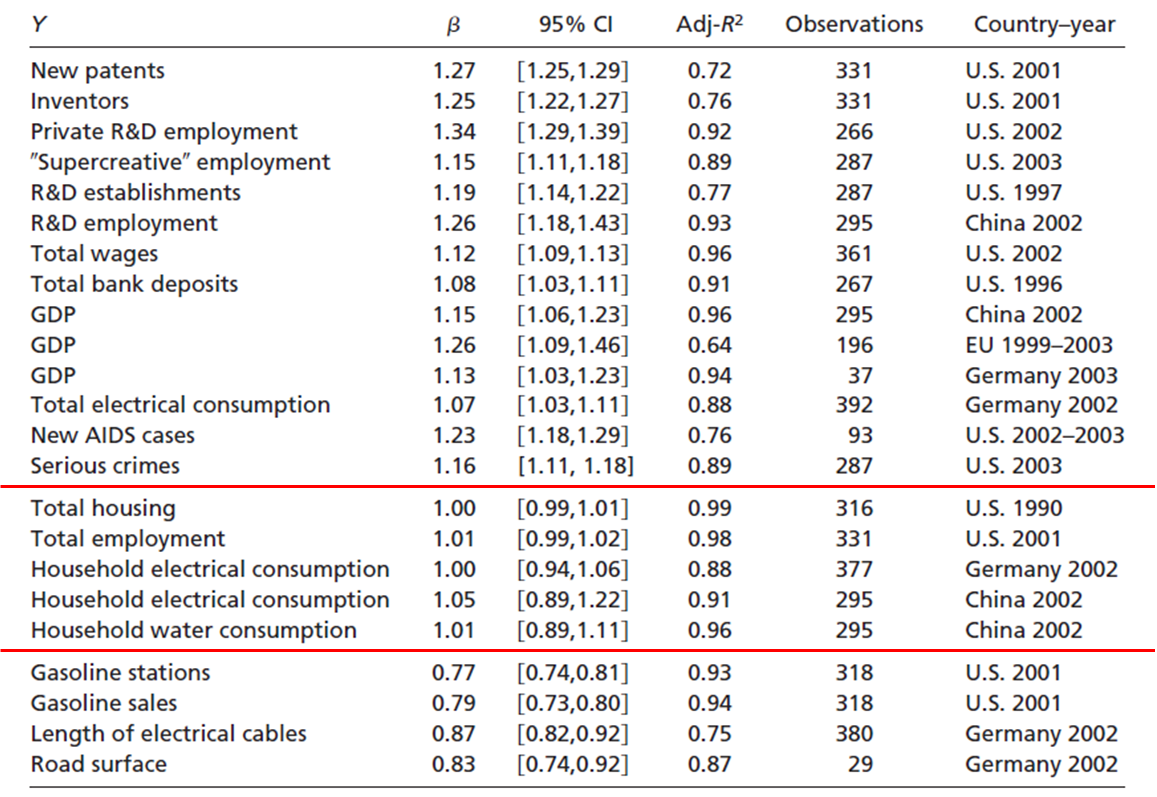
Source: Bettencourt et al. (2007)
Bettencourt-West or Marshall’s law
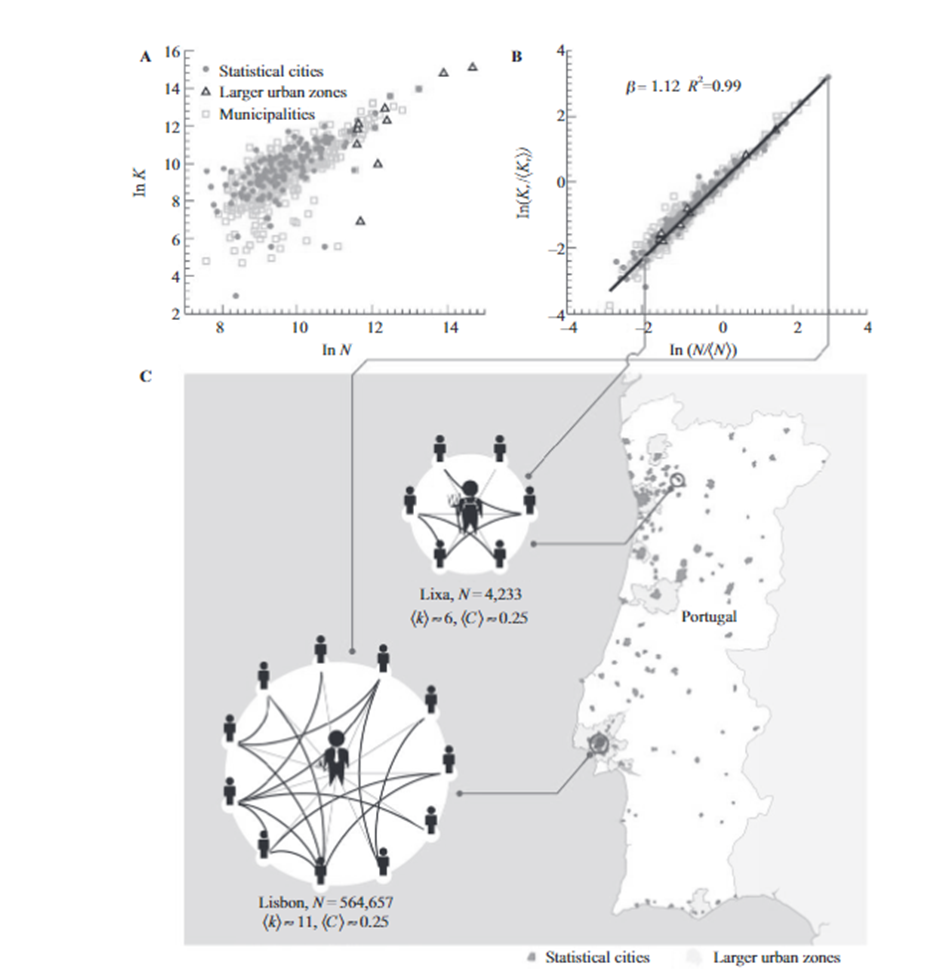
An average urban dweller in the capital, Lisbon, has approximately twice as many reciprocated mobile phone contacts, k, as an average individual in the rural town of Lixa.
Source: Bettencourt (2021)
Bettencourt-West or Marshall’s law
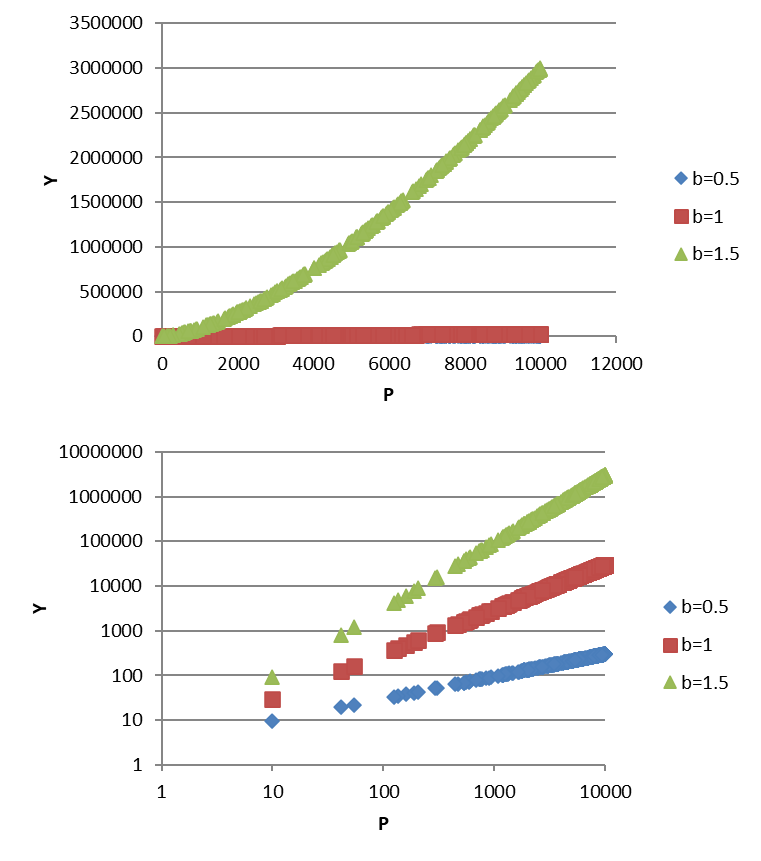
\(Y=3P^b\)
300 random observation
Plotting the results
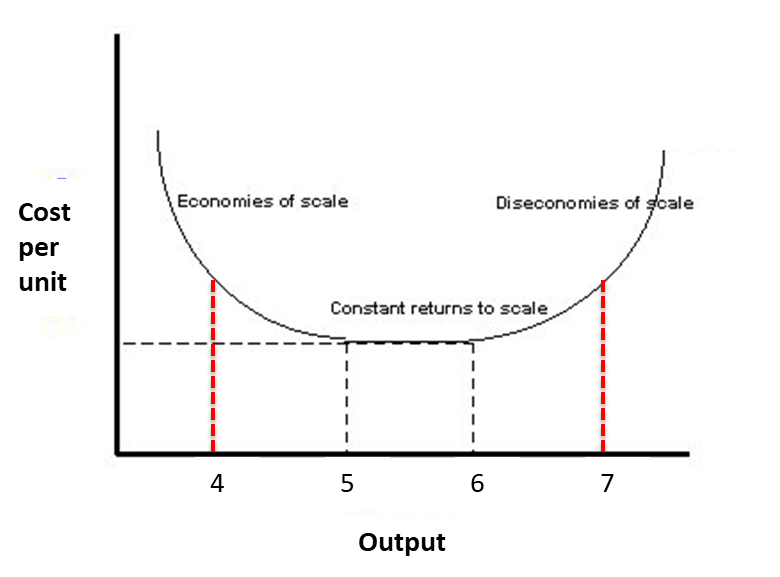
Economies of scale
\(b<1\) decreasing returns to scale
\(b=1\) constant returns
\(b>1\) increasing returns
SF networks, economies of scale?